Redis原理之数据结构
1.动态字符串SDS
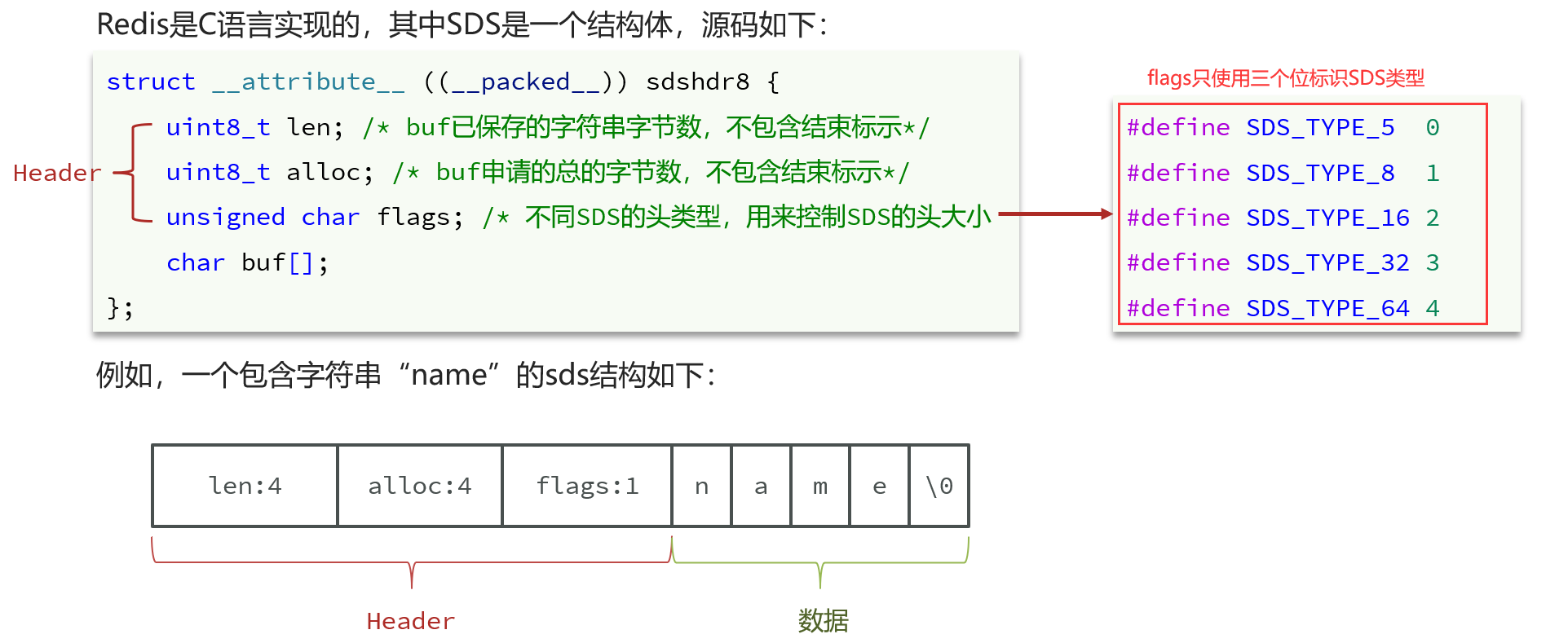
1.1SDS由来

1.2SDS结构
1.3SDS扩容

2.IntSet
2.1IntSet结构
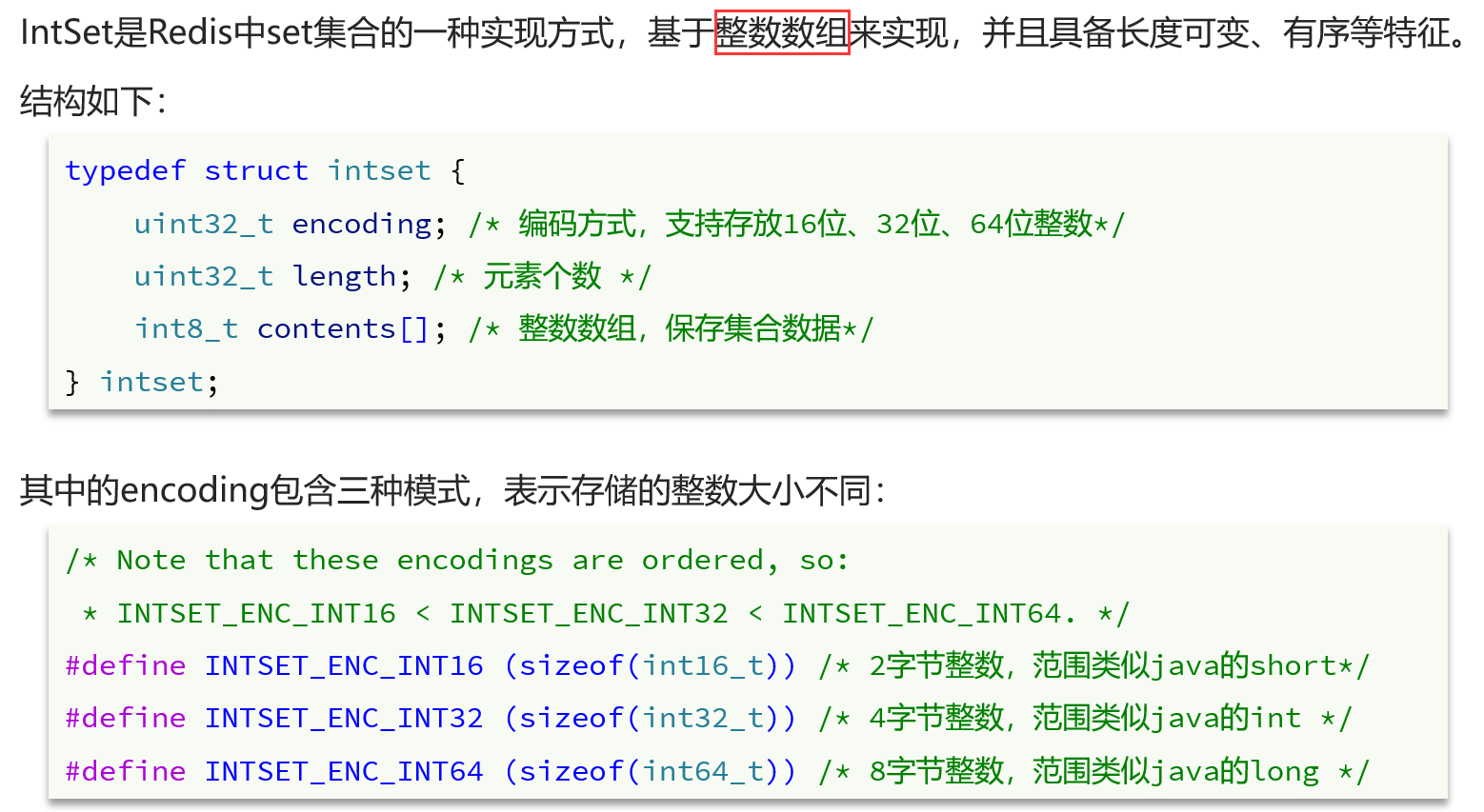
2.2IntSet存储

2.3IntSet升级
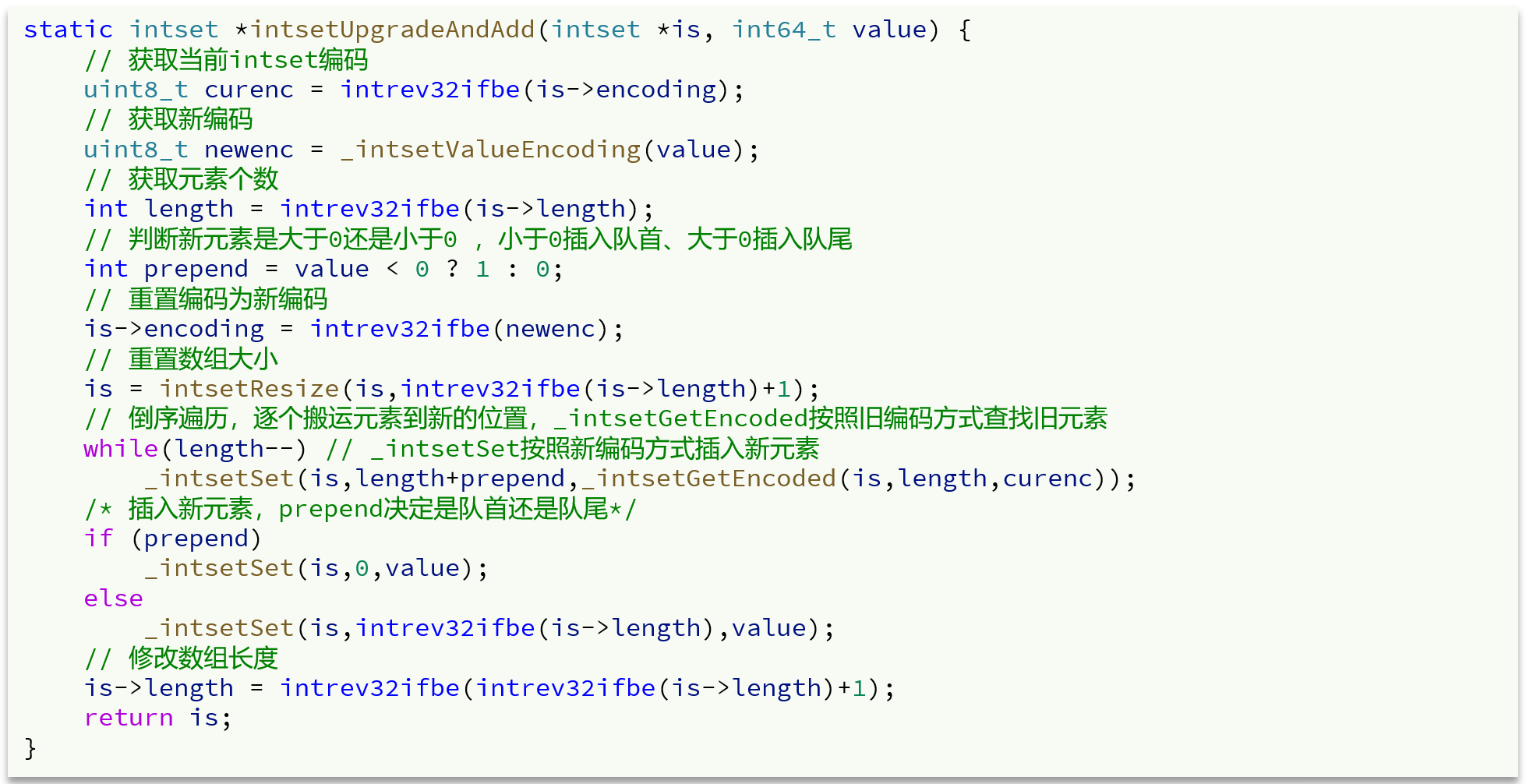
IntSet升级过程中需要自动升级编码方式,这是为了保证统一寻址的方便性。

2.4IntSet源码
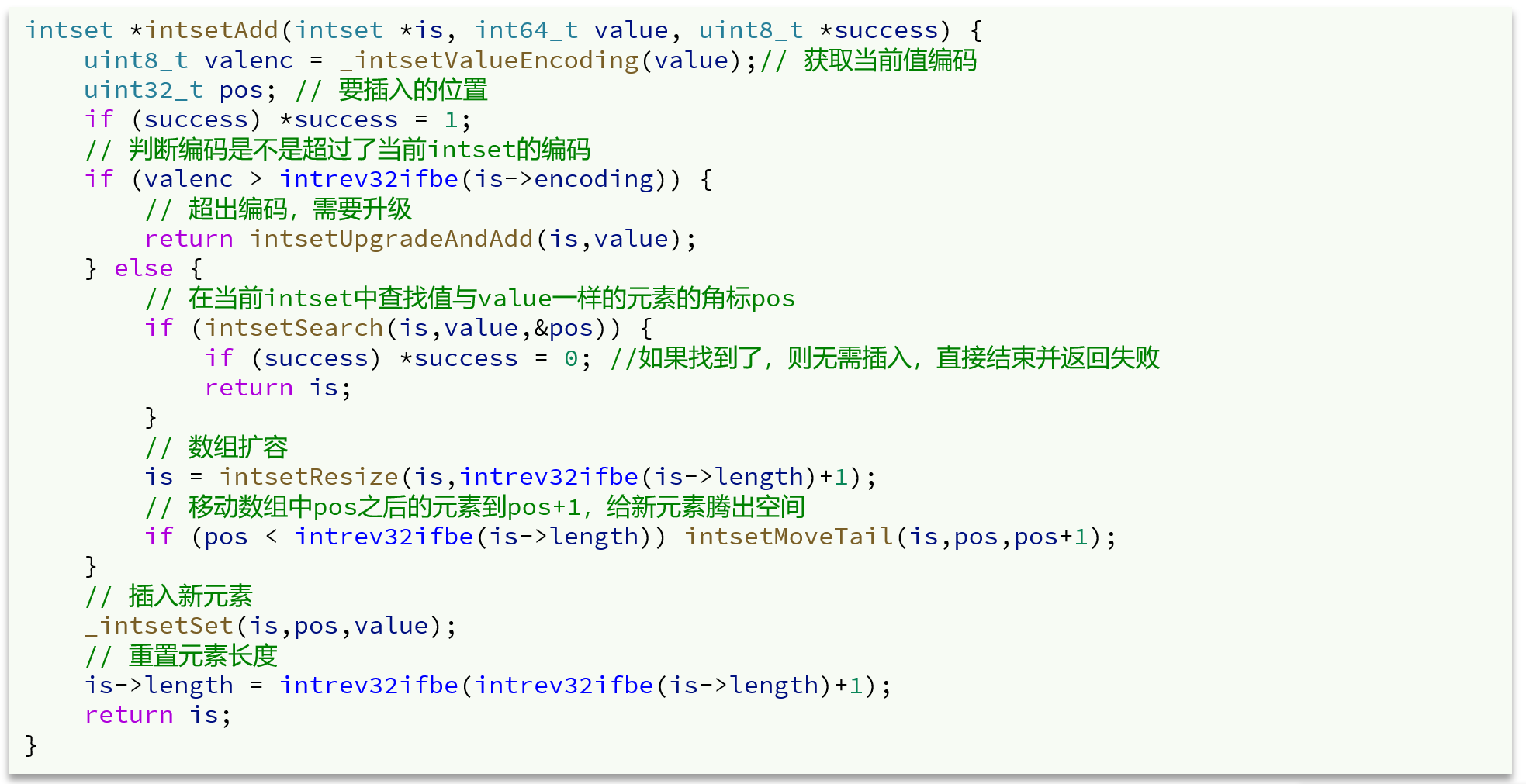
IntSet是用来保存不重复的整数集合的,底层采用整数数组+编码方式的实现,为了快速查询元素是否已经存在以及新元素需要插入的位置,IntSet实现上是一个有序整数数组,利用二分查找可以快速定位元素和待插入位置。
原数组元素倒序迁移,新加入的整数超出原编码方式的最大表示范围,可能为正数或负数;
1.如果新加入的整数newNum是大的正数,则原数组元素倒叙按序迁移,newNum放在末尾即可
2.如果新加入的整数newNum是大的负数,则原数组元素倒叙向后多迁移一位,newNum放在头部即可
IntSet由于是采用有序整数数组的实现方案,因此适用于元素数量不多的情况,此时可以兼顾速度和内存占用,一旦元素数量很多IntSet结构就不适用了,Dict是更好的方案。

3.Dict
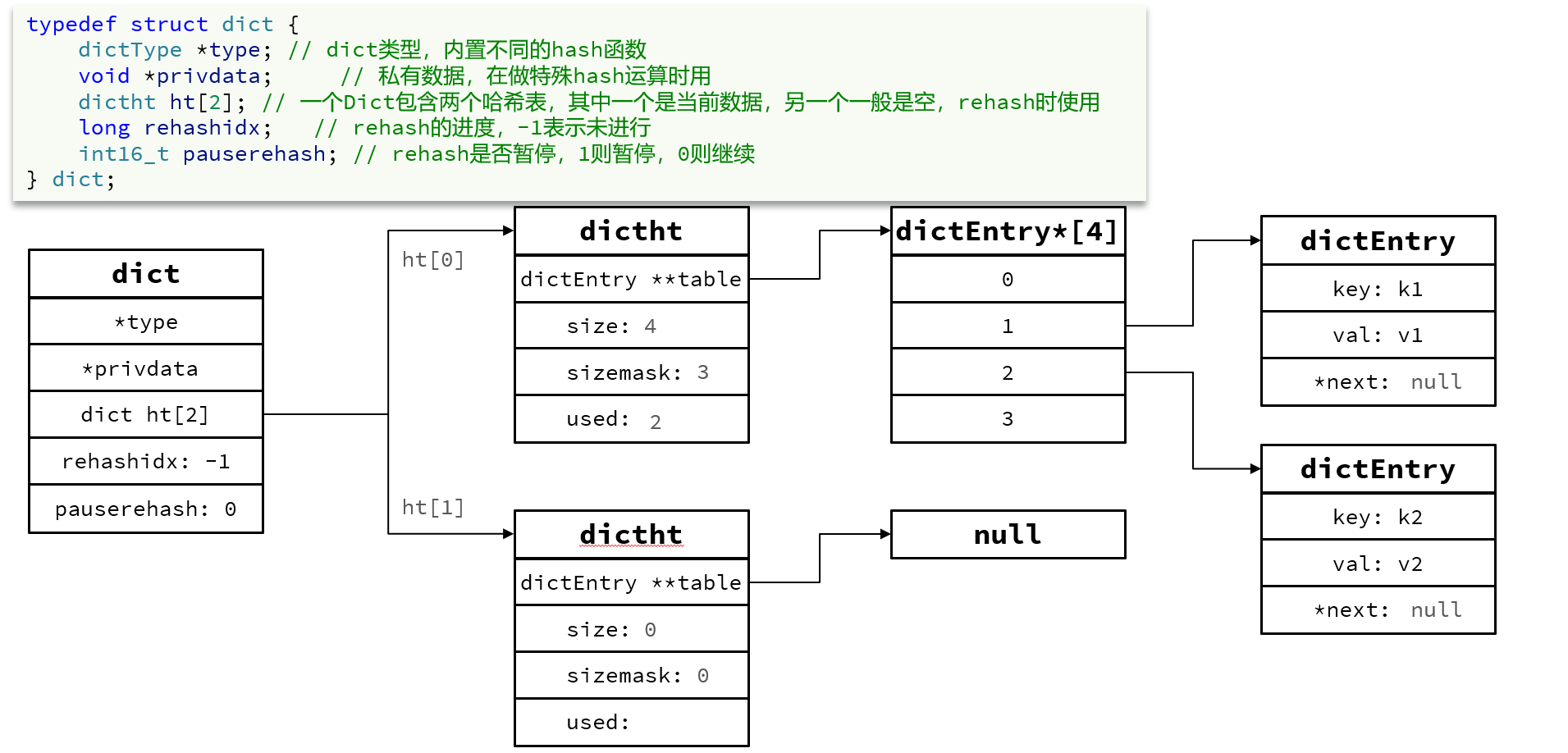
3.1Dict的结构
Dict类似于Java中的HashMap,是数组+链表的结构,通过Key和哈希函数计算出对应的哈希值,哈希值取模(size-1或sizemask)就得到了哈希槽位置,哈希冲突后使用拉链法形成一个单向链表。

单向链表采用头插法

任何一个字典都包含两个哈希表,其中一个用于ReHash使用
3.2Dict的渐进式扩容
类似于Java中HashMap的扩容,Dict在负载因子超过一定阈值就会触发哈希表扩容,防止链表过长影响查询效率,扩容的大小是超过used+1的最小的2的n次方。
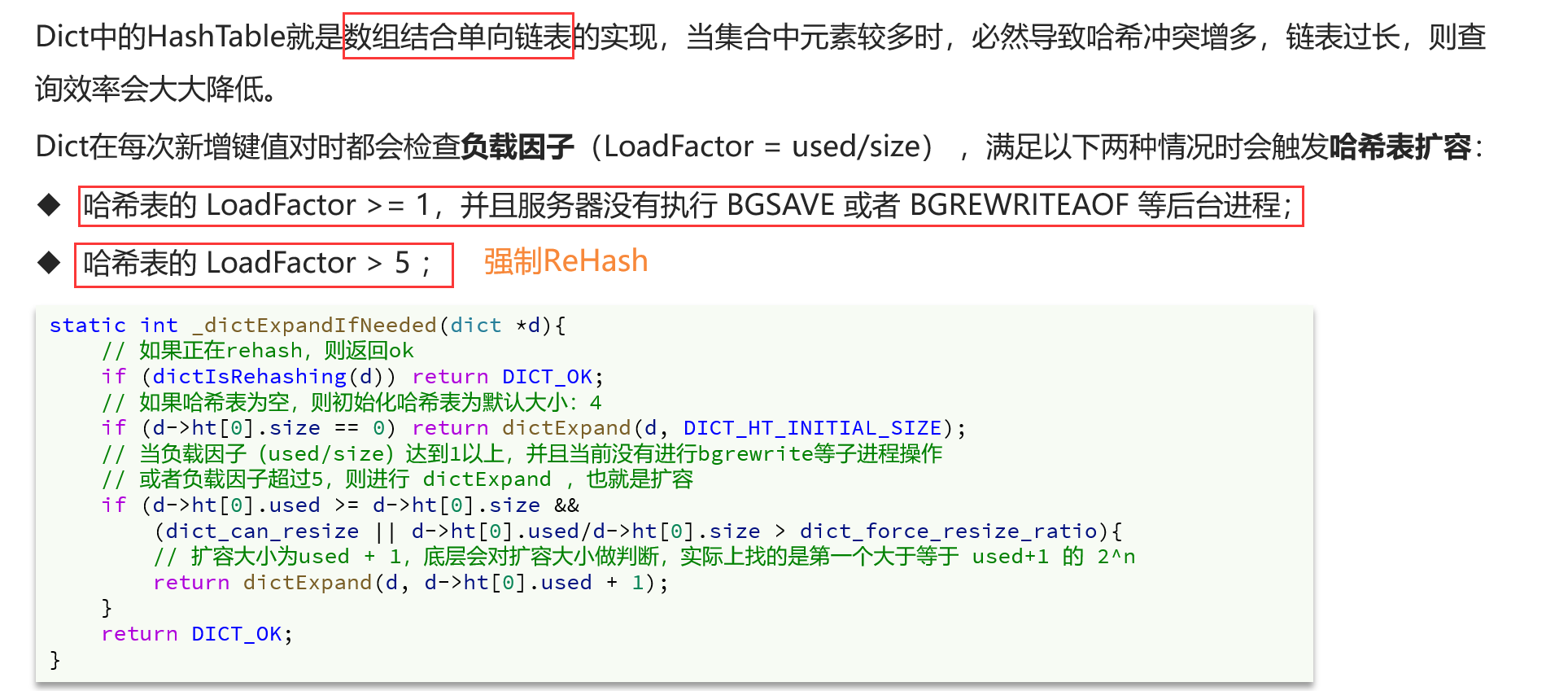
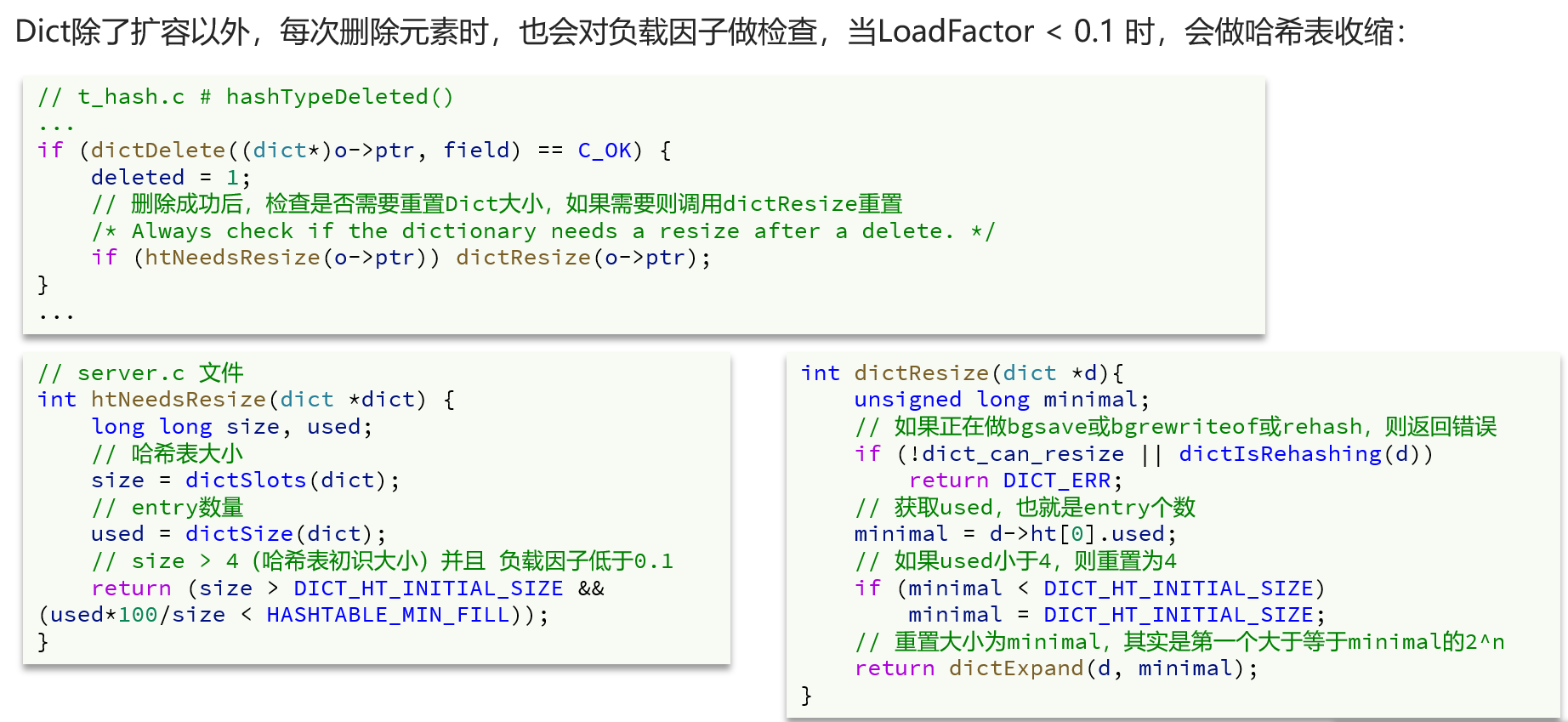
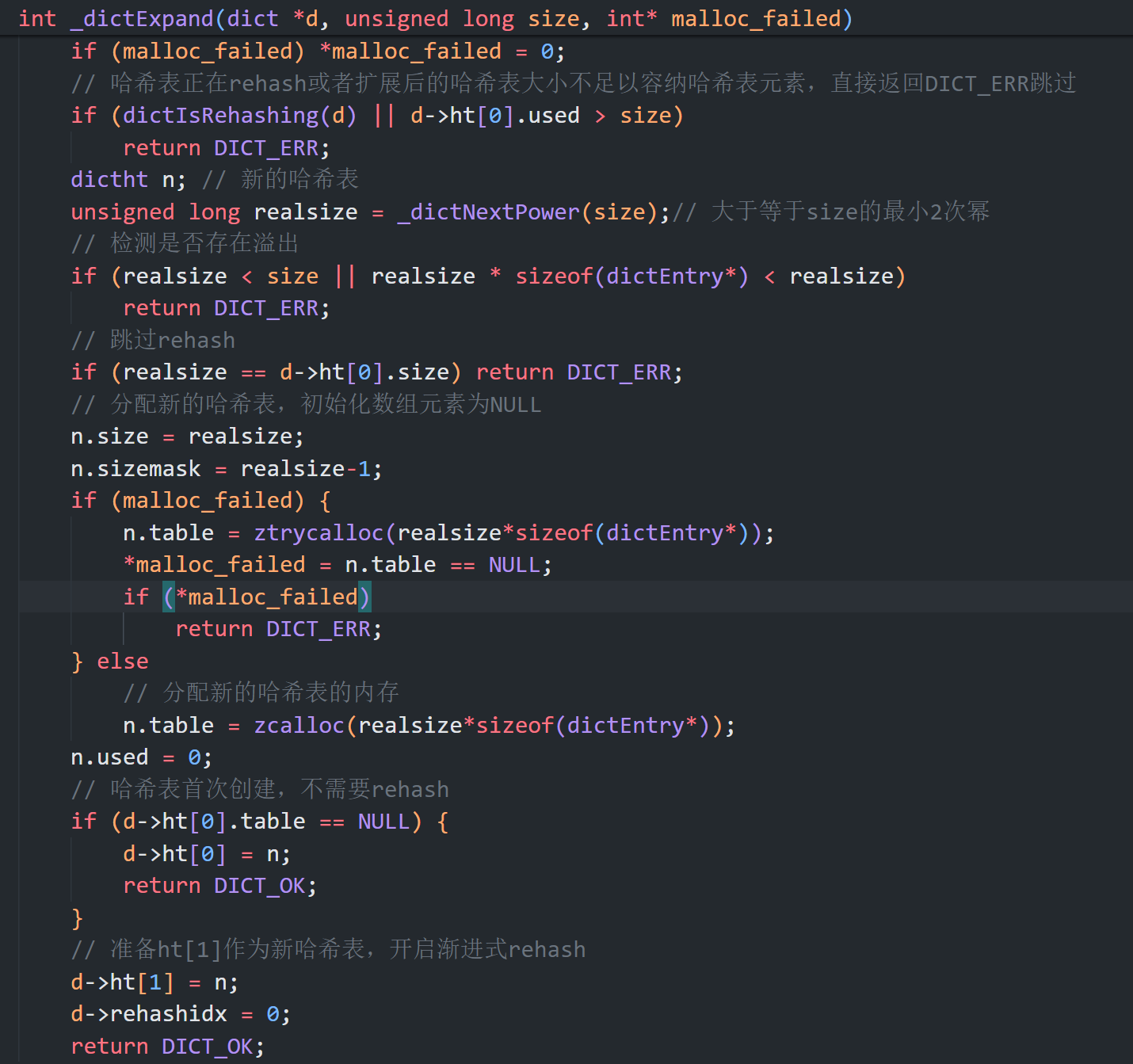
不仅新增时会扩容,删除时也会缩容,最终都是调用dictExpend函数,进行渐进式rehash


1 | int dictRehash(dict *d, int n) { |
1.rehash阶段数据是惰性渐进式迁移的,在每次增删改查时都会触发一个哈希桶位的数据迁移;
2.rehash过程中数据是双读单写的,双读指的是从ht[0]和ht[1]两个哈希表中查找数据,单写指的是只向ht[1]写入新数据,保证了旧哈希表的元素逐渐消亡。

4.ZipList
4.1ZipList结构
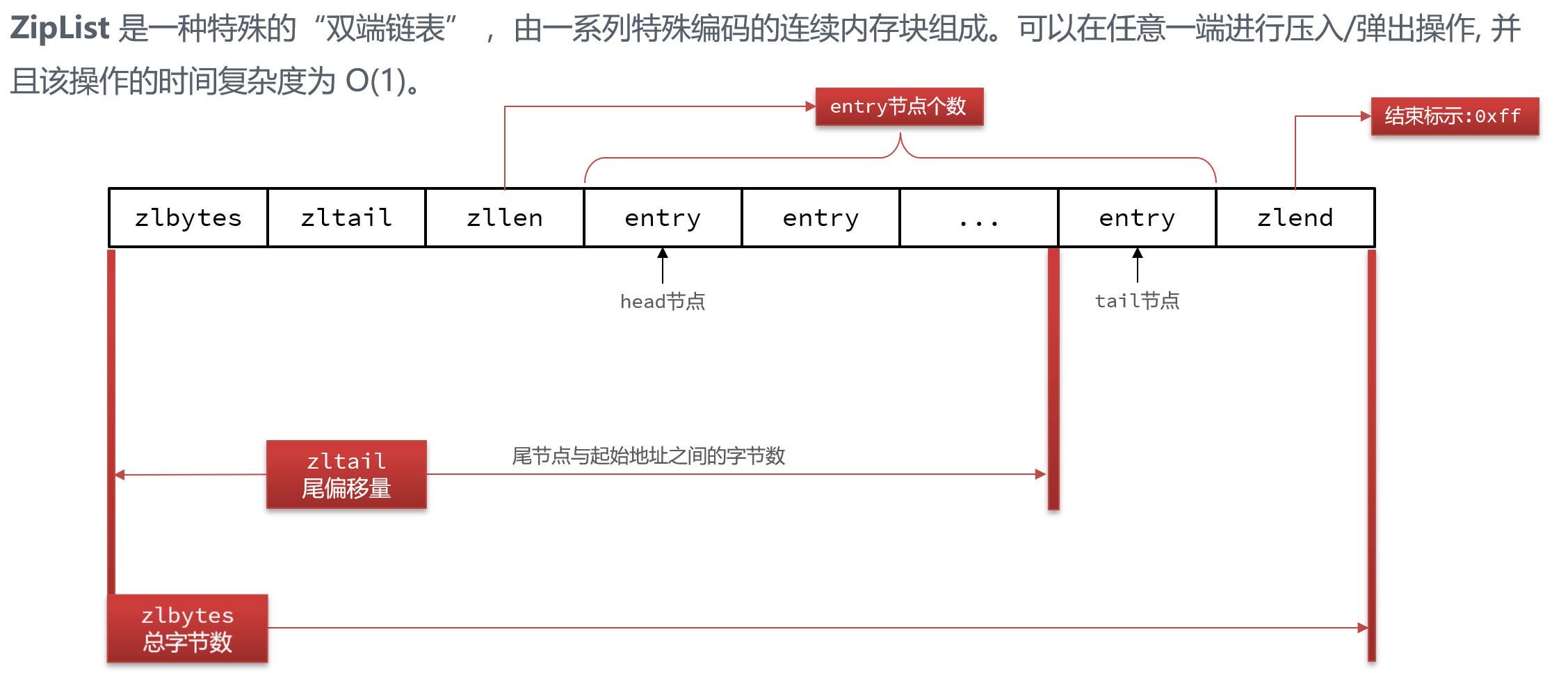
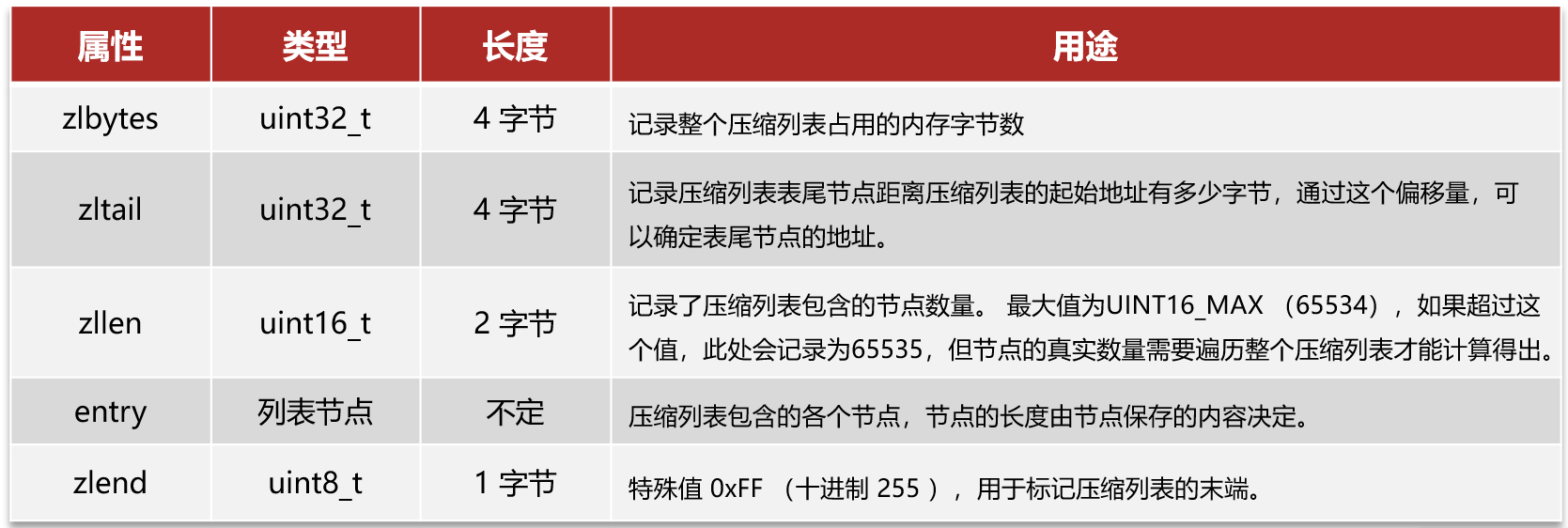
entry的结构比较复杂,为了减少使用链表带来的双向指针的内存消耗,entry间是连续内存分布的,通过encoding中的长度信息从前往后遍历,通过previous_entry_length从后往前遍历。类似于MySQL中记录行格式中的变长字段列表(小于127占用一个字节,否则两个字节,首比特位0/1标明变长字段长度占用字节数),previous_entry_length前一节点长度信息小于254占用一个字节,否则五个字节,第一个字节为oxfe标明占用五个字节。


ZipList的entry可以存放字符串和整数,具体的类型和长度信息由encoding表示。
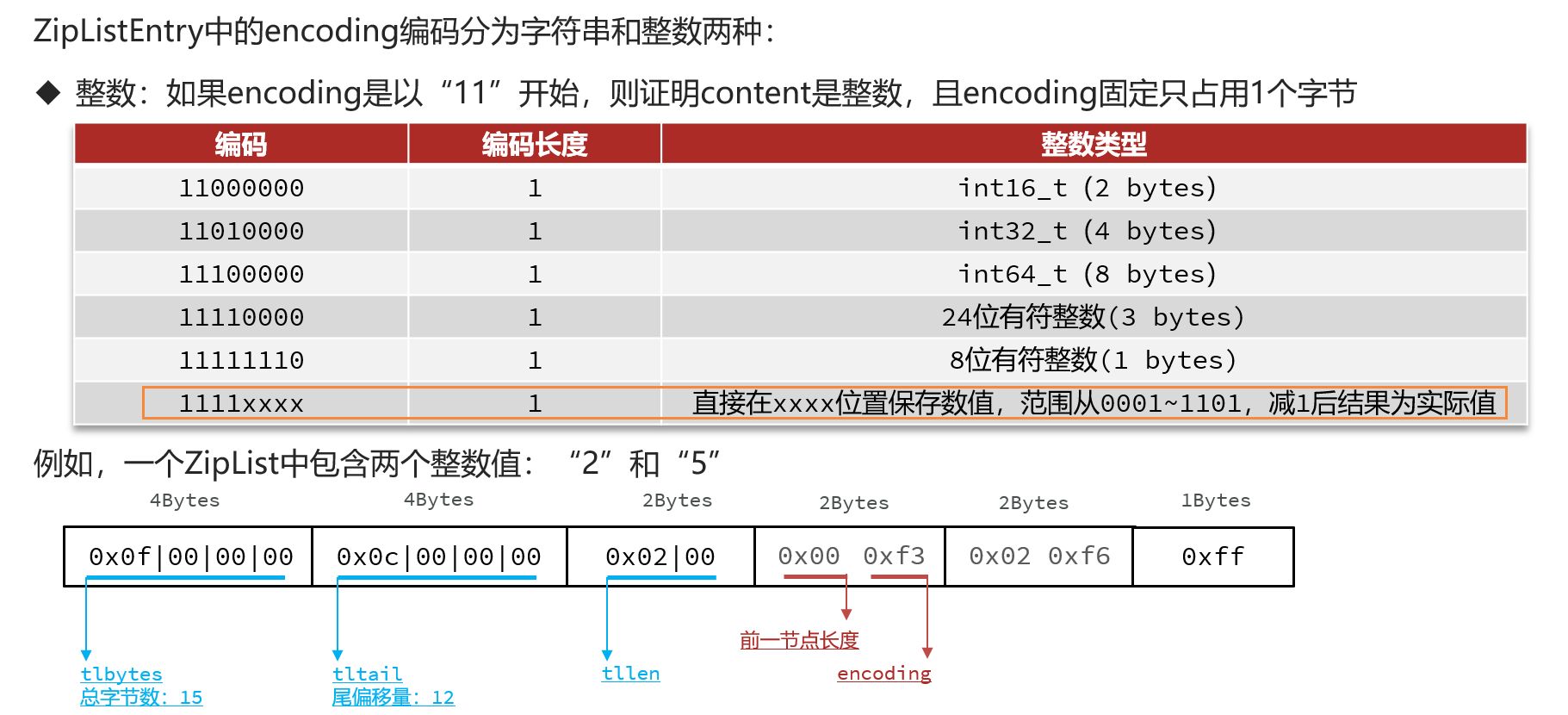
4.2ZipList的连锁更新
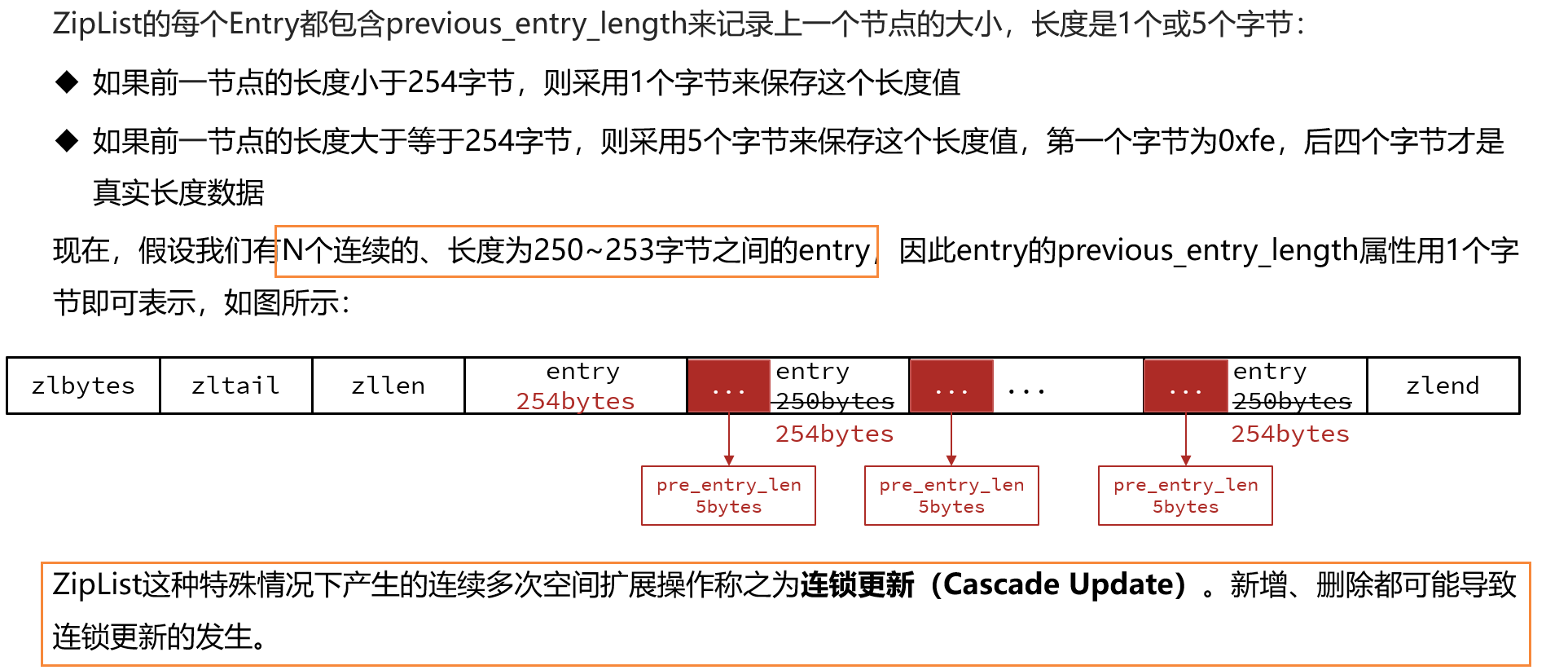
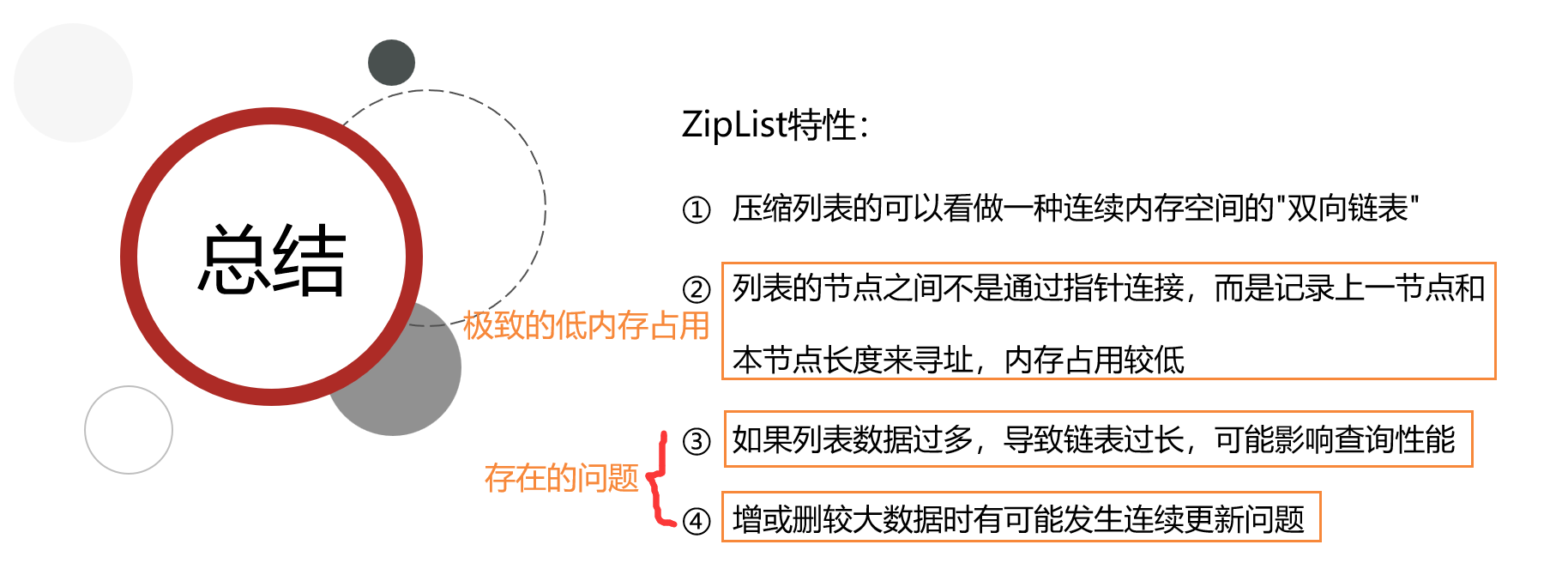
5.QuickList
5.1QuickList的由来
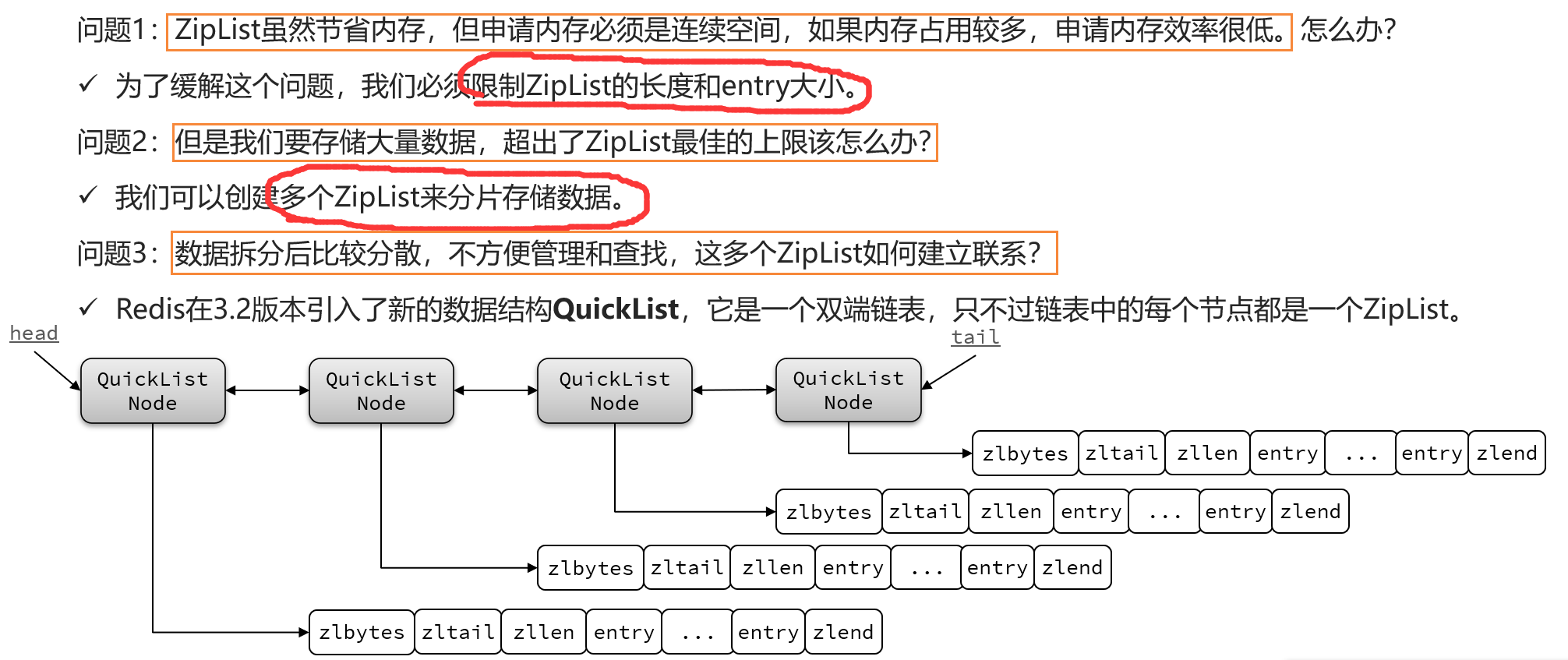
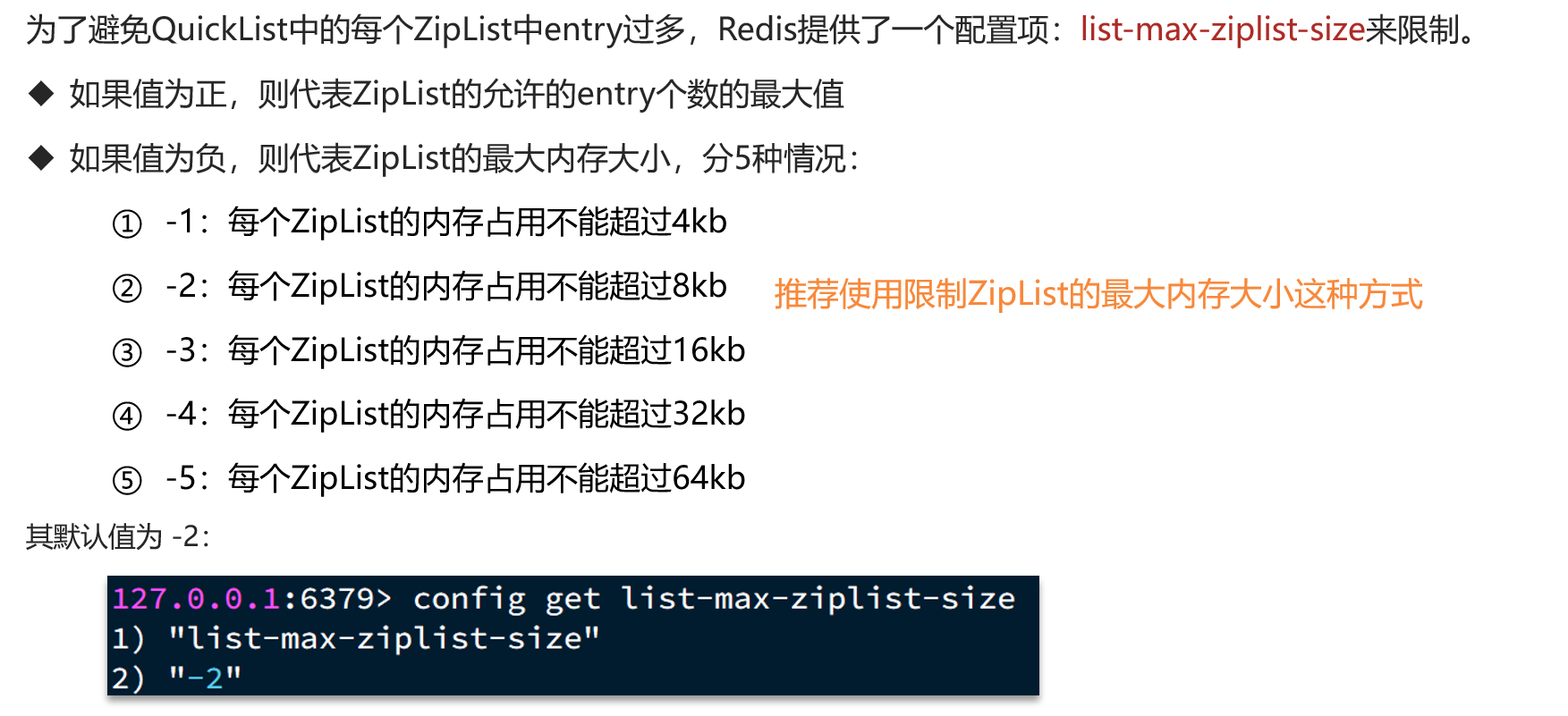
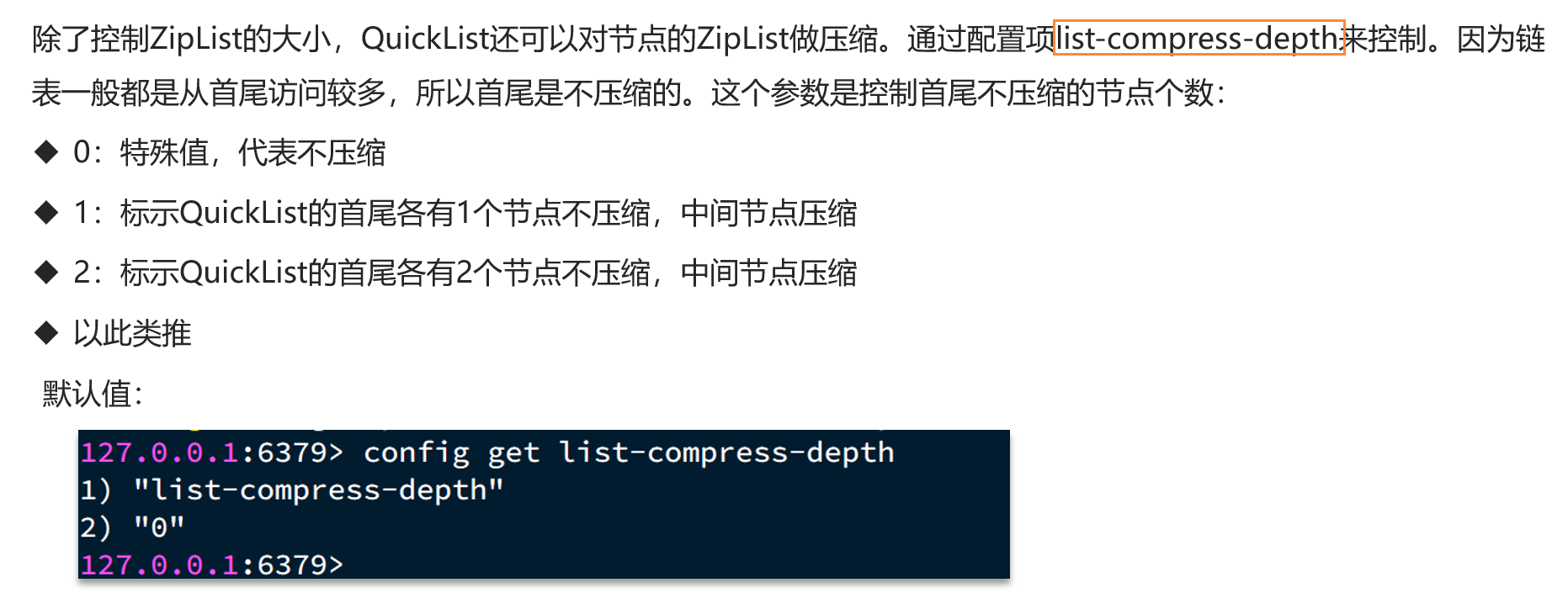
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低,因此需要限制ZipList的大小,QuickList中可以通过list-max-ziplist-size配置项调整节点大小,同时还能对节点的ZipList进一步压缩,可以通过list-compress-depth配置项控制双端压缩节点个数。
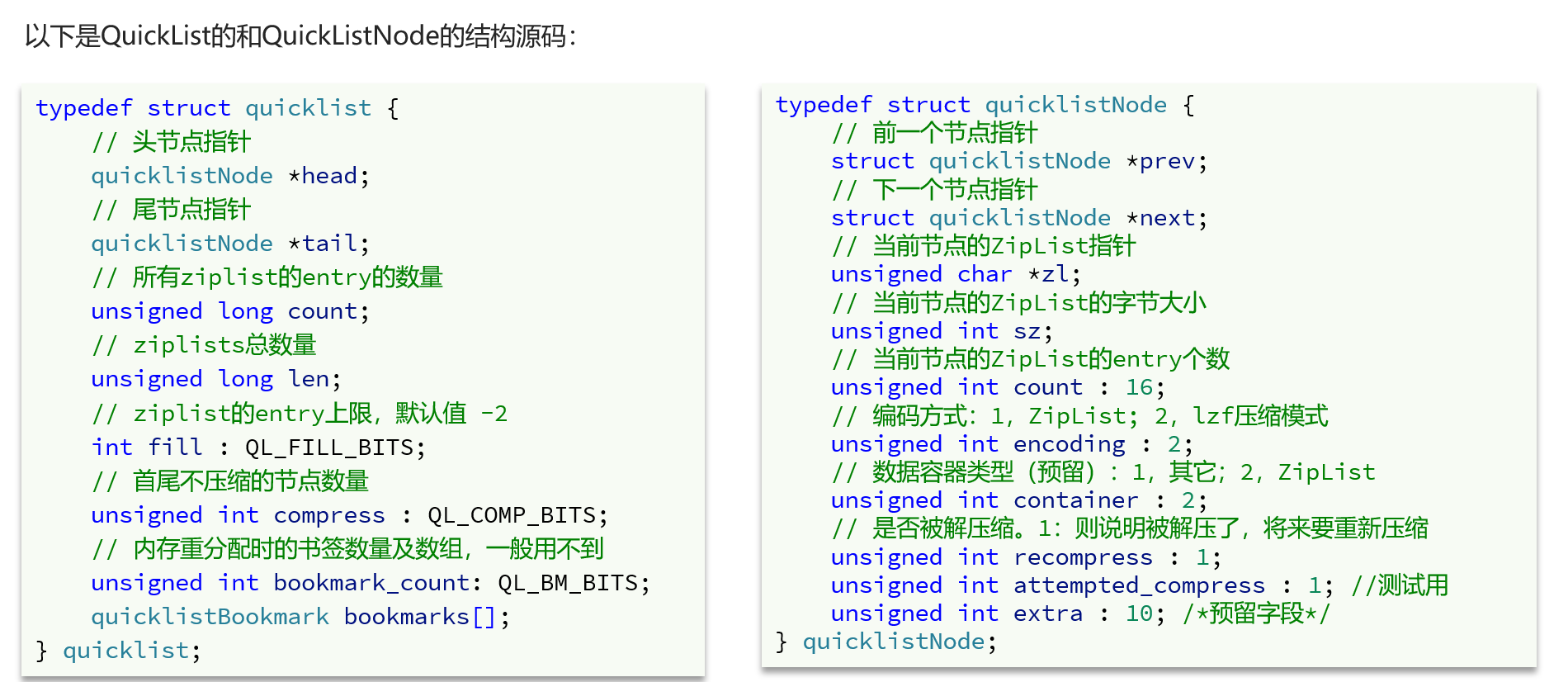
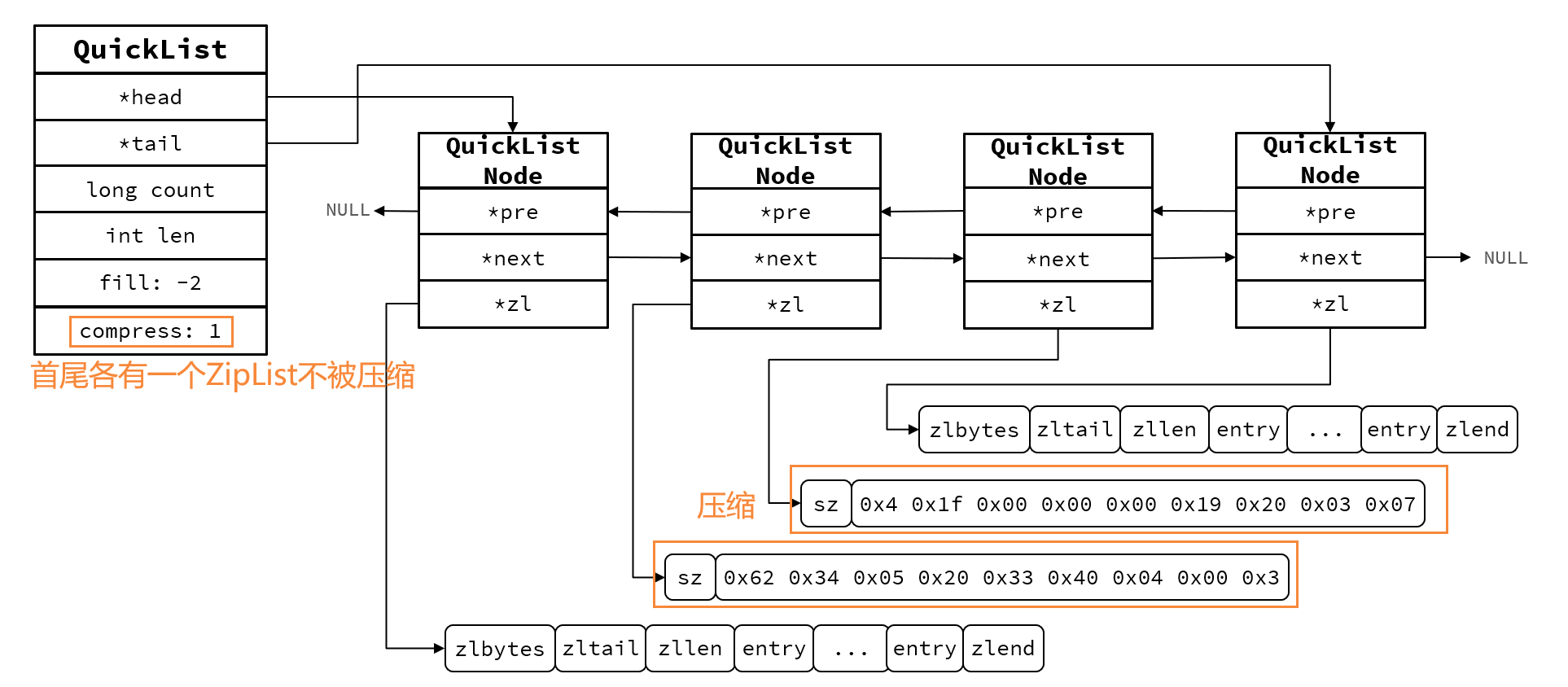
5.2QuickList的结构

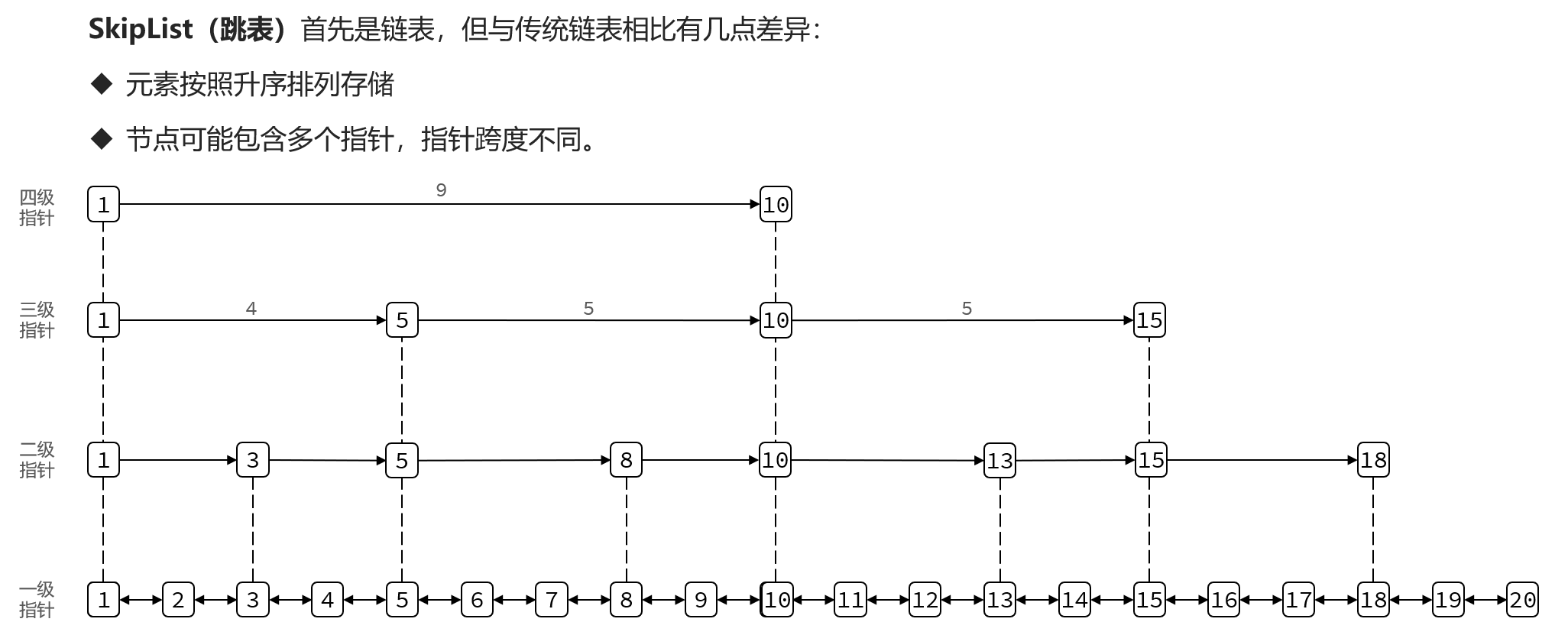
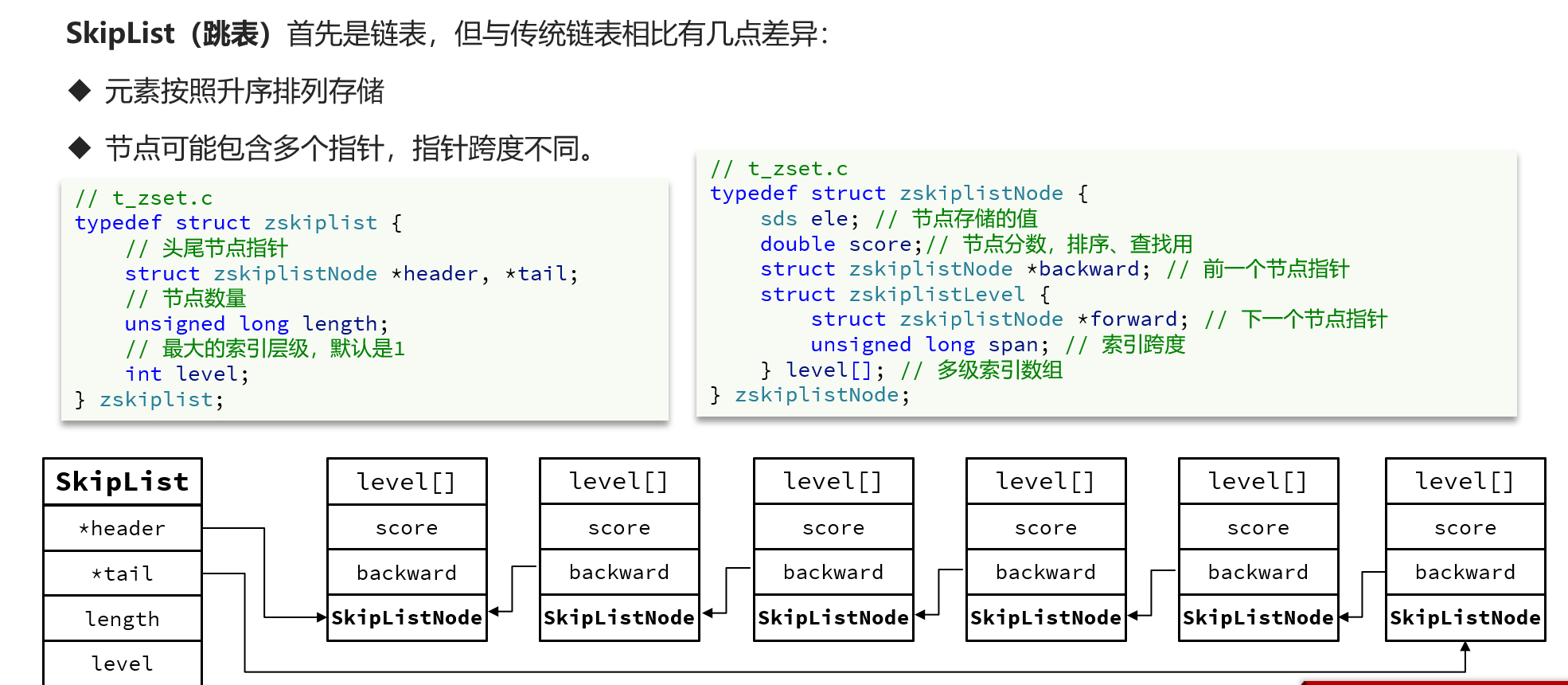
6.SkipList

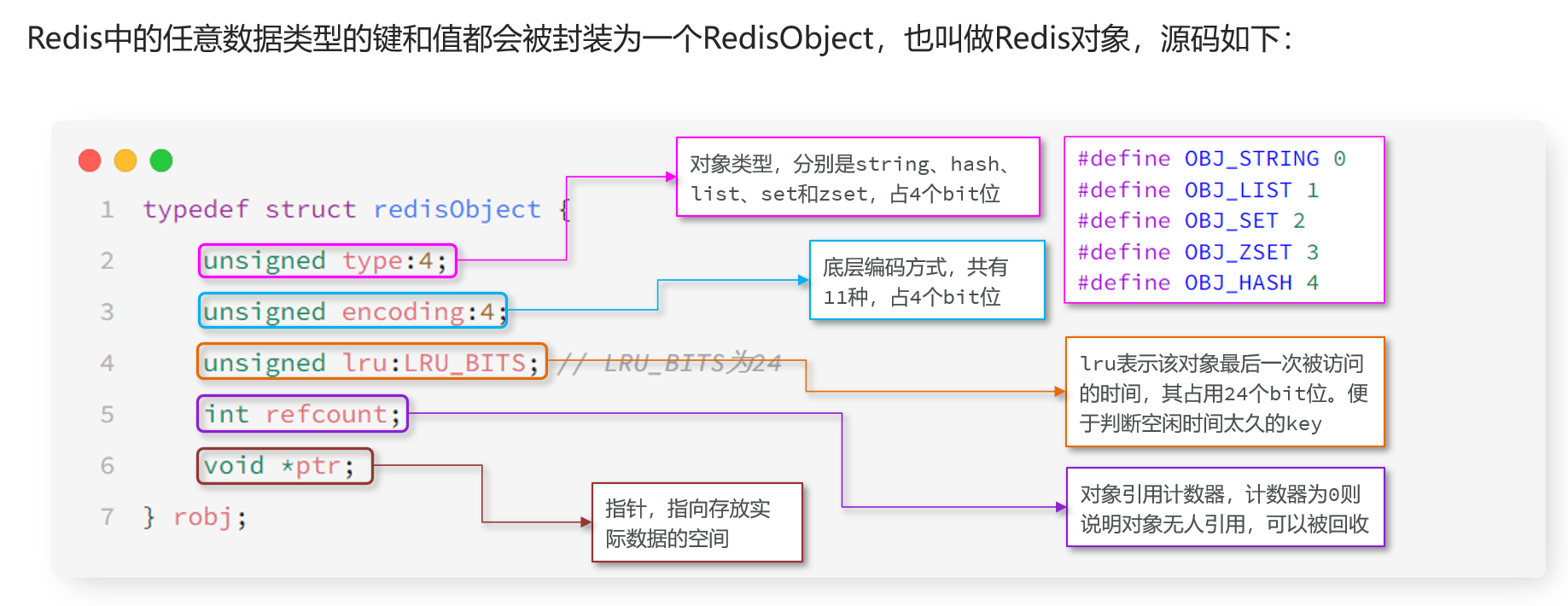
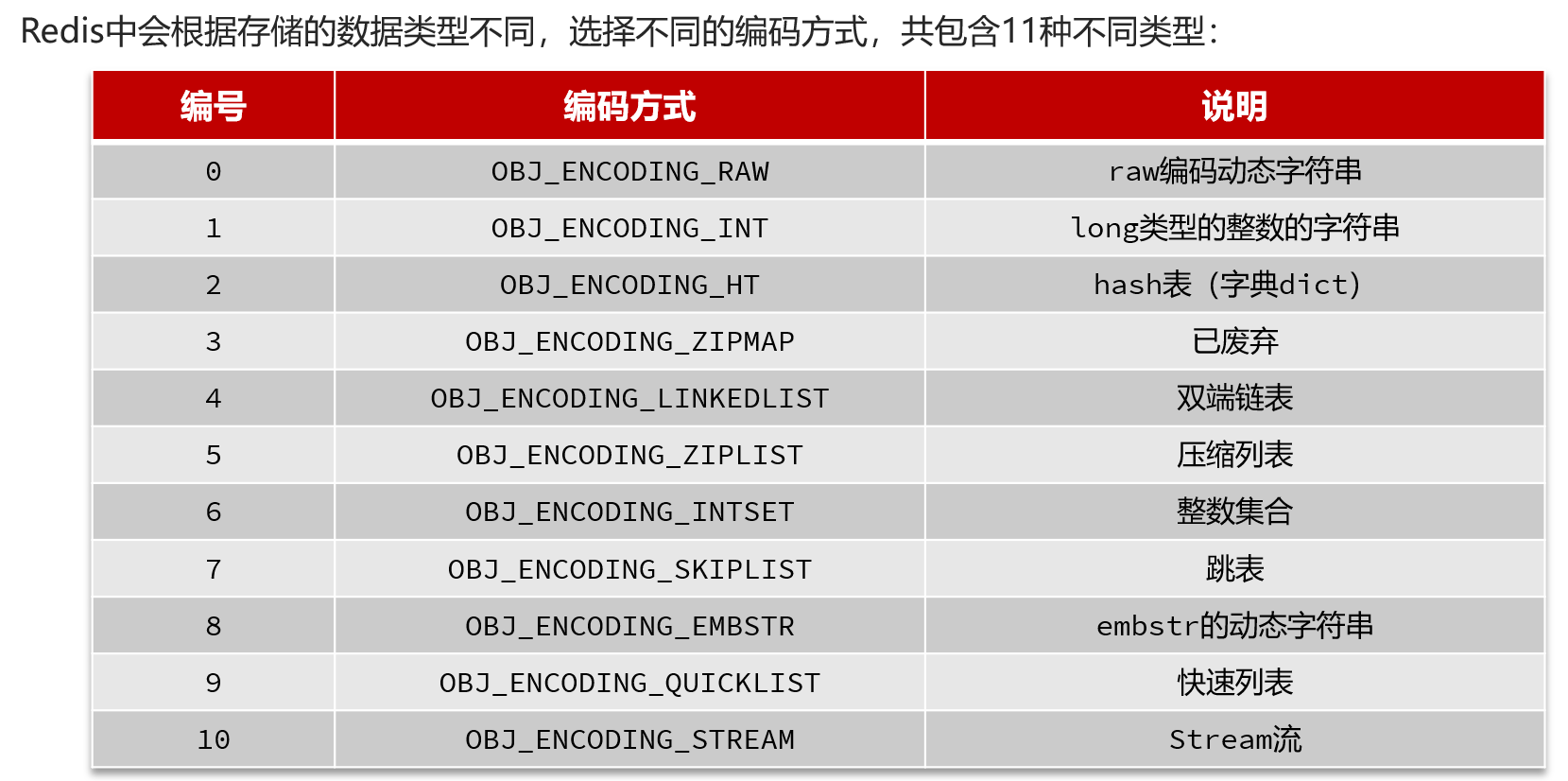
7.RedisObject