深入理解Java虚拟机
第一部分:走进Java
不经一番寒彻骨,怎得梅花扑鼻香。
第1章:走进Java
1.1概述
Java能获得如此广泛的认可,除了它拥有一门结构严谨、面向对象的编程语言之外,还有许多不可忽视的优点:
- 它摆脱了硬件平台的束缚,实现了
“一次编写,到处运行”的理想; - 它提供了一种相对安全的
内存管理和访问机制,避免了绝大部分内存泄漏和指针越界问题; - 它实现了
热点代码检测和运行时编译及优化,这使得Java应用能随着运行时间的增长而获得更高的性能; - 它有一套完善的应用程序接口,还有无数来自商业机构和开源社区的第三方类库来帮助用户实现各种各样的功能;
1.2Java技术体系
从广义上讲,Kotlin、Clojure、JRuby、Groovy等运行于Java虚拟机上的编程语言及其相关的程序都属于Java技术体系中的一员。如果仅从传统意义上来看,JCP官方所定义的Java技术体系包括了以下几个组成部分:
- Java程序设计语言
- 各种硬件平台上的Java虚拟机实现
- Class文件格式
- Java类库API
- 来自商业机构和开源社区的第三方Java类库
我们可以把Java程序设计语言、Java虚拟机、Java类库这三部分统称为JDK(Java Development Kit),JDK是用于支持Java程序开发的最小环境,本书中为行文方便,在不产生歧义的地方常以JDK来代指整个Java技术体系。可以把Java类库API中的Java SE API子集和Java虚拟机这两部分统称为JRE(Java Runtime Environment),JRE是支持Java程序运行的标准环境。
1.3Java虚拟机家族
1.3.1虚拟机始祖-Classic/Exact VM
1996年1月23日,Sun发布JDK 1.0,Java语言首次拥有了商用的正式运行环境,这个JDK中所带的虚拟机就是Classic VM。这款虚拟机只能使用纯解释器方式来执行Java代码,如果要使用即时编译器那就必须进行外挂,但是假如外挂了即时编译器的话,即时编译器就会完全接管虚拟机的执行系统,解释器便不能再工作了。在JDK 1.2及之前,用户用Classic虚拟机执行java-version命令,将会看到类似下面这行的输出:
1 | java version "1.2.2" |
其中的“sunwjit”(Sun Workshop JIT)就是Sun提供的外挂编译器。由于解释器和编译器不能配合工作,这就意味着如果要使用编译执行,编译器就不得不对每一个方法、每一行代码都进行编译,而无论它们执行的频率是否具有编译的价值。基于程序响应时间的压力,这些编译器根本不敢应用编译耗时稍高的优化技术,因此这个阶段的虚拟机虽然用了即时编译器输出本地代码,其执行效率也和传统的C/C++程序有很大差距,“Java语言很慢”的印象就是在这阶段开始在用户心中树立起来的。
Sun的虚拟机团队努力去解决Classic虚拟机所面临的各种问题,提升运行效率,在JDK 1.2时,曾在Solaris平台上发布过一款名为Exact VM的虚拟机,它的编译执行系统已经具备现代高性能虚拟机雏形,如热点探测、两级即时编译器、编译器与解释器混合工作模式等。
Exact VM因它使用准确式内存管理(Exact Memory Management)而得名。准确式内存管理是指虚拟机可以知道内存中某个位置的数据具体是什么类型。譬如内存中有一个32bit的整数123456,虚拟机将有能力分辨出它到底是一个指向了123456的内存地址的引用类型还是一个数值为123456的整数,准确分辨出哪些内存是引用类型,这也是在垃圾收集时准确判断堆上的数据是否还可能被使用的前提。由于使用了准确式内存管理,Exact VM可以抛弃掉以前Classic VM基于句柄(Handle)的对象查找方式(原因是垃圾收集后对象将可能会被移动位置,如果地址为123456的对象移动到654321,在没有明确信息表明内存中哪些数据是引用类型的前提下,那虚拟机肯定是不敢把内存中所有为123456的值改成654321的,所以要使用句柄来保持引用值的稳定),这样每次定位对象都少了一次间接查找的开销,显著提升执行性能。
1.3.2武林盟主-HotSpot VM
HotSpot既继承了Sun之前两款商用虚拟机的优点(如前面提到的准确式内存管理),也有许多自己新的技术优势,如它名称中的HotSpot指的就是它的热点代码探测技术(这里的描写带有“历史由胜利者书写”的味道,其实HotSpot与Exact虚拟机基本上是同时期的独立产品,HotSpot出现得还稍早一些,一开始HotSpot就是基于准确式内存管理的,而Exact VM之中也有与HotSpot几乎一样的热点探测技术,为了Exact VM和HotSpot VM哪个该成为Sun主要支持的虚拟机,在Sun公司内部还争吵过一场,HotSpot击败Exact并不能算技术上的胜利),HotSpot虚拟机的热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知即时编译器以方法为单位进行编译。如果一个方法被频繁调用,或方法中有效循环次数很多,将会分别触发标准即时编译和栈上替换编译(On-Stack Replacement,OSR)行为。
[!NOTE]
通过编译器与解释器恰当地协同工作,可以在最优化的程序响应时间与最佳执行性能中取得平衡,而且无须等待本地代码输出才能执行程序,即时编译的时间压力也相对减小,这样有助于引入更复杂的代码优化技术,输出质量更高的本地代码。
得益于Sun/OracleJDK在Java应用中的统治地位,HotSpot理所当然地成为全世界使用最广泛的Java虚拟机,是虚拟机家族中毫无争议的“武林盟主”。
1.3.3天下第二-JRockit/J9 VM
JRockit虚拟机曾经号称是“世界上速度最快的Java虚拟机”(广告词,IBM J9虚拟机也这样宣传过,总体上三大虚拟机的性能是交替上升的),它是BEA在2002年从Appeal Virtual Machines公司收购获得的Java虚拟机。BEA将其发展为一款专门为服务器硬件和服务端应用场景高度优化的虚拟机,由于专注于服务端应用,它可以不太关注于程序启动速度,因此JRockit内部不包含解释器实现,全部代码都靠即时编译器编译后执行。除此之外,JRockit的垃圾收集器和Java Mission Control故障处理套件等部分的实现,在当时众多的Java虚拟机中也处于领先水平。
J9虚拟机最初是由IBM Ottawa实验室的一个SmallTalk虚拟机项目扩展而来,当时这个虚拟机有一个Bug是因为8KB常量值定义错误引起,工程师们花了很长时间终于发现并解决了这个错误,此后这个版本的虚拟机就被称为K8,后来由其扩展而来、支持Java语言的虚拟机就被命名为J9。与BEA JRockit只专注于服务端应用不同,IBM J9虚拟机的市场定位与HotSpot比较接近,它是一款在设计上全面考虑服务端、桌面应用,再到嵌入式的多用途虚拟机,开发J9的目的是作为IBM公司各种Java产品的执行平台,在和IBM产品(如IBM WebSphere等)搭配以及在IBM AIX和z/OS这些平台上部署Java应用。
IBM J9直至今天仍旧非常活跃,IBM J9虚拟机的职责分离与模块化做得比HotSpot更优秀,由J9虚拟机中抽象封装出来的核心组件库(包括垃圾收集器、即时编译器、诊断监控子系统等)就单独构成了IBM OMR项目,可以在其他语言平台如Ruby、Python中快速组装成相应的功能。从2016年起,IBM逐步将OMR项目和J9虚拟机进行开源,完全开源后便将它们捐献给了Eclipse基金会管理,并重新命名为Eclipse OMR和OpenJ9。如果为了学习虚拟机技术而去阅读源码,更加模块化的OpenJ9代码其实是比HotSpot更好的选择。如果为了使用Java虚拟机时多一种选择,那可以通过AdoptOpenJDK来获得采用OpenJ9搭配上OpenJDK其他类库组成的完整JDK。
1.3.4软硬合璧-Azul VM
我们平时所提及的“高性能Java虚拟机”一般是指HotSpot、JRockit、J9这类在通用硬件平台上运行的商用虚拟机,但其实还有一类与特定硬件平台绑定、软硬件配合工作的专有虚拟机,往往能够实现更高的执行性能,或提供某些特殊的功能特性。Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于Azul Systems公司的专有硬件Vega系统上的Java虚拟机,每个Azul VM实例都可以管理至少数十个CPU和数百GB的内存的硬件资源,并提供在巨大内存范围内停顿时间可控的垃圾收集器(即业内赫赫有名的PGC和C4收集器),为专有硬件优化的线程调度等优秀特性。2010年起,Azul公司的重心逐渐开始从硬件转向软件,发布了自己的Zing虚拟机,可以在通用x86平台上提供接近于Vega系统的性能和一致的功能特性。
[!WARNING]
随着虚拟机技术的不断发展,Java虚拟机变得越来越强大的同时也越来越复杂,要推动在专有硬件上的Java虚拟机升级发展,难以直接借助开源社区的力量,往往需要耗费更高昂的成本,在商业上的缺陷使得专有虚拟机逐渐没落,Azul Systems公司最终也放弃了Vega产品线,把全部精力投入到Zing和Zulu产品线中。
Zing虚拟机是一个从HotSpot某旧版代码分支基础上独立出来重新开发的高性能Java虚拟机,它可以运行在通用的Linux/x86-64平台上。Azul公司为它编写了新的垃圾收集器,也修改了HotSpot内的许多实现细节,在要求低延迟、快速预热等场景中,Zing VM都要比HotSpot表现得更好。Zing的PGC、C4收集器可以轻易支持TB级别的Java堆内存,而且保证暂停时间仍然可以维持在不超过10毫秒的范围里,HotSpot要一直到JDK 11和JDK 12的ZGC及Shenandoah收集器才达到了相同的目标,而且目前效果仍然远不如C4。Zing的ReadyNow功能可以利用之前运行时收集到的性能监控数据,引导虚拟机在启动后快速达到稳定的高性能水平,减少启动后从解释执行到即时编译的等待时间。Zing自带的ZVision/ZVRobot功能可以方便用户监控Java虚拟机的运行状态,从找出代码热点到对象分配监控、锁竞争监控等。Zing能让普通用户无须了解垃圾收集等底层调优,就可以使得Java应用享有低延迟、快速预热、易于监控的功能,这是Zing的核心价值和卖点,很多Java应用都可以通过长期努力在应用、框架层面优化来提升性能,但使用Zing的话就可以把精力更多集中在业务方面。
1.4展望Java技术未来
1.4.1无语言倾向
2018年4月,Oracle Labs新公开了一项黑科技:Graal VM,从它的口号“Run Programs Faster Anywhere”就能感觉到一颗蓬勃的野心,这句话显然是与1995年Java刚诞生时的“WriteOnce,Run Anywhere”在遥相呼应。

Graal VM被官方称为“Universal VM”和“Polyglot VM”,这是一个在HotSpot虚拟机基础上增强而成的跨语言全栈虚拟机,可以作为“任何语言”的运行平台使用,这里“任何语言”包括了Java、Scala、Groovy、Kotlin等基于Java虚拟机之上的语言,还包括了C、C++、Rust等基于LLVM的语言,同时支持其他像JavaScript、Ruby、Python和R语言等。Graal VM可以无额外开销地混合使用这些编程语言,支持不同语言中混用对方的接口和对象,也能够支持这些语言使用已经编写好的本地库文件。
Graal VM的基本工作原理是将这些语言的源代码(例如JavaScript)或源代码编译后的中间格式(例如LLVM字节码)通过解释器转换为能被Graal VM接受的中间表示(Intermediate Representation,IR),譬如设计一个解释器专门对LLVM输出的字节码进行转换来支持C和C++语言,这个过程称为程序特化(Specialized,也常被称为Partial Evaluation)。Graal VM提供了Truffle工具集来快速构建面向一种新语言的解释器,并用它构建了一个称为Sulong的高性能LLVM字节码解释器。
1.4.2新一代即时编译器
对需要长时间运行的应用来说,由于经过充分预热,热点代码会被HotSpot的探测机制准确定位捕获,并将其编译为物理硬件可直接执行的机器码,在这类应用中Java的运行效率很大程度上取决于即时编译器所输出的代码质量。
HotSpot虚拟机中含有两个即时编译器,分别是编译耗时短但输出代码优化程度较低的客户端编译器(简称为C1)以及编译耗时长但输出代码优化质量也更高的服务端编译器(简称为C2),通常它们会在分层编译机制下与解释器互相配合来共同构成HotSpot虚拟机的执行子系统。
自JDK 10起,HotSpot中又加入了一个全新的即时编译器:Graal编译器,看名字就可以联想到它是来自于前一节提到的Graal VM。Graal编译器是以C2编译器替代者的身份登场的。C2的历史已经非常长了,可以追溯到Cliff Click大神读博士期间的作品,这个由C++写成的编译器尽管目前依然效果拔群,但已经复杂到连Cliff Click本人都不愿意继续维护的程度。而Graal编译器本身就是由Java语言写成,实现时又刻意与C2采用了同一种名为“Sea-of-Nodes”的高级中间表示(High IR)形式,使其能够更容易借鉴C2的优点。
Graal编译器比C2编译器晚了足足二十年面世,有着极其充沛的后发优势,在保持输出相近质量的编译代码的同时,开发效率和扩展性上都要显著优于C2编译器,这决定了C2编译器中优秀的代码优化技术可以轻易地移植到Graal编译器上,但是反过来Graal编译器中行之有效的优化在C2编译器里实现起来则异常艰难。这种情况下,Graal的编译效果短短几年间迅速追平了C2,甚至某些测试项中开始逐渐反超C2编译器。Graal能够做比C2更加复杂的优化,如“部分逃逸分析”(PartialEscape Analysis),也拥有比C2更容易使用激进预测性优化(Aggressive Speculative Optimization)的策略,支持自定义的预测性假设等。
1.4.3向Native迈进
对不需要长时间运行的,或者小型化的应用而言,Java(而不是指Java ME)天生就带有一些劣势,这里并不只是指跑个HelloWorld也需要百多兆的JRE之类的问题,更重要的是指近几年在从大型单体应用架构向小型微服务应用架构发展的技术潮流下,Java表现出来的不适应。
在微服务架构的视角下,应用拆分后,单个微服务很可能就不再需要面对数十、数百GB乃至TB的内存,有了高可用的服务集群,也无须追求单个服务要7×24小时不间断地运行,它们随时可以中断和更新;但相应地,Java的启动时间相对较长,需要预热才能达到最高性能等特点就显得相悖于这样的应用场景。在无服务架构中,矛盾则可能会更加突出,比起服务,一个函数的规模通常会更小,执行时间会更短,当前最热门的无服务运行环境AWS Lambda所允许的最长运行时间仅有15分钟。
一直把软件服务作为重点领域的Java自然不可能对此视而不见,在最新的几个JDK版本的功能清单中,已经陆续推出了跨进程的、可以面向用户程序的类型信息共享(Application Class Data Sharing,AppCDS,允许把加载解析后的类型信息缓存起来,从而提升下次启动速度,原本CDS只支持Java标准库,在JDK 10时的AppCDS开始支持用户的程序代码)、无操作的垃圾收集器(Epsilon,只做内存分配而不做回收的收集器,对于运行完就退出的应用十分合适)等改善措施。而酝酿中的一个更彻底的解决方案,是逐步开始对提前编译(Ahead of Time Compilation,AOT)提供支持。
提前编译是相对于即时编译的概念,提前编译能带来的最大好处是Java虚拟机加载这些已经预编译成二进制库之后就能够直接调用,而无须再等待即时编译器在运行时将其编译成二进制机器码。理论上,提前编译可以减少即时编译带来的预热时间,减少Java应用长期给人带来的“第一次运行慢”的不良体验,可以放心地进行很多全程序的分析行为,可以使用时间压力更大的优化措施。
但是提前编译的坏处也很明显,它破坏了Java“一次编写,到处运行”的承诺,必须为每个不同的硬件、操作系统去编译对应的发行包;也显著降低了Java链接过程的动态性,必须要求加载的代码在编译期就是全部已知的,而不能在运行期才确定,否则就只能舍弃掉已经提前编译好的版本,退回到原来的即时编译执行状态。
早在JDK 9时期,Java就提供了实验性的Jaotc命令来进行提前编译,不过多数人试用过后都颇感失望,大家原本期望的是类似于Excelsior JET那样的编译过后能生成本地代码完全脱离Java虚拟机运行的解决方案,但Jaotc其实仅仅是代替即时编译的一部分作用而已,仍需要运行于HotSpot之上。
[!NOTE]
补充内容:
直到Substrate VM出现,才算是满足了人们心中对Java提前编译的全部期待。Substrate VM是在Graal VM 0.20版本里新出现的一个极小型的运行时环境,包括了独立的异常处理、同步调度、线程管理、内存管理(垃圾收集)和JNI访问等组件,
目标是代替HotSpot用来支持提前编译后的程序执行。它还包含了一个本地镜像的构造器(Native Image Generator),用于为用户程序建立基于Substrate VM的本地运行时镜像。这个构造器采用指针分析(Points-To Analysis)技术,从用户提供的程序入口出发,搜索所有可达的代码。在搜索的同时,它还将执行初始化代码,并在最终生成可执行文件时,将已初始化的堆保存至一个堆快照之中。这样一来,Substrate VM就可以直接从目标程序开始运行,而无须重复进行Java虚拟机的初始化过程。但相应地,原理上也决定了Substrate VM必须要求目标程序是完全封闭的,即不能动态加载其他编译器不可知的代码和类库。基于这个假设,Substrate VM才能探索整个编译空间,并通过静态分析推算出所有虚方法调用的目标方法。
Substrate VM带来的好处是能显著降低内存占用及启动时间,由于HotSpot本身就会有一定的内存消耗(通常约几十MB),这对最低也从几GB内存起步的大型单体应用来说并不算什么,但在微服务下就是一笔不可忽视的成本。根据Oracle官方给出的测试数据,运行在Substrate VM上的小规模应用,其内存占用和启动时间与运行在HotSpot上相比有5倍到50倍的下降。
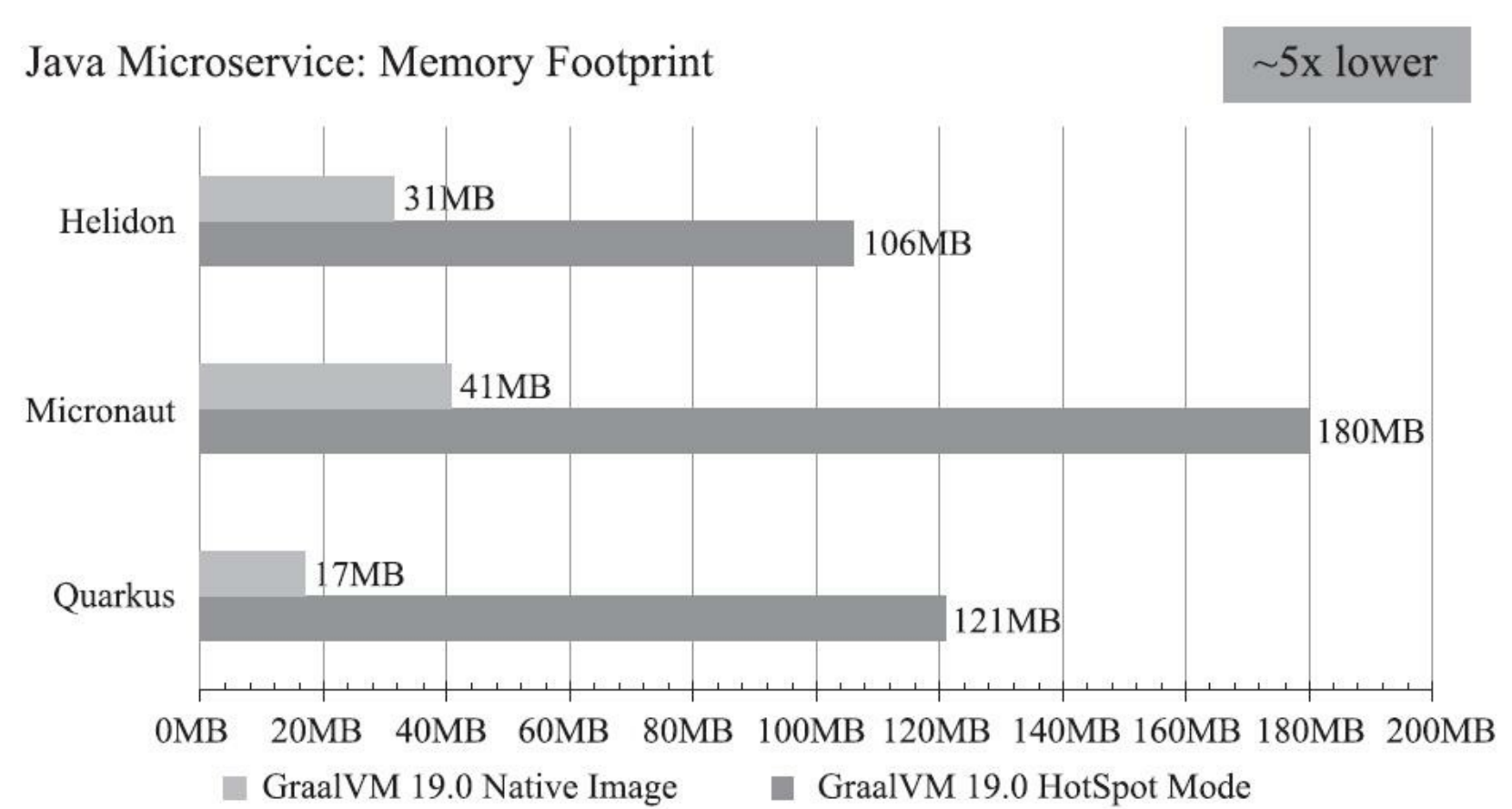
Substrate VM补全了Graal VM“Run Programs Faster Anywhere”愿景蓝图里的最后一块拼图,让Graal VM支持其他语言时不会有重量级的运行负担。譬如运行JavaScript代码,Node.js的V8引擎执行效率非常高,但即使是最简单的HelloWorld,它也要使用约20MB的内存,而运行在Substrate VM上的Graal.js,跑一个HelloWorld则只需要4.2MB内存,且运行速度与V8持平。Substrate VM的轻量特性,使得它十分适合嵌入其他系统,譬如Oracle自家的数据库就已经开始使用这种方式支持用不同的语言代替PL/SQL来编写存储过程。
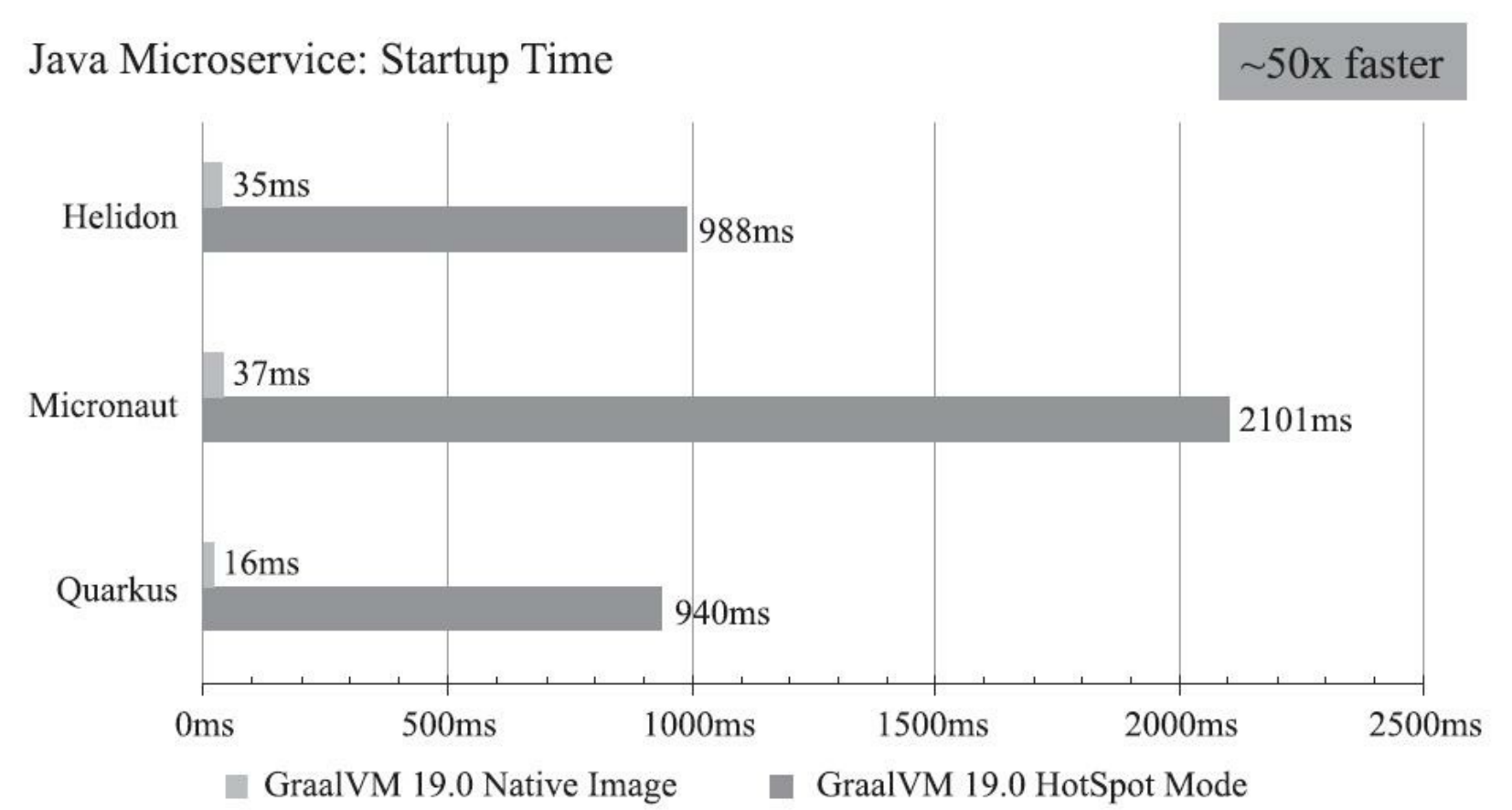
由于AOT编译没有运行时的监控信息,很多由运行信息统计进行向导的优化措施不能使用,所以尽管没有编译时间的压力,效果也不一定就比JIT更好。
1.4.4语言语法持续增强
笔者将语言的功能特性和语法放到最后来讲,因为它是相对最不重要的改进点,毕竟连JavaScript这种“反人类”的语法都能获得如此巨大的成功,而比Java语法先进优雅得多的挑战者C#现在已经“江湖日下”,成了末路英雄。
但一门语言的功能、语法又是影响语言生产力和效率的重要因素,很多语言特性和语法糖不论有没有,程序也照样能写,但即使只是可有可无的语法糖,也是直接影响语言使用者的幸福感程度的关键指标。JDK 7的Coins项目结束以后,Java社区又创建了另外一个新的语言特性改进项目Amber,JDK10至13里面提供的新语法改进基本都来自于这个项目,譬如:
- JEP 286:Local-Variable Type Inference,在JDK 10中提供,本地类型变量推断。
- JEP 323:Local-Variable Syntax for Lambda Parameters,在JDK 11中提供,JEP 286的加强,使它可以用在Lambda中。
- JEP 325:Switch Expressions,在JDK 13中提供,实现switch语句的表达式支持。
- JEP 335:Text Blocks,在JDK 13中提供,支持文本块功能,可以节省拼接HTML、SQL等场景里大量的“+”操作。
- JEP 305:Pattern Matching for instanceof,用instanceof判断过的类型,在条件分支里面可以不需要做强类型转换就能直接使用。
除语法糖以外,语言的功能也在持续改进之中,以下几个项目是目前比较明确的,也是受到较多关注的功能改进计划:
- Project Loom:现在的Java做并发处理的最小调度单位是线程,Java线程的调度是直接由操作系统内核提供的,会有核心态、用户态的切换开销。而很多其他语言都提供了
更加轻量级的、由软件自身进行调度的用户线程(曾经非常早期的Java也有绿色线程),譬如Golang的Groutine、D语言的Fiber等。Loom项目就准备提供一套与目前Thread类API非常接近的Fiber实现。 - Project Valhalla:提供值类型和基本类型的泛型支持,并提供明确的不可变类型和非引用类型的声明。不可变类型在并发编程中能带来很多好处,没有数据竞争风险带来了更好的性能。一些语言(如Scala)就有明确的不可变类型声明,而Java中只能
在定义类时将全部字段声明为final来间接实现。基本类型的泛型支持是指在泛型中引用基本数据类型不需要自动装箱和拆箱,避免性能损耗。 - Project Panama:目的是
消弭Java虚拟机与本地代码之间的界线。现在Java代码可以通过JNI来调用本地代码,这点在与硬件交互频繁的场合尤其常用(譬如Android)。但是JNI的调用方式充其量只能说是达到能用的标准而已,使用起来仍相当烦琐,频繁执行的性能开销也非常高昂,Panama项目的目标就是提供更好的方式让Java代码与本地代码进行调用和传输数据。
随着Java每半年更新一次的节奏,新版本的Java中会出现越来越多其他语言里已有的优秀特性,相信博采众长的Java,还能继续保持现在的勃勃生机相当长时间。
第二部分:自动内存管理
千淘万漉虽辛苦,吹尽狂沙始到金。
第2章:Java内存区域与内存溢出异常
2.1概述
对于从事C、C++程序开发的开发人员来说,在内存管理领域,他们既是拥有最高权力的“皇帝”,又是从事最基础工作的劳动人民——既拥有每一个对象的“所有权”,又担负着每一个对象生命从开始到终结的维护责任。
对于Java程序员来说,在虚拟机自动内存管理机制的帮助下,不再需要为每一个new操作去写配对的delete/free代码,不容易出现内存泄漏和内存溢出问题,看起来由虚拟机管理内存一切都很美好。不过,也正是因为Java程序员把控制内存的权力交给了Java虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那排查错误、修正问题将会成为一项异常艰难的工作。
2.2运行时数据区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销毁。根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域:
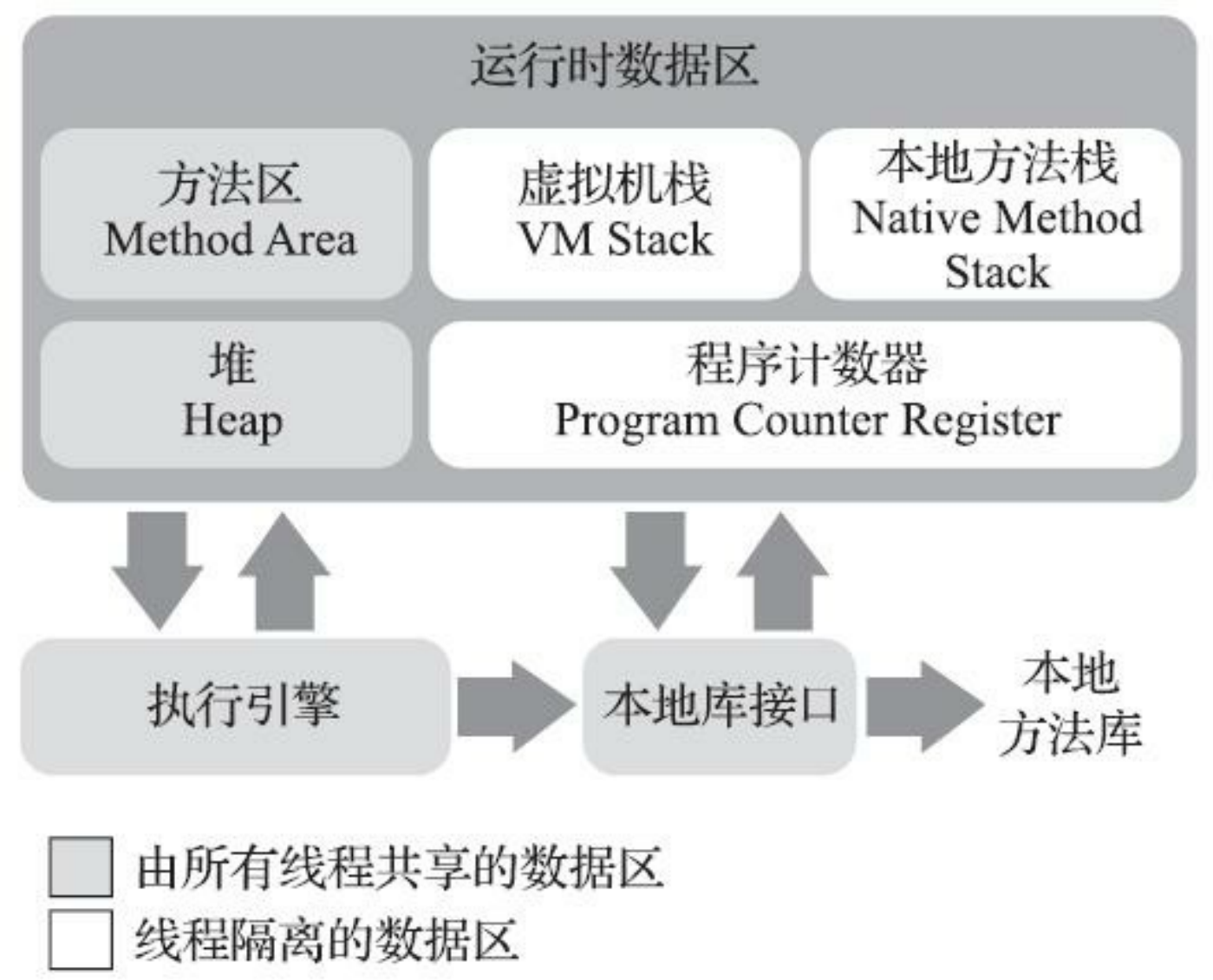
2.2.1程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在Java虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是本地(Native)方法,这个计数器值则应为空(Undefined)。此内存区域是唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
2.2.2Java虚拟机栈
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stack)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种Java虚拟机基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
这些数据类型在局部变量表中的存储空间以局部变量槽(Slot)来表示,其中64位长度的long和double类型的数据会占用两个变量槽,其余的数据类型只占用一个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。请读者注意,这里说的“大小”是指变量槽的数量,虚拟机真正使用多大的内存空间(譬如按照1个变量槽占用32个比特、64个比特,或者更多)来实现一个变量槽,这是完全由具体的虚拟机实现自行决定的事情。
在《Java虚拟机规范》中,对这个内存区域规定了两类异常状况:
- 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出
StackOverflowError异常; - 如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出
OutOfMemoryError异常。
2.2.3本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
《Java虚拟机规范》对本地方法栈中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它,甚至有的Java虚拟机(譬如Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
2.2.4Java堆
如果从分配内存的角度看,所有线程共享的Java堆中可以划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率。不过无论从什么角度,无论如何划分,都不会改变Java堆中存储内容的共性,无论是哪个区域,存储的都只能是对象的实例,将Java堆细分的目的只是为了更好地回收内存,或者更快地分配内存。
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的,这点就像我们用磁盘空间去存储文件一样,并不要求每个文件都连续存放。
[!NOTE]
但对于
大对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
2.2.5方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区分开来。
说到方法区,不得不提一下“永久代”这个概念,尤其是在JDK 8以前,许多Java程序员都习惯在HotSpot虚拟机上开发、部署程序,很多人都更愿意把方法区称呼为“永久代”(Permanent Generation),或将两者混为一谈。本质上这两者并不是等价的,因为仅仅是当时的HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得HotSpot的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。但是对于其他虚拟机实现,譬如BEA JRockit、IBM J9等来说,是不存在永久代的概念的。原则上如何实现方法区属于虚拟机实现细节,不受《Java虚拟机规范》管束,并不要求统一。但现在回头来看,当年使用永久代来实现方法区的决定并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法(例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。当Oracle收购BEA获得了JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了,到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Metaspace)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。
《Java虚拟机规范》对方法区的约束是非常宽松的,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,甚至还可以选择不实现垃圾收集。相对而言,垃圾收集行为在这个区域的确是比较少出现的,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。这区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收效果比较难令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收有时又确实是必要的。以前Sun公司的Bug列表中,曾出现过的若干个严重的Bug就是由于低版本的HotSpot虚拟机对此区域未完全回收而导致内存泄漏。
2.2.6运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
Java虚拟机对于Class文件每一部分(自然也包括常量池)的格式都有严格规定,如每一个字节用于存储哪种数据都必须符合规范上的要求才会被虚拟机认可、加载和执行,但对于运行时常量池,《Java虚拟机规范》并没有做任何细节的要求,不同提供商实现的虚拟机可以按照自己的需要来实现这个内存区域,不过一般来说,除了保存Class文件中描述的符号引用外,还会把由符号引用翻译出来的直接引用也存储在运行时常量池中。
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是说,并非预置入Class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可以将新的常量放入池中,这种特性被开发人员利用得比较多的便是String类的intern()方法。
2.2.7直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现,所以我们放到这里一起讲解。
在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存(包括物理内存、SWAP分区或者分页文件)大小以及处理器寻址空间的限制,一般服务器管理员配置虚拟机参数时,会根据实际内存去设置-Xmx等参数信息,但经常忽略掉直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现OutOfMemoryError异常。
2.3HotSpot虚拟机对象探秘
基于实用优先的原则,笔者以最常用的虚拟机HotSpot和最常用的内存区域Java堆为例,深入探讨一下HotSpot虚拟机在Java堆中对象分配、布局和访问的全过程。