MySQL原理之事务篇
一、事务的简介
1.1事务的起源
对于大部分程序员来说,他们的任务就是把现实世界的业务场景映射到数据库世界。比如银行为了存储人们的账户信息会建立一个account表:
1 | CREATE TABLE account ( |
狗哥和猫爷是一对好基友,他们都到银行开一个账户,他们在现实世界中拥有的资产就会体现在数据库世界的account表中。比如现在狗哥有11元,猫爷只有2元,那么现实中的这个情况映射到数据库的account表就是这样:
1 | +----+--------+---------+ |
在某个特定的时刻,狗哥猫爷这些家伙在银行所拥有的资产是一个特定的值,这些特定的值也可以被描述为账户在这个特定的时刻现实世界的一个状态。随着时间的流逝,狗哥和猫爷可能陆续进行向账户中存钱、取钱或者向别人转账等操作,这样他们账户中的余额就可能发生变动,每一个操作都相当于现实世界中账户的一次状态转换。数据库世界作为现实世界的一个映射,自然也要进行相应的变动。不变不知道,一变吓一跳,现实世界中一些看似很简单的状态转换,映射到数据库世界却不是那么容易的。比方说有一次猫爷在赌场赌博输了钱,急忙打电话给狗哥要借10块钱,不然那些看场子的就会把自己剁了。现实世界中的狗哥走向了ATM机,输入了猫爷的账号以及10元的转账金额,然后按下确认,狗哥就拔卡走人了。对于数据库世界来说,相当于执行了下边这两条语句:
1 | UPDATE account SET balance = balance - 10 WHERE id = 1; |
但是这里头有个问题,上述两条语句只执行了一条时忽然服务器断电了咋办?把狗哥的钱扣了,但是没给猫爷转过去,那猫爷还是逃脱不了被砍死的噩运~ 即使对于单独的一条语句,我们前边唠叨Buffer Pool时也说过,在对某个页面进行读写访问时,都会先把这个页面加载到Buffer Pool中,之后如果修改了某个页面,也不会立即把修改同步到磁盘,而只是把这个修改了的页面加到Buffer Pool的flush链表中,在之后的某个时间点才会刷新到磁盘。如果在将修改过的页刷新到磁盘之前系统崩溃了那岂不是猫爷还是要被砍死?或者在刷新磁盘的过程中(只刷新部分数据到磁盘上)系统奔溃了猫爷也会被砍死?
怎么才能保证让可怜的猫爷不被砍死呢?其实再仔细想想,我们只是想让某些数据库操作符合现实世界中状态转换的规则而已,设计数据库的大叔们仔细盘算了盘算,现实世界中状态转换的规则有好几条,待我们慢慢道来。
1.1.1原子性(Atomicity)
现实世界中转账操作是一个不可分割的操作,也就是说要么压根儿就没转,要么转账成功,不能存在中间的状态,也就是转了一半的这种情况。设计数据库的大叔们把这种要么全做,要么全不做的规则称之为原子性。但是在现实世界中的一个不可分割的操作却可能对应着数据库世界若干条不同的操作,数据库中的一条操作也可能被分解成若干个步骤(比如先修改缓存页,之后再刷新到磁盘等),最要命的是在任何一个可能的时间都可能发生意想不到的错误(可能是数据库本身的错误,或者是操作系统错误,甚至是直接断电之类的)而使操作执行不下去,所以猫爷可能会被砍死。为了保证在数据库世界中某些操作的原子性,设计数据库的大叔需要费一些心机来保证如果在执行操作的过程中发生了错误,把已经做了的操作恢复成没执行之前的样子,这也是我们后边章节要仔细唠叨的内容。
1.1.2隔离性(Isolation)
现实世界中的两次状态转换应该是互不影响的,比如说狗哥向猫爷同时进行的两次金额为5元的转账(假设可以在两个ATM机上同时操作)。那么最后狗哥的账户里肯定会少10元,猫爷的账户里肯定多了10元。但是到对应的数据库世界中,事情又变的复杂了一些。为了简化问题,我们粗略的假设狗哥向猫爷转账5元的过程是由下边几个步骤组成的:
- 步骤一:读取狗哥账户的余额到变量A中,这一步骤简写为
read(A)。 - 步骤二:将狗哥账户的余额减去转账金额,这一步骤简写为
A = A - 5。 - 步骤三:将狗哥账户修改过的余额写到磁盘里,这一步骤简写为
write(A)。 - 步骤四:读取猫爷账户的余额到变量B,这一步骤简写为
read(B)。 - 步骤五:将猫爷账户的余额加上转账金额,这一步骤简写为
B = B + 5。 - 步骤六:将猫爷账户修改过的余额写到磁盘里,这一步骤简写为
write(B)。
我们将狗哥向猫爷同时进行的两次转账操作分别称为T1和T2,在现实世界中T1和T2是应该没有关系的,可以先执行完T1,再执行T2,或者先执行完T2,再执行T1,对应的数据库操作就像这样:

但是很不幸,真实的数据库中T1和T2的操作可能交替执行,比如这样:
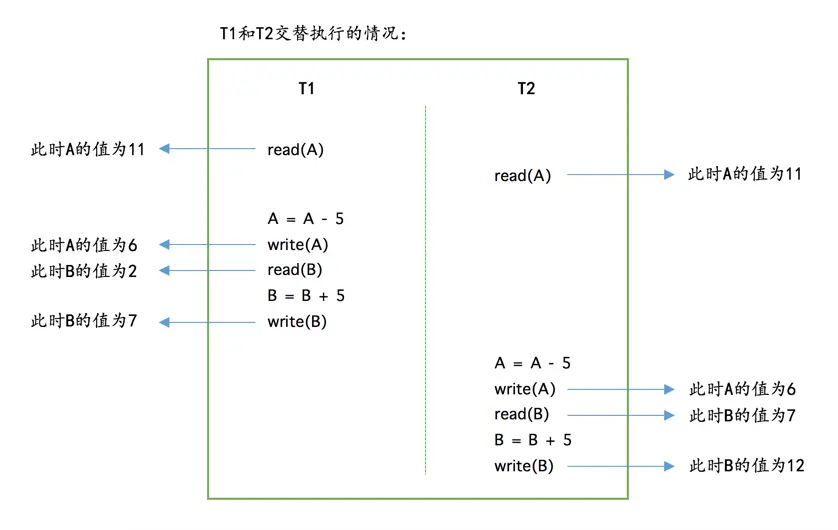
如果按照上图中的执行顺序来进行两次转账的话,最终狗哥的账户里还剩6元钱,相当于只扣了5元钱,但是猫爷的账户里却成了12元钱,相当于多了10元钱,这银行岂不是要亏死了?
所以对于现实世界中状态转换对应的某些数据库操作来说,不仅要保证这些操作以原子性的方式执行完成,而且要保证其它的状态转换不会影响到本次状态转换,这个规则被称之为隔离性。这时设计数据库的大叔们就需要采取一些措施来让访问相同数据(上例中的A账户和B账户)的不同状态转换(上例中的T1和T2)对应的数据库操作的执行顺序有一定规律,这也是我们后边章节要仔细唠叨的内容。
1.1.3一致性(Consistency)
我们生活的这个世界存在着形形色色的约束,比如身份证号不能重复,性别只能是男或者女,高考的分数只能在0~750之间,人民币面值最大只能是100(现在是2019年),红绿灯只有3种颜色,房价不能为负的,学生要听老师话,吧啦吧啦有点儿扯远了~ 只有符合这些约束的数据才是有效的,比如有个小孩儿跟你说他高考考了1000分,你一听就知道他胡扯呢。数据库世界只是现实世界的一个映射,现实世界中存在的约束当然也要在数据库世界中有所体现。如果数据库中的数据全部符合现实世界中的约束(all defined rules),我们说这些数据就是一致的,或者说符合一致性的。
如何保证数据库中数据的一致性(就是符合所有现实世界的约束)呢?这其实靠两方面的努力:
数据库本身能为我们保证一部分一致性需求(就是数据库自身可以保证一部分现实世界的约束永远有效)。
我们知道
MySQL数据库可以为表建立主键、唯一索引、外键、声明某个列为NOT NULL来拒绝NULL值的插入。比如说当我们对某个列建立唯一索引时,如果插入某条记录时该列的值重复了,那么MySQL就会报错并且拒绝插入。除了这些我们已经非常熟悉的保证一致性的功能,MySQL还支持CHECK语法来自定义约束,比如这样:1
2
3
4
5
6
7CREATE TABLE account (
id INT NOT NULL AUTO_INCREMENT COMMENT '自增id',
name VARCHAR(100) COMMENT '客户名称',
balance INT COMMENT '余额',
PRIMARY KEY (id),
CHECK (balance >= 0)
);上述例子中的
CHECK语句本意是想规定balance列不能存储小于0的数字,对应的现实世界的意思就是银行账户余额不能小于0。但是很遗憾,MySQL仅仅支持CHECK语法,但实际上并没有一点卵用,也就是说即使我们使用上述带有CHECK子句的建表语句来创建account表,那么在后续插入或更新记录时,MySQL并不会去检查CHECK子句中的约束是否成立。其它的一些数据库,比如SQL Server或者Oracle支持的CHECK语法是有实实在在的作用的,每次进行插入或更新记录之前都会检查一下数据是否符合CHECK子句中指定的约束条件是否成立,如果不成立的话就会拒绝插入或更新。
虽然
CHECK子句对一致性检查没什么卵用,但是我们还是可以通过定义触发器的方式来自定义一些约束条件以保证数据库中数据的一致性。更多的一致性需求需要靠写业务代码的程序员自己保证。
为建立现实世界和数据库世界的对应关系,理论上应该把现实世界中的所有约束都反应到数据库世界中,但是很不幸,在更改数据库数据时进行一致性检查是一个耗费性能的工作,比方说我们为
account表建立了一个触发器,每当插入或者更新记录时都会校验一下balance列的值是不是大于0,这就会影响到插入或更新的速度。仅仅是校验一行记录符不符合一致性需求倒也不是什么大问题,有的一致性需求简直变态,比方说银行会建立一张代表账单的表,里边儿记录了每个账户的每笔交易,每一笔交易完成后,都需要保证整个系统的余额等于所有账户的收入减去所有账户的支出。如果在数据库层面实现这个一致性需求的话,每次发生交易时,都需要将所有的收入加起来减去所有的支出,再将所有的账户余额加起来,看看两个值相不相等。这不是搞笑呢么,如果账单表里有几亿条记录,光是这个校验的过程可能就要跑好几个小时,也就是说你在煎饼摊买个煎饼,使用银行卡付款之后要等好几个小时才能提示付款成功,这样的性能代价是完全承受不起的。现实生活中复杂的一致性需求比比皆是,而由于性能问题把一致性需求交给数据库去解决这是不现实的,所以这个锅就甩给了业务端程序员。比方说我们的
account表,我们也可以不建立触发器,只要编写业务的程序员在自己的业务代码里判断一下,当某个操作会将balance列的值更新为小于0的值时,就不执行该操作就好了嘛!
我们前边唠叨的原子性和隔离性都会对一致性产生影响,比如我们现实世界中转账操作完成后,有一个一致性需求就是参与转账的账户的总的余额是不变的。如果数据库不遵循原子性要求,也就是转了一半就不转了,也就是说给狗哥扣了钱而没给猫爷转过去,那最后就是不符合一致性需求的;类似的,如果数据库不遵循隔离性要求,就像我们前边唠叨隔离性时举的例子中所说的,最终狗哥账户中扣的钱和猫爷账户中涨的钱可能就不一样了,也就是说不符合一致性需求了。所以说,数据库某些操作的原子性和隔离性都是保证一致性的一种手段,在操作执行完成后保证符合所有既定的约束则是一种结果。那满足原子性和隔离性的操作一定就满足一致性么?那倒也不一定,比如说狗哥要转账20元给猫爷,虽然在满足原子性和隔离性,但转账完成了之后狗哥的账户的余额就成负的了,这显然是不满足一致性的。那不满足原子性和隔离性的操作就一定不满足一致性么?这也不一定,只要最后的结果符合所有现实世界中的约束,那么就是符合一致性的。
1.1.4持久性(Durability)
当现实世界的一个状态转换完成后,这个转换的结果将永久的保留,这个规则被设计数据库的大叔们称为持久性。比方说狗哥向猫爷转账,当ATM机提示转账成功了,就意味着这次账户的状态转换完成了,狗哥就可以拔卡走人了。如果当狗哥走掉之后,银行又把这次转账操作给撤销掉,恢复到没转账之前的样子,那猫爷不就惨了,又得被砍死了,所以这个持久性是非常重要的。
当把现实世界的状态转换映射到数据库世界时,持久性意味着该转换对应的数据库操作所修改的数据都应该在磁盘上保留下来,不论之后发生了什么事故,本次转换造成的影响都不应该被丢失掉(要不然猫爷还是会被砍死)。
1.2MySQL中事务的语法
我们说事务的本质其实只是一系列数据库操作,只不过这些数据库操作符合ACID特性而已,那么MySQL中如何将某些操作放到一个事务里去执行的呢?我们下边就来重点唠叨唠叨。
1.2.1开启事务
我们可以使用下边两种语句之一来开启一个事务:
BEGIN [WORK];BEGIN语句代表开启一个事务,后边的单词WORK可有可无。开启事务后,就可以继续写若干条语句,这些语句都属于刚刚开启的这个事务。1
2
3
4mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> 加入事务的语句...START TRANSACTION;START TRANSACTION语句和BEGIN语句有着相同的功效,都标志着开启一个事务,比如这样:1
2
3
4mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> 加入事务的语句...不过比
BEGIN语句牛逼一点儿的是,可以在START TRANSACTION语句后边跟随几个修饰符,就是它们几个:READ ONLY:标识当前事务是一个只读事务,也就是属于该事务的数据库操作只能读取数据,而不能修改数据。其实只读事务中只是不允许修改那些其他事务也能访问到的表中的数据,对于临时表来说(我们使用CREATE TMEPORARY TABLE创建的表),由于它们只能在当前会话中可见,所以只读事务其实也是可以对临时表进行增、删、改操作的。
READ WRITE:标识当前事务是一个读写事务,也就是属于该事务的数据库操作既可以读取数据,也可以修改数据。WITH CONSISTENT SNAPSHOT:启动一致性读(先不用关心啥是个一致性读,后边的章节才会唠叨)。
比如我们想开启一个只读事务的话,直接把
READ ONLY这个修饰符加在START TRANSACTION语句后边就好,比如这样:1
START TRANSACTION READ ONLY;
如果我们想在
START TRANSACTION后边跟随多个修饰符的话,可以使用逗号将修饰符分开,比如开启一个只读事务和一致性读,就可以这样写:1
START TRANSACTION READ ONLY, WITH CONSISTENT SNAPSHOT;
不过这里需要大家注意的一点是,
READ ONLY和READ WRITE是用来设置所谓的事务访问模式的,就是以只读还是读写的方式来访问数据库中的数据,一个事务的访问模式不能同时既设置为只读的也设置为读写的,所以我们不能同时把READ ONLY和READ WRITE放到START TRANSACTION语句后边。另外,如果我们不显式指定事务的访问模式,那么该事务的访问模式就是读写模式。
1.2.2提交事务
开启事务之后就可以继续写需要放到该事务中的语句了,当最后一条语句写完了之后,我们就可以提交该事务了,提交的语句也很简单:
1 | COMMIT [WORK] |
COMMIT语句就代表提交一个事务,后边的WORK可有可无。比如我们上边说狗哥给猫爷转10元钱其实对应MySQL中的两条语句,我们就可以把这两条语句放到一个事务中,完整的过程就是这样:
1 | mysql> BEGIN; |
1.2.3手动中止事务
如果我们写了几条语句之后发现上边的某条语句写错了,我们可以手动的使用下边这个语句来将数据库恢复到事务执行之前的样子:
1 | ROLLBACK [WORK] |
ROLLBACK语句就代表中止并回滚一个事务,后边的WORK可有可无类似的。比如我们在写狗哥给猫爷转账10元钱对应的MySQL语句时,先给狗哥扣了10元,然后一时大意只给猫爷账户上增加了1元,此时就可以使用ROLLBACK语句进行回滚,完整的过程就是这样:
1 | mysql> BEGIN; |
这里需要强调一下,ROLLBACK语句是我们程序员手动的去回滚事务时才去使用的,如果事务在执行过程中遇到了某些错误而无法继续执行的话,事务自身会自动的回滚。
我们这里所说的开启、提交、中止事务的语法只是针对使用黑框框时通过mysql客户端程序与服务器进行交互时控制事务的语法,如果大家使用的是别的客户端程序,比如JDBC之类的,那需要参考相应的文档来看看如何控制事务。
1.2.4自动提交
MySQL中有一个系统变量autocommit:
1 | mysql> SHOW VARIABLES LIKE 'autocommit'; |
可以看到它的默认值为ON,也就是说默认情况下,如果我们不显式的使用START TRANSACTION或者BEGIN语句开启一个事务,那么每一条语句都算是一个独立的事务,这种特性称之为事务的自动提交。假如我们在狗哥向猫爷转账10元时不以START TRANSACTION或者BEGIN语句显式的开启一个事务,那么下边这两条语句就相当于放到两个独立的事务中去执行:
1 | UPDATE account SET balance = balance - 10 WHERE id = 1; |
当然,如果我们想关闭这种自动提交的功能,可以使用下边两种方法之一:
显式的的使用
START TRANSACTION或者BEGIN语句开启一个事务。这样在本次事务提交或者回滚前会暂时关闭掉自动提交的功能。
把系统变量
autocommit的值设置为OFF,就像这样:1
SET autocommit = OFF;
这样的话,我们写入的多条语句就算是属于同一个事务了,直到我们显式的写出
COMMIT语句来把这个事务提交掉,或者显式的写出ROLLBACK语句来把这个事务回滚掉。
1.2.5隐式提交
当我们使用START TRANSACTION或者BEGIN语句开启了一个事务,或者把系统变量autocommit的值设置为OFF时,事务就不会进行自动提交,但是如果我们输入了某些语句之后就会悄悄的提交掉,就像我们输入了COMMIT语句了一样,这种因为某些特殊的语句而导致事务提交的情况称为隐式提交,这些会导致事务隐式提交的语句包括:
定义或修改数据库对象的数据定义语言(Data definition language,缩写为:
DDL)。所谓的数据库对象,指的就是
数据库、表、视图、存储过程等等这些东西。当我们使用CREATE、ALTER、DROP等语句去修改这些所谓的数据库对象时,就会隐式的提交前边语句所属于的事务,就像这样:1
2
3
4
5
6BEGIN;
SELECT ... # 事务中的一条语句
UPDATE ... # 事务中的一条语句
CREATE TABLE ... # 此语句会隐式的提交前边语句所属于的事务隐式使用或修改
mysql数据库中的表当我们使用
ALTER USER、CREATE USER、DROP USER、GRANT、RENAME USER、REVOKE、SET PASSWORD等语句时也会隐式的提交前边语句所属于的事务。事务控制或关于锁定的语句
当我们在一个事务还没提交或者回滚时就又使用
START TRANSACTION或者BEGIN语句开启了另一个事务时,会隐式的提交上一个事务,比如这样:1
2
3
4
5
6BEGIN;
SELECT ... # 事务中的一条语句
UPDATE ... # 事务中的一条语句
BEGIN; # 此语句会隐式的提交前边语句所属于的事务或者当前的
autocommit系统变量的值为OFF,我们手动把它调为ON时,也会隐式的提交前边语句所属的事务。或者使用
LOCK TABLES、UNLOCK TABLES等关于锁定的语句也会隐式的提交前边语句所属的事务。加载数据的语句
比如我们使用
LOAD DATA语句来批量往数据库中导入数据时,也会隐式的提交前边语句所属的事务。关于
MySQL复制的一些语句使用
START SLAVE、STOP SLAVE、RESET SLAVE、CHANGE MASTER TO等语句时也会隐式的提交前边语句所属的事务。其它的一些语句
使用
ANALYZE TABLE、CACHE INDEX、CHECK TABLE、FLUSH、LOAD INDEX INTO CACHE、OPTIMIZE TABLE、REPAIR TABLE、RESET等语句也会隐式的提交前边语句所属的事务。
1.2.6保存点
如果你开启了一个事务,并且已经敲了很多语句,忽然发现上一条语句有点问题,你只好使用ROLLBACK语句来让数据库状态恢复到事务执行之前的样子,然后一切从头再来,总有一种一夜回到解放前的感觉。所以设计数据库的大叔们提出了一个保存点(英文:savepoint)的概念,就是在事务对应的数据库语句中打几个点,我们在调用ROLLBACK语句时可以指定会滚到哪个点,而不是回到最初的原点。定义保存点的语法如下:
1 | SAVEPOINT 保存点名称; |
当我们想回滚到某个保存点时,可以使用下边这个语句(下边语句中的单词WORK和SAVEPOINT是可有可无的):
1 | ROLLBACK [WORK] TO [SAVEPOINT] 保存点名称; |
不过如果ROLLBACK语句后边不跟随保存点名称的话,会直接回滚到事务执行之前的状态。
如果我们想删除某个保存点,可以使用这个语句:
1 | RELEASE SAVEPOINT 保存点名称; |
下边还是以狗哥向猫爷转账10元的例子展示一下保存点的用法,在执行完扣除狗哥账户的钱10元的语句之后打一个保存点:
1 | mysql> SELECT * FROM account; |
二、Redo日志
2.1redo日志介绍
我们知道InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。我们前边唠叨Buffer Pool的时候说过,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。但是在唠叨事务的时候又强调过一个称之为持久性的特性,就是说对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失。但是如果我们只在内存的Buffer Pool中修改了页面,假设在事务提交后突然发生了某个故障,导致内存中的数据都失效了,那么这个已经提交了的事务对数据库中所做的更改也就跟着丢失了,这是我们所不能忍受的(想想ATM机已经提示狗哥转账成功,但之后由于服务器出现故障,重启之后猫爷发现自己没收到钱,猫爷就被砍死了)。那么如何保证这个持久性呢?一个很简单的做法就是在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘,但是这个简单粗暴的做法有些问题:
刷新一个完整的数据页太浪费了
有时候我们仅仅修改了某个页面中的一个字节,但是我们知道在
InnoDB中是以页为单位来进行磁盘IO的,也就是说我们在该事务提交时不得不将一个完整的页面从内存中刷新到磁盘,我们又知道一个页面默认是16KB大小,只修改一个字节就要刷新16KB的数据到磁盘上显然是太浪费了。随机IO刷起来比较慢
一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,倒霉催的是该事务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的
Buffer Pool中的页面刷新到磁盘时,需要进行很多的随机IO,随机IO比顺序IO要慢,尤其对于传统的机械硬盘来说。
咋办呢?再次回到我们的初心:我们只是想让已经提交了的事务对数据库中数据所做的修改永久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好,比方说某个事务将系统表空间中的第100号页面中偏移量为1000处的那个字节的值1改成2我们只需要记录一下:
将第0号表空间的100号页面的偏移量为1000处的值更新为
2。
这样我们在事务提交时,把上述内容刷新到磁盘中,即使之后系统崩溃了,重启之后只要按照上述内容所记录的步骤重新更新一下数据页,那么该事务对数据库中所做的修改又可以被恢复出来,也就意味着满足持久性的要求。因为在系统崩溃重启时需要按照上述内容所记录的步骤重新更新数据页,所以上述内容也被称之为重做日志,英文名为redo log,我们也可以土洋结合,称之为redo日志。与在事务提交时将所有修改过的内存中的页面刷新到磁盘中相比,只将该事务执行过程中产生的redo日志刷新到磁盘的好处如下:
redo日志占用的空间非常小存储表空间ID、页号、偏移量以及需要更新的值所需的存储空间是很小的,关于
redo日志的格式我们稍后会详细唠叨,现在只要知道一条redo日志占用的空间不是很大就好了。redo日志是顺序写入磁盘的在执行事务的过程中,每执行一条语句,就可能产生若干条
redo日志,这些日志是按照产生的顺序写入磁盘的,也就是使用顺序IO。
2.2redo日志格式
通过上边的内容我们知道,redo日志本质上只是记录了一下事务对数据库做了哪些修改。 设计InnoDB的大叔们针对事务对数据库的不同修改场景定义了多种类型的redo日志,但是绝大部分类型的redo日志都有下边这种通用的结构:

各个部分的详细释义如下:
type:该条redo日志的类型。在
MySQL 5.7.21这个版本中,设计InnoDB的大叔一共为redo日志设计了53种不同的类型,稍后会详细介绍不同类型的redo日志。space ID:表空间ID。page number:页号。data:该条redo日志的具体内容。
2.2.1简单的redo日志类型
我们前边介绍InnoDB的记录行格式的时候说过,如果我们没有为某个表显式的定义主键,并且表中也没有定义Unique键,那么InnoDB会自动的为表添加一个称之为row_id的隐藏列作为主键。为这个row_id隐藏列赋值的方式如下:
- 服务器会在内存中维护一个全局变量,每当向某个包含隐藏的
row_id列的表中插入一条记录时,就会把该变量的值当作新记录的row_id列的值,并且把该变量自增1。 - 每当这个变量的值为256的倍数时,就会将该变量的值刷新到系统表空间的页号为
7的页面中一个称之为Max Row ID的属性处(我们前边介绍表空间结构时详细说过)。 - 当系统启动时,会将上边提到的
Max Row ID属性加载到内存中,将该值加上256之后赋值给我们前边提到的全局变量(因为在上次关机时该全局变量的值可能大于Max Row ID属性值)。
这个Max Row ID属性占用的存储空间是8个字节,当某个事务向某个包含row_id隐藏列的表插入一条记录,并且为该记录分配的row_id值为256的倍数时,就会向系统表空间页号为7的页面的相应偏移量处写入8个字节的值。但是我们要知道,这个写入实际上是在Buffer Pool中完成的,我们需要为这个页面的修改记录一条redo日志,以便在系统崩溃后能将已经提交的该事务对该页面所做的修改恢复出来。这种情况下对页面的修改是极其简单的,redo日志中只需要记录一下在某个页面的某个偏移量处修改了几个字节的值,具体被修改的内容是啥就好了,设计InnoDB的大叔把这种极其简单的redo日志称之为物理日志,并且根据在页面中写入数据的多少划分了几种不同的redo日志类型:
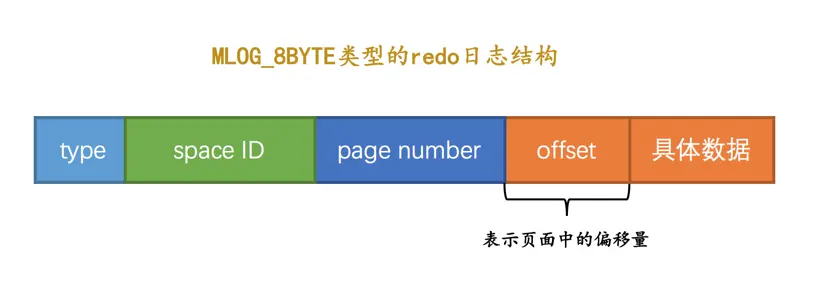
MLOG_1BYTE(type字段对应的十进制数字为1):表示在页面的某个偏移量处写入1个字节的redo日志类型。MLOG_2BYTE(type字段对应的十进制数字为2):表示在页面的某个偏移量处写入2个字节的redo日志类型。MLOG_4BYTE(type字段对应的十进制数字为4):表示在页面的某个偏移量处写入4个字节的redo日志类型。MLOG_8BYTE(type字段对应的十进制数字为8):表示在页面的某个偏移量处写入8个字节的redo日志类型。MLOG_WRITE_STRING(type字段对应的十进制数字为30):表示在页面的某个偏移量处写入一串数据。
我们上边提到的Max Row ID属性实际占用8个字节的存储空间,所以在修改页面中的该属性时,会记录一条类型为MLOG_8BYTE的redo日志,MLOG_8BYTE的redo日志结构如下所示:
其余MLOG_1BYTE、MLOG_2BYTE、MLOG_4BYTE类型的redo日志结构和MLOG_8BYTE的类似,只不过具体数据中包含对应个字节的数据罢了。MLOG_WRITE_STRING类型的redo日志表示写入一串数据,但是因为不能确定写入的具体数据占用多少字节,所以需要在日志结构中添加一个len字段:
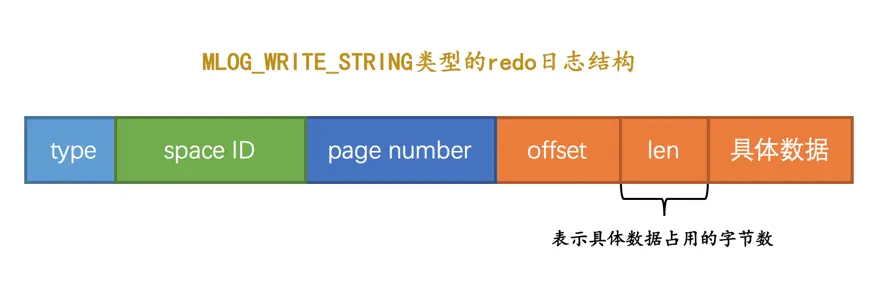
只要将MLOG_WRITE_STRING类型的redo日志的len字段填充上1、2、4、8这些数字,就可以分别替代MLOG_1BYTE、MLOG_2BYTE、MLOG_4BYTE、MLOG_8BYTE这些类型的redo日志,为啥还要多此一举设计这么多类型呢?还不是因为省空间啊,能不写len字段就不写len字段,省一个字节算一个字节。
2.2.2复杂的redo日志类型
有时候执行一条语句会修改非常多的页面,包括系统数据页面和用户数据页面(用户数据指的就是聚簇索引和二级索引对应的B+树)。以一条INSERT语句为例,它除了要向B+树的页面中插入数据,也可能更新系统数据Max Row ID的值,不过对于我们用户来说,平时更关心的是语句对B+树所做更新:
- 表中包含多少个索引,一条
INSERT语句就可能更新多少棵B+树。 - 针对某一棵
B+树来说,既可能更新叶子节点页面,也可能更新内节点页面,也可能创建新的页面(在该记录插入的叶子节点的剩余空间比较少,不足以存放该记录时,会进行页面的分裂,在内节点页面中添加目录项记录)。
在语句执行过程中,INSERT语句对所有页面的修改都得保存到redo日志中去。这句话说的比较轻巧,做起来可就比较麻烦了,比方说将记录插入到聚簇索引中时,如果定位到的叶子节点的剩余空间足够存储该记录时,那么只更新该叶子节点页面就好,那么只记录一条MLOG_WRITE_STRING类型的redo日志,表明在页面的某个偏移量处增加了哪些数据就好了么?那就too young too naive了~ 别忘了一个数据页中除了存储实际的记录之后,还有什么File Header、Page Header、Page Directory等等部分(在唠叨数据页的章节有详细讲解),所以每往叶子节点代表的数据页里插入一条记录时,还有其他很多地方会跟着更新,比如说:
- 可能更新
Page Directory中的槽信息。 Page Header中的各种页面统计信息,比如PAGE_N_DIR_SLOTS表示的槽数量可能会更改,PAGE_HEAP_TOP代表的还未使用的空间最小地址可能会更改,PAGE_N_HEAP代表的本页面中的记录数量可能会更改,吧啦吧啦,各种信息都可能会被修改。- 我们知道在数据页里的记录是按照索引列从小到大的顺序组成一个单向链表的,每插入一条记录,还需要更新上一条记录的记录头信息中的
next_record属性来维护这个单向链表。 - 还有别的吧啦吧啦的更新的地方,就不一一唠叨了…
画一个简易的示意图就像是这样:
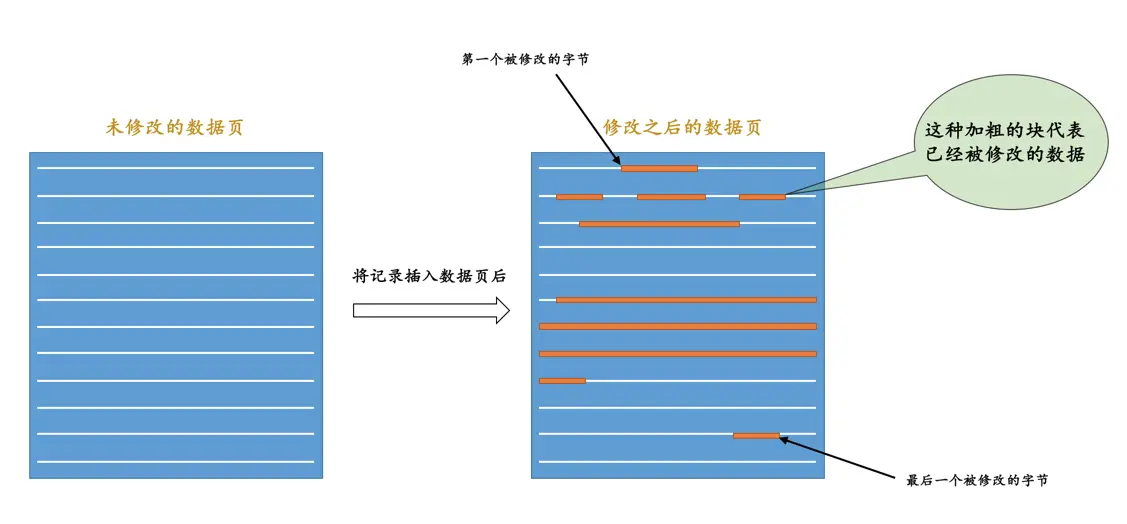
说了这么多,就是想表达:把一条记录插入到一个页面时需要更改的地方非常多。这时我们如果使用上边介绍的简单的物理redo日志来记录这些修改时,可以有两种解决方案:
方案一:在每个修改的地方都记录一条
redo日志。也就是如上图所示,有多少个加粗的块,就写多少条物理
redo日志。这样子记录redo日志的缺点是显而易见的,因为被修改的地方是在太多了,可能记录的redo日志占用的空间都比整个页面占用的空间都多了~方案二:将整个页面的
第一个被修改的字节到最后一个修改的字节之间所有的数据当成是一条物理redo日志中的具体数据。从图中也可以看出来,
第一个被修改的字节到最后一个修改的字节之间仍然有许多没有修改过的数据,我们把这些没有修改的数据也加入到redo日志中去岂不是太浪费了~
正因为上述两种使用物理redo日志的方式来记录某个页面中做了哪些修改比较浪费,设计InnoDB的大叔本着勤俭节约的初心,提出了一些新的redo日志类型,比如:
MLOG_REC_INSERT(对应的十进制数字为9):表示插入一条使用非紧凑行格式的记录时的redo日志类型。
Redundant是一种比较原始的行格式,它就是非紧凑的。而Compact、Dynamic以及Compressed行格式是较新的行格式,它们是紧凑的(占用更小的存储空间)。
MLOG_COMP_REC_INSERT(对应的十进制数字为38):表示插入一条使用紧凑行格式的记录时的redo日志类型。MLOG_COMP_PAGE_CREATE(type字段对应的十进制数字为58):表示创建一个存储紧凑行格式记录的页面的redo日志类型。MLOG_COMP_REC_DELETE(type字段对应的十进制数字为42):表示删除一条使用紧凑行格式记录的redo日志类型。MLOG_COMP_LIST_START_DELETE(type字段对应的十进制数字为44):表示从某条给定记录开始删除页面中的一系列使用紧凑行格式记录的redo日志类型。MLOG_COMP_LIST_END_DELETE(type字段对应的十进制数字为43):与MLOG_COMP_LIST_START_DELETE类型的redo日志呼应,表示删除一系列记录直到MLOG_COMP_LIST_END_DELETE类型的redo日志对应的记录为止。
我们前边唠叨InnoDB数据页格式的时候重点强调过,数据页中的记录是按照索引列大小的顺序组成单向链表的。有时候我们会有删除索引列的值在某个区间范围内的所有记录的需求,这时候如果我们每删除一条记录就写一条redo日志的话,效率可能有点低,所以提出MLOG_COMP_LIST_START_DELETE和MLOG_COMP_LIST_END_DELETE类型的redo日志,可以很大程度上减少redo日志的条数。
这些类型的redo日志既包含物理层面的意思,也包含逻辑层面的意思,具体指:
- 物理层面看,这些日志都指明了对哪个表空间的哪个页进行了修改。
- 逻辑层面看,在系统崩溃重启时,并不能直接根据这些日志里的记载,将页面内的某个偏移量处恢复成某个数据,而是需要调用一些事先准备好的函数,执行完这些函数后才可以将页面恢复成系统崩溃前的样子。
大家看到这可能有些懵逼,我们还是以类型为MLOG_COMP_REC_INSERT这个代表插入一条使用紧凑行格式的记录时的redo日志为例来理解一下我们上边所说的物理层面和逻辑层面到底是个啥意思。废话少说,直接看一下这个类型为MLOG_COMP_REC_INSERT的redo日志的结构(由于字段太多了,我们把它们竖着看效果好些):
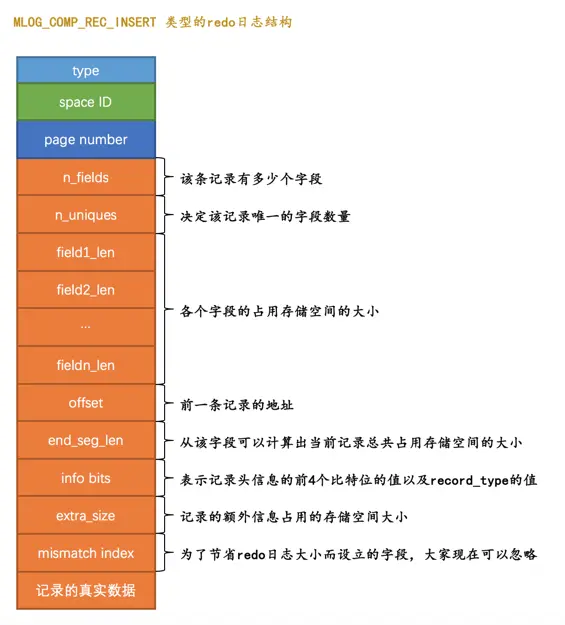
这个类型为MLOG_COMP_REC_INSERT的redo日志结构有几个地方需要大家注意:
- 我们前边在唠叨索引的时候说过,在一个数据页里,不论是叶子节点还是非叶子节点,记录都是按照索引列从小到大的顺序排序的。对于二级索引来说,当索引列的值相同时,记录还需要按照主键值进行排序。图中
n_uniques的值的含义是在一条记录中,需要几个字段的值才能确保记录的唯一性,这样当插入一条记录时就可以按照记录的前n_uniques个字段进行排序。对于聚簇索引来说,n_uniques的值为主键的列数,对于其他二级索引来说,该值为索引列数+主键列数。这里需要注意的是,唯一二级索引的值可能为NULL,所以该值仍然为索引列数+主键列数。 field1_len ~ fieldn_len代表着该记录若干个字段占用存储空间的大小,需要注意的是,这里不管该字段的类型是固定长度大小的(比如INT),还是可变长度大小(比如VARCHAR(M))的,该字段占用的大小始终要写入redo日志中。offset代表的是该记录的前一条记录在页面中的地址。为啥要记录前一条记录的地址呢?这是因为每向数据页插入一条记录,都需要修改该页面中维护的记录链表,每条记录的记录头信息中都包含一个称为next_record的属性,所以在插入新记录时,需要修改前一条记录的next_record属性。- 我们知道一条记录其实由
额外信息和真实数据这两部分组成,这两个部分的总大小就是一条记录占用存储空间的总大小。通过end_seg_len的值可以间接的计算出一条记录占用存储空间的总大小,为啥不直接存储一条记录占用存储空间的总大小呢?这是因为写redo日志是一个非常频繁的操作,设计InnoDB的大叔想方设法想减小redo日志本身占用的存储空间大小,所以想了一些弯弯绕的算法来实现这个目标,end_seg_len这个字段就是为了节省redo日志存储空间而提出来的。至于具体设计InnoDB的大叔到底是用了什么神奇魔法减小redo日志大小的,我们这就不多唠叨了,因为的确有那么一丢丢小复杂,说清楚还是有一点点麻烦的,而且说明白了也没啥用。 mismatch_index的值也是为了节省redo日志的大小而设立的,大家可以忽略。
很显然这个类型为MLOG_COMP_REC_INSERT的redo日志并没有记录PAGE_N_DIR_SLOTS的值修改为了啥,PAGE_HEAP_TOP的值修改为了啥,PAGE_N_HEAP的值修改为了啥等等这些信息,而只是把在本页面中插入一条记录所有必备的要素记了下来,之后系统崩溃重启时,服务器会调用相关向某个页面插入一条记录的那个函数,而redo日志中的那些数据就可以被当成是调用这个函数所需的参数,在调用完该函数后,页面中的PAGE_N_DIR_SLOTS、PAGE_HEAP_TOP、PAGE_N_HEAP等等的值也就都被恢复到系统崩溃前的样子了。这就是所谓的逻辑日志的意思。
为了节省redo日志占用的存储空间大小,设计InnoDB的大叔对redo日志中的某些数据还可能进行压缩处理,比方说space ID和page number一般占用4个字节来存储,但是经过压缩后,可能使用更小的空间来存储。具体压缩算法就不唠叨了。
2.3Mini-Transaction
2.3.1以组的形式写入redo日志
语句在执行过程中可能修改若干个页面。比如我们前边说的一条INSERT语句可能修改系统表空间页号为7的页面的Max Row ID属性(当然也可能更新别的系统页面,只不过我们没有都列举出来而已),还会更新聚簇索引和二级索引对应B+树中的页面。由于对这些页面的更改都发生在Buffer Pool中,所以在修改完页面之后,需要记录一下相应的redo日志。在执行语句的过程中产生的redo日志被设计InnoDB的大叔人为的划分成了若干个不可分割的组,比如:
- 更新
Max Row ID属性时产生的redo日志是不可分割的。 - 向聚簇索引对应
B+树的页面中插入一条记录时产生的redo日志是不可分割的。 - 向某个二级索引对应
B+树的页面中插入一条记录时产生的redo日志是不可分割的。 - 还有其他的一些对页面的访问操作时产生的
redo日志是不可分割的。。。
怎么理解这个不可分割的意思呢?我们以向某个索引对应的B+树插入一条记录为例,在向B+树中插入这条记录之前,需要先定位到这条记录应该被插入到哪个叶子节点代表的数据页中,定位到具体的数据页之后,有两种可能的情况:
情况一:该数据页的剩余的空闲空间充足,足够容纳这一条待插入记录,那么事情很简单,直接把记录插入到这个数据页中,记录一条类型为
MLOG_COMP_REC_INSERT的redo日志就好了,我们把这种情况称之为乐观插入。假如某个索引对应的B+树长这样: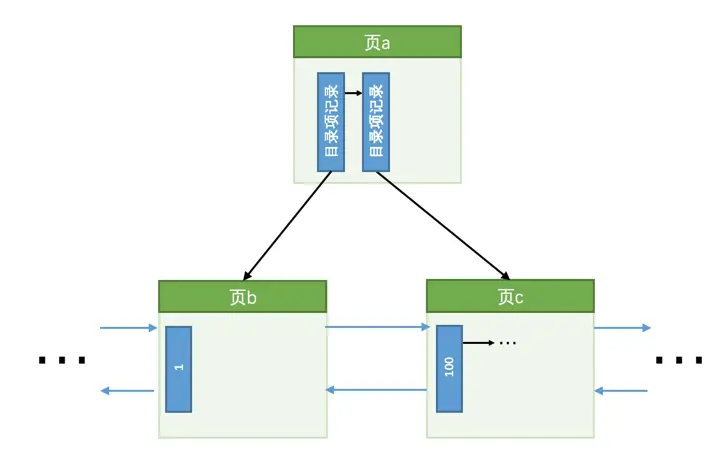
现在我们要插入一条键值为
10的记录,很显然需要被插入到页b中,由于页b现在有足够的空间容纳一条记录,所以直接将该记录插入到页b中就好了,就像这样: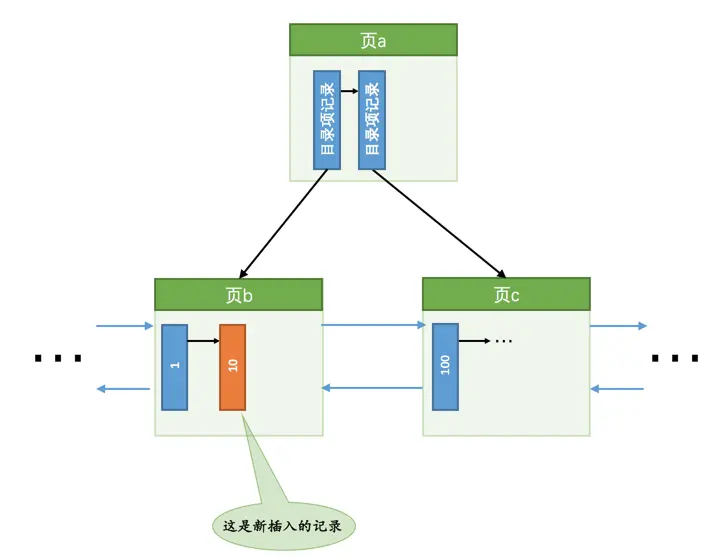
情况二:该数据页剩余的空闲空间不足,那么事情就悲剧了,我们前边说过,遇到这种情况要进行所谓的
页分裂操作,也就是新建一个叶子节点,然后把原先数据页中的一部分记录复制到这个新的数据页中,然后再把记录插入进去,把这个叶子节点插入到叶子节点链表中,最后还要在内节点中添加一条目录项记录指向这个新创建的页面。很显然,这个过程要对多个页面进行修改,也就意味着会产生多条redo日志,我们把这种情况称之为悲观插入。假如某个索引对应的B+树长这样: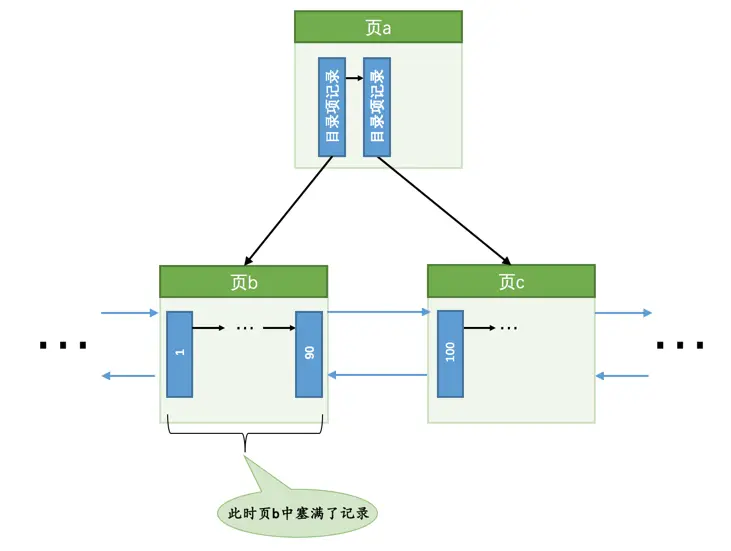
现在我们要插入一条键值为
10的记录,很显然需要被插入到页b中,但是从图中也可以看出来,此时页b已经塞满了记录,没有更多的空闲空间来容纳这条新记录了,所以我们需要进行页面的分裂操作,就像这样: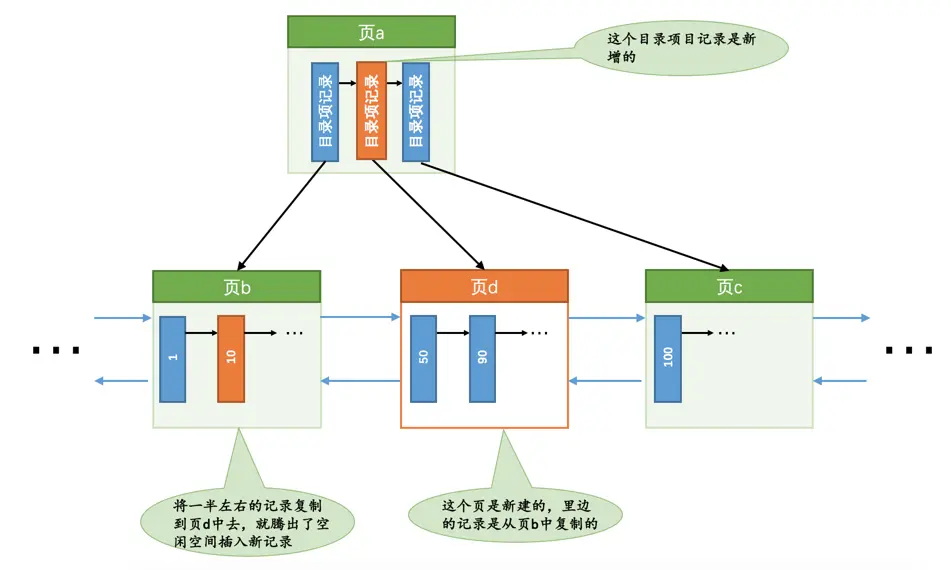
如果作为内节点的
页a的剩余空闲空间也不足以容纳增加一条目录项记录,那需要继续做内节点页a的分裂操作,也就意味着会修改更多的页面,从而产生更多的redo日志。另外,对于悲观插入来说,由于需要新申请数据页,还需要改动一些系统页面,比方说要修改各种段、区的统计信息信息,各种链表的统计信息(比如什么FREE链表、FSP_FREE_FRAG链表吧啦吧啦我们在唠叨表空间那一章中介绍过的各种东东)等等等等,反正总共需要记录的redo日志有二、三十条。
设计InnoDB的大叔们认为向某个索引对应的B+树中插入一条记录的这个过程必须是原子的,不能说插了一半之后就停止了。比方说在悲观插入过程中,新的页面已经分配好了,数据也复制过去了,新的记录也插入到页面中了,可是没有向内节点中插入一条目录项记录,这个插入过程就是不完整的,这样会形成一棵不正确的B+树。我们知道redo日志是为了在系统崩溃重启时恢复崩溃前的状态,如果在悲观插入的过程中只记录了一部分redo日志,那么在系统崩溃重启时会将索引对应的B+树恢复成一种不正确的状态,这是设计InnoDB的大叔们所不能忍受的。所以他们规定在执行这些需要保证原子性的操作时必须以组的形式来记录的redo日志,在进行系统崩溃重启恢复时,针对某个组中的redo日志,要么把全部的日志都恢复掉,要么一条也不恢复。怎么做到的呢?这得分情况讨论:
有的需要保证原子性的操作会生成多条
redo日志,比如向某个索引对应的B+树中进行一次悲观插入就需要生成许多条redo日志。如何把这些
redo日志划分到一个组里边儿呢?设计InnoDB的大叔做了一个很简单的小把戏,就是在该组中的最后一条redo日志后边加上一条特殊类型的redo日志,该类型名称为MLOG_MULTI_REC_END,type字段对应的十进制数字为31,该类型的redo日志结构很简单,只有一个type字段:
所以某个需要保证原子性的操作产生的一系列
redo日志必须要以一个类型为MLOG_MULTI_REC_END结尾,就像这样: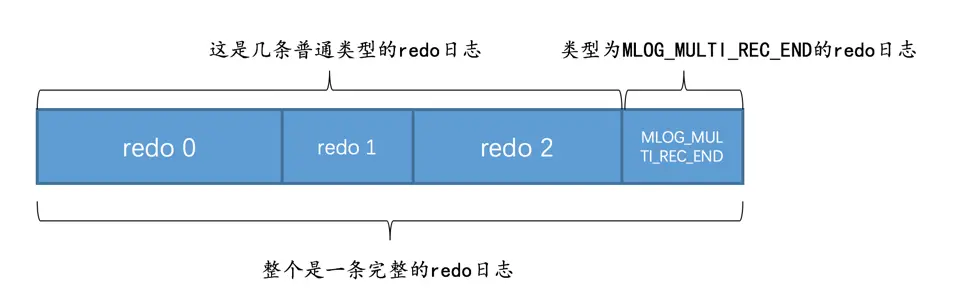
这样在系统崩溃重启进行恢复时,只有当解析到类型为
MLOG_MULTI_REC_END的redo日志,才认为解析到了一组完整的redo日志,才会进行恢复。否则的话直接放弃前边解析到的redo日志。有的需要保证原子性的操作只生成一条
redo日志,比如更新Max Row ID属性的操作就只会生成一条redo日志。其实在一条日志后边跟一个类型为
MLOG_MULTI_REC_END的redo日志也是可以的,不过设计InnoDB的大叔比较勤俭节约,他们不想浪费一个比特位。别忘了虽然redo日志的类型比较多,但撑死了也就是几十种,是小于127这个数字的,也就是说我们用7个比特位就足以包括所有的redo日志类型,而type字段其实是占用1个字节的,也就是说我们可以省出来一个比特位用来表示该需要保证原子性的操作只产生单一的一条redo日志,示意图如下: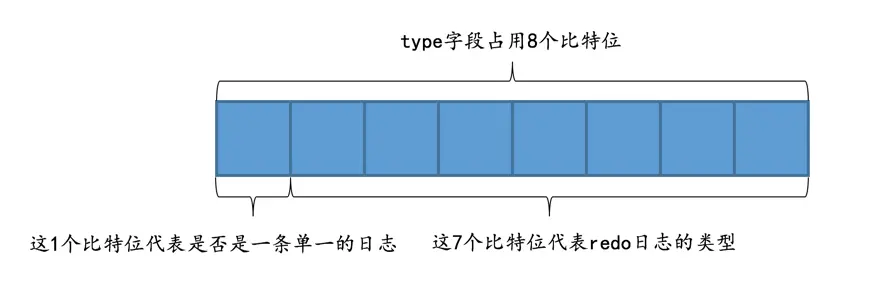
如果
type字段的第一个比特位为1,代表该需要保证原子性的操作只产生了单一的一条redo日志,否则表示该需要保证原子性的操作产生了一系列的redo日志。
2.3.2Mini-Transaction的概念
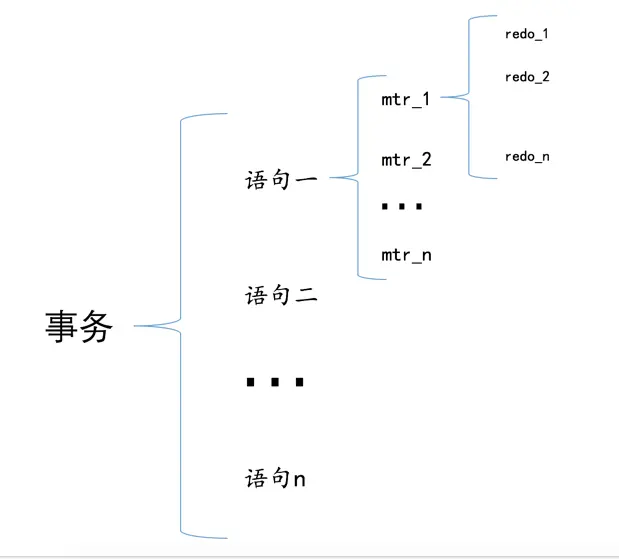
设计MySQL的大叔把对底层页面中的一次原子访问的过程称之为一个Mini-Transaction,简称mtr,比如上边所说的修改一次Max Row ID的值算是一个Mini-Transaction,向某个索引对应的B+树中插入一条记录的过程也算是一个Mini-Transaction。通过上边的叙述我们也知道,一个所谓的mtr可以包含一组redo日志,在进行崩溃恢复时这一组redo日志作为一个不可分割的整体。
一个事务可以包含若干条语句,每一条语句其实是由若干个mtr组成,每一个mtr又可以包含若干条redo日志,画个图表示它们的关系就是这样:
2.4redo日志的写入过程
2.4.1redo log block
设计InnoDB的大叔为了更好的进行系统崩溃恢复,他们把通过mtr生成的redo日志都放在了大小为512字节的页中。为了和我们前边提到的表空间中的页做区别,我们这里把用来存储redo日志的页称为block(你心里清楚页和block的意思其实差不多就行了)。一个redo log block的示意图如下:
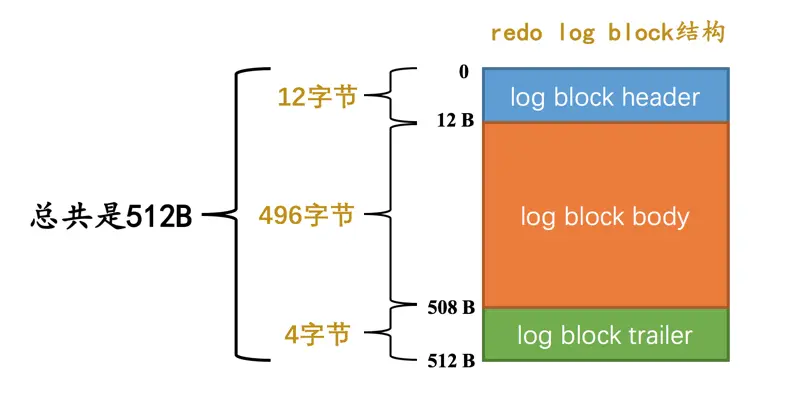
真正的redo日志都是存储到占用496字节大小的log block body中,图中的log block header和log block trailer存储的是一些管理信息。我们来看看这些所谓的管理信息都是啥:
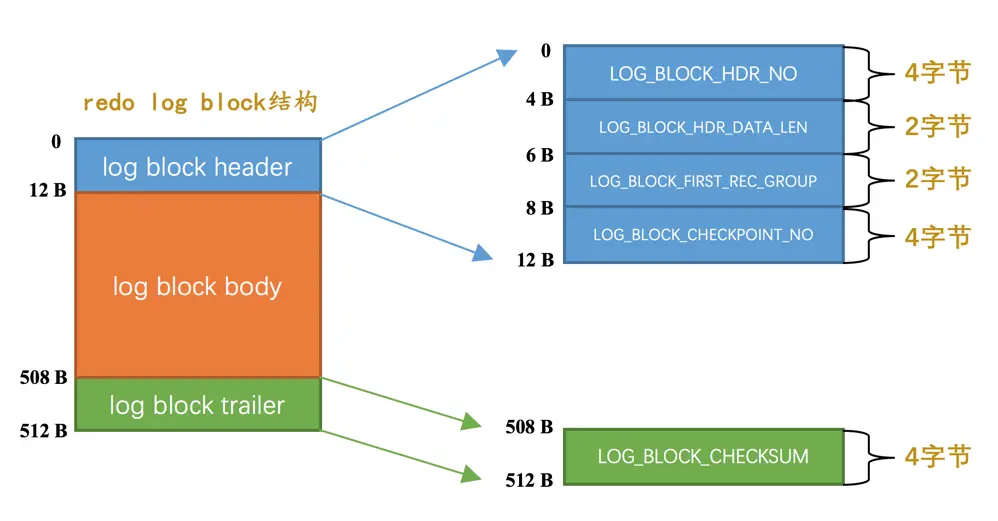
其中log block header的几个属性的意思分别如下:
LOG_BLOCK_HDR_NO:每一个block都有一个大于0的唯一标号,本属性就表示该标号值。LOG_BLOCK_HDR_DATA_LEN:表示block中已经使用了多少字节,初始值为12(因为log block body从第12个字节处开始)。随着往block中写入的redo日志越来也多,本属性值也跟着增长。如果log block body已经被全部写满,那么本属性的值被设置为512。LOG_BLOCK_FIRST_REC_GROUP:一条redo日志也可以称之为一条redo日志记录(redo log record),一个mtr会生产多条redo日志记录,这些redo日志记录被称之为一个redo日志记录组(redo log record group)。LOG_BLOCK_FIRST_REC_GROUP就代表该block中第一个mtr生成的redo日志记录组的偏移量(其实也就是这个block里第一个mtr生成的第一条redo日志的偏移量)。LOG_BLOCK_CHECKPOINT_NO:表示所谓的checkpoint的序号,checkpoint是我们后续内容的重点,现在先不用清楚它的意思,稍安勿躁。
log block trailer中属性的意思如下:
LOG_BLOCK_CHECKSUM:表示block的校验值,用于正确性校验,我们暂时不关心它。
2.4.2redo日志缓冲区
我们前边说过,设计InnoDB的大叔为了解决磁盘速度过慢的问题而引入了Buffer Pool。同理,写入redo日志时也不能直接直接写到磁盘上,实际上在服务器启动时就向操作系统申请了一大片称之为redo log buffer的连续内存空间,翻译成中文就是redo日志缓冲区,我们也可以简称为log buffer。这片内存空间被划分成若干个连续的redo log block,就像这样:
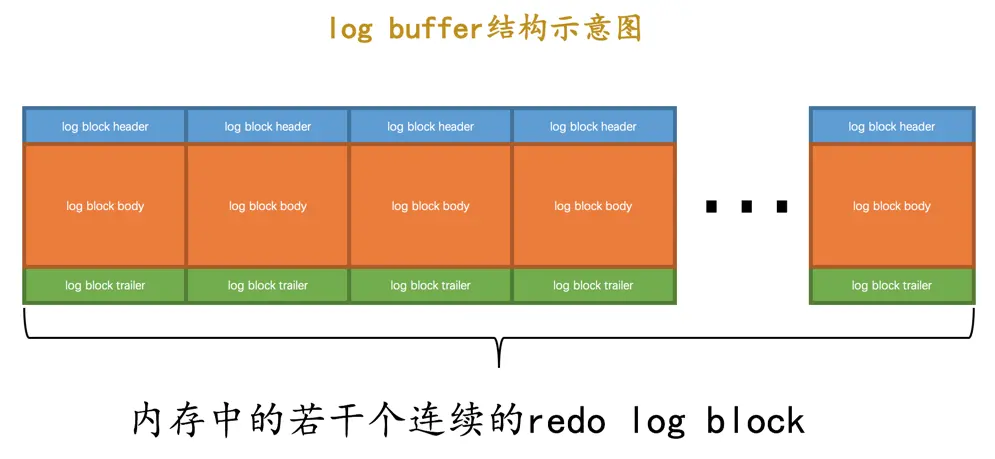
我们可以通过启动参数innodb_log_buffer_size来指定log buffer的大小,在MySQL 5.7.21这个版本中,该启动参数的默认值为16MB。
2.4.3redo日志写入log buffer
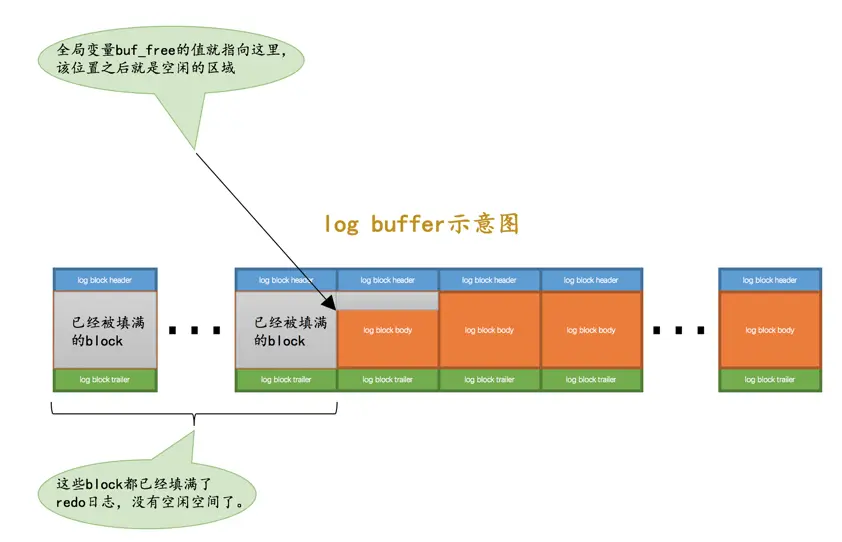
向log buffer中写入redo日志的过程是顺序的,也就是先往前边的block中写,当该block的空闲空间用完之后再往下一个block中写。当我们想往log buffer中写入redo日志时,第一个遇到的问题就是应该写在哪个block的哪个偏移量处,所以设计InnoDB的大叔特意提供了一个称之为buf_free的全局变量,该变量指明后续写入的redo日志应该写入到log buffer中的哪个位置,如图所示:
我们前边说过一个mtr执行过程中可能产生若干条redo日志,这些redo日志是一个不可分割的组,所以其实并不是每生成一条redo日志,就将其插入到log buffer中,而是每个mtr运行过程中产生的日志先暂时存到一个地方,当该mtr结束的时候,将过程中产生的一组redo日志再全部复制到log buffer中。我们现在假设有两个名为T1、T2的事务,每个事务都包含2个mtr,我们给这几个mtr命名一下:
- 事务
T1的两个mtr分别称为mtr_T1_1和mtr_T1_2。 - 事务
T2的两个mtr分别称为mtr_T2_1和mtr_T2_2。
每个mtr都会产生一组redo日志,用示意图来描述一下这些mtr产生的日志情况:
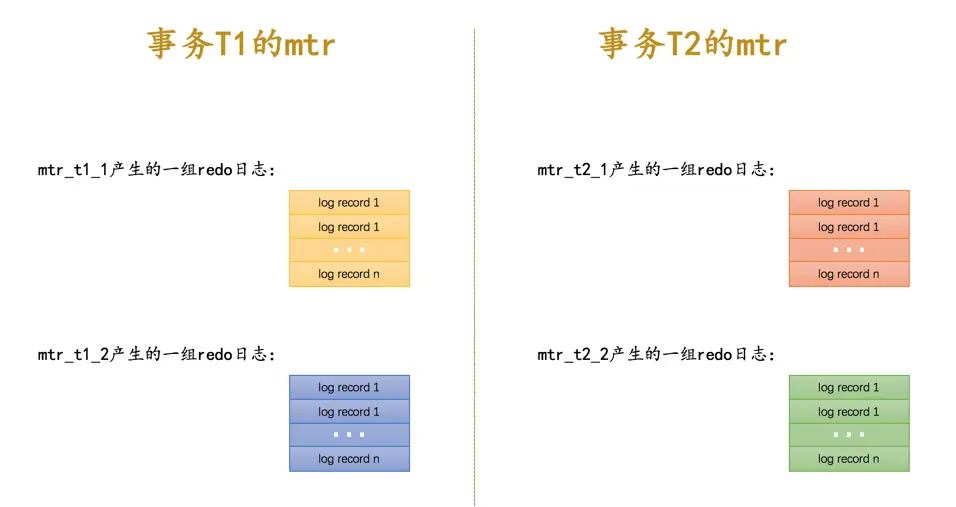
不同的事务可能是并发执行的,所以T1、T2之间的mtr可能是交替执行的。每当一个mtr执行完成时,伴随该mtr生成的一组redo日志就需要被复制到log buffer中,也就是说不同事务的mtr可能是交替写入log buffer的,我们画个示意图(为了美观,我们把一个mtr中产生的所有的redo日志当作一个整体来画):
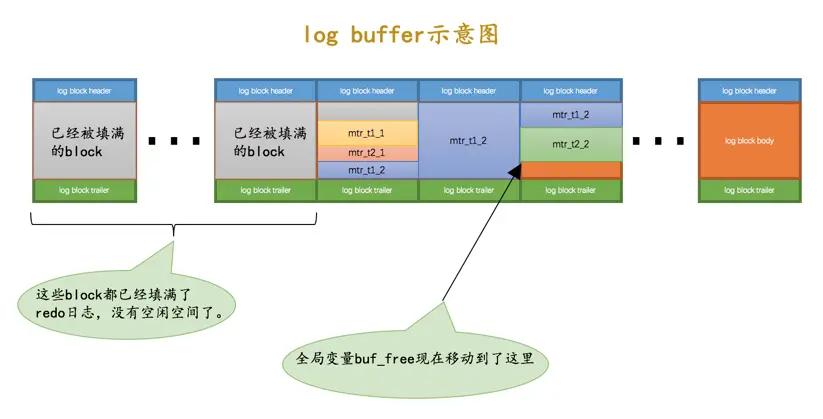
从示意图中我们可以看出来,不同的mtr产生的一组redo日志占用的存储空间可能不一样,有的mtr产生的redo日志量很少,比如mtr_t1_1、mtr_t2_1就被放到同一个block中存储,有的mtr产生的redo日志量非常大,比如mtr_t1_2产生的redo日志甚至占用了3个block来存储。
2.5redo日志文件
2.5.1redo日志刷盘时机
我们前边说mtr运行过程中产生的一组redo日志在mtr结束时会被复制到log buffer中,可是这些日志总在内存里呆着也不是个办法,在一些情况下它们会被刷新到磁盘里,比如:
log buffer空间不足时log buffer的大小是有限的(通过系统变量innodb_log_buffer_size指定),如果不停的往这个有限大小的log buffer里塞入日志,很快它就会被填满。设计InnoDB的大叔认为如果当前写入log buffer的redo日志量已经占满了log buffer总容量的大约一半左右,就需要把这些日志刷新到磁盘上。事务提交时
我们前边说过之所以使用
redo日志主要是因为它占用的空间少,还是顺序写,在事务提交时可以不把修改过的Buffer Pool页面刷新到磁盘,但是为了保证持久性,必须要把修改这些页面对应的redo日志刷新到磁盘。将某个脏页刷新到磁盘前,会保证先将该脏页对应的 redo 日志刷新到磁盘中(再一次强调,redo 日志是顺序刷新的,所以在将某个脏页对应的 redo 日志从 redo log buffer 刷新到磁盘时,也会保证将在其之前产生的 redo 日志也刷新到磁盘)。
后台线程不停的刷刷刷
后台有一个线程,大约每秒都会刷新一次
log buffer中的redo日志到磁盘。正常关闭服务器时
做所谓的
checkpoint时(我们现在没介绍过checkpoint的概念,稍后会仔细唠叨,稍安勿躁)其他的一些情况…
2.5.2redo日志文件组
MySQL的数据目录(使用SHOW VARIABLES LIKE 'datadir'查看)下默认有两个名为ib_logfile0和ib_logfile1的文件,log buffer中的日志默认情况下就是刷新到这两个磁盘文件中。如果我们对默认的redo日志文件不满意,可以通过下边几个启动参数来调节:
innodb_log_group_home_dir该参数指定了
redo日志文件所在的目录,默认值就是当前的数据目录。innodb_log_file_size该参数指定了每个
redo日志文件的大小,在MySQL 5.7.21这个版本中的默认值为48MB,innodb_log_files_in_group该参数指定
redo日志文件的个数,默认值为2,最大值为100。
从上边的描述中可以看到,磁盘上的redo日志文件不只一个,而是以一个日志文件组的形式出现的。这些文件以ib_logfile[数字](数字可以是0、1、2…)的形式进行命名。在将redo日志写入日志文件组时,是从ib_logfile0开始写,如果ib_logfile0写满了,就接着ib_logfile1写,同理,ib_logfile1写满了就去写ib_logfile2,依此类推。如果写到最后一个文件该咋办?那就重新转到ib_logfile0继续写,所以整个过程如下图所示:
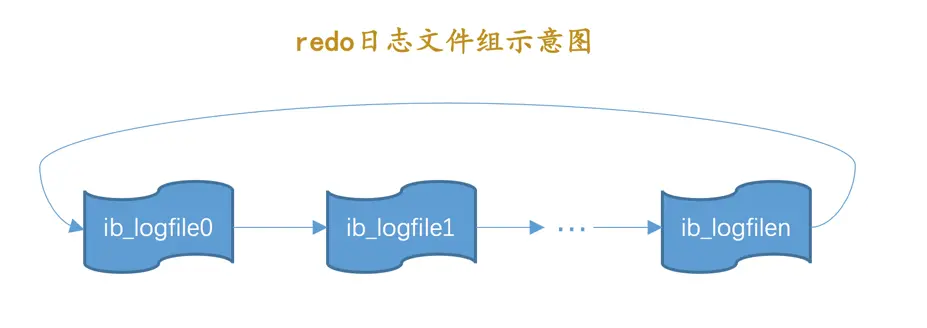
总共的redo日志文件大小其实就是:innodb_log_file_size × innodb_log_files_in_group。
如果采用循环使用的方式向redo日志文件组里写数据的话,那岂不是要追尾,也就是后写入的redo日志覆盖掉前边写的redo日志?当然可能了!所以设计InnoDB的大叔提出了checkpoint的概念,稍后我们重点唠叨~
2.5.3redo日志文件格式
我们前边说过log buffer本质上是一片连续的内存空间,被划分成了若干个512字节大小的block。将log buffer中的redo日志刷新到磁盘的本质就是把block的镜像写入日志文件中,所以redo日志文件其实也是由若干个512字节大小的block组成。
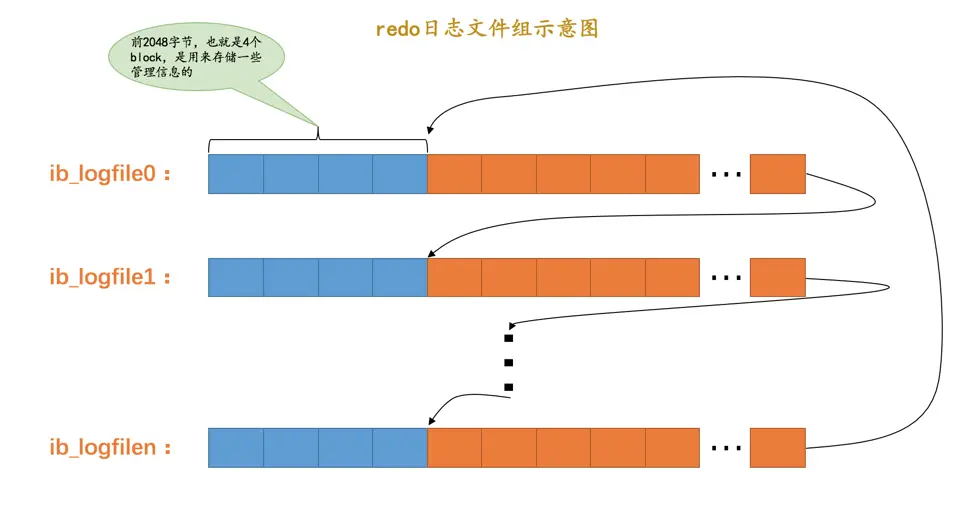
redo日志文件组中的每个文件大小都一样,格式也一样,都是由两部分组成:
- 前2048个字节,也就是前4个block是用来存储一些管理信息的。
- 从第2048字节往后是用来存储
log buffer中的block镜像的。
所以我们前边所说的循环使用redo日志文件,其实是从每个日志文件的第2048个字节开始算,画个示意图就是这样:
普通block的格式我们在唠叨log buffer的时候都说过了,就是log block header、log block body、log block trialer这三个部分,就不重复介绍了。这里需要介绍一下每个redo日志文件前2048个字节,也就是前4个特殊block的格式都是干嘛的,废话少说,先看图:

从图中可以看出来,这4个block分别是:
log file header:描述该redo日志文件的一些整体属性,看一下它的结构: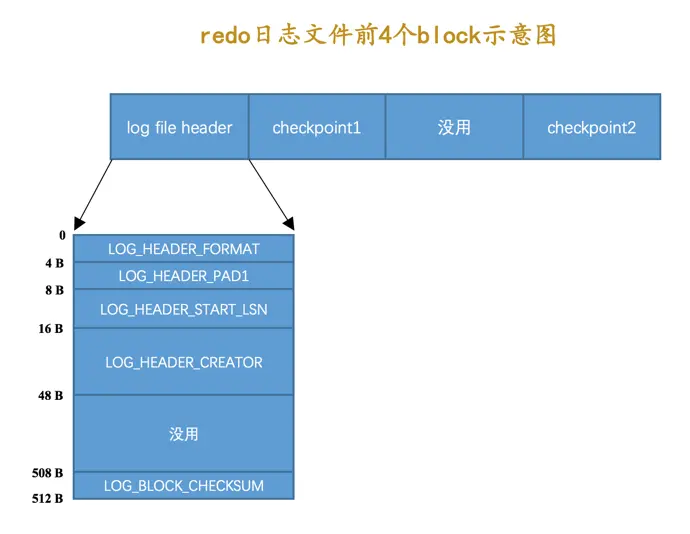

checkpoint1:记录关于checkpoint的一些属性,看一下它的结构: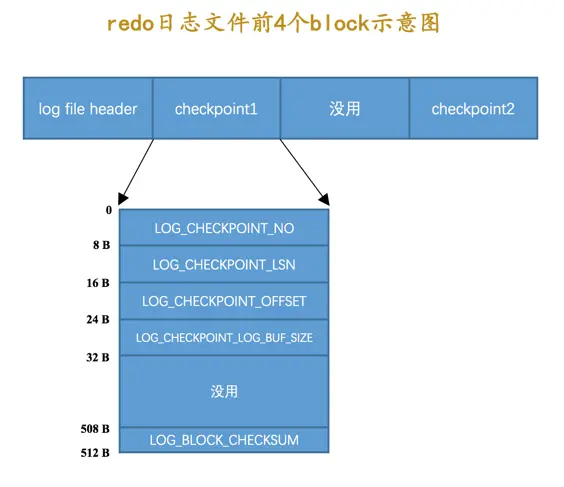
第三个block未使用,忽略~
checkpoint2:结构和checkpoint1一样。
2.6Log Sequence Number
自系统开始运行,就不断的在修改页面,也就意味着会不断的生成redo日志。redo日志的量在不断的递增,就像人的年龄一样,自打出生起就不断递增,永远不可能缩减了。设计InnoDB的大叔为记录已经写入的redo日志量,设计了一个称之为Log Sequence Number的全局变量,翻译过来就是:日志序列号,简称lsn。不过不像人一出生的年龄是0岁,设计InnoDB的大叔规定初始的lsn值为8704(也就是一条redo日志也没写入时,lsn的值为8704)。
我们知道在向log buffer中写入redo日志时不是一条一条写入的,而是以一个mtr生成的一组redo日志为单位进行写入的。而且实际上是把日志内容写在了log block body处。但是在统计lsn的增长量时,是按照实际写入的日志量加上占用的log block header和log block trailer来计算的。我们来看一个例子:
系统第一次启动后初始化
log buffer时,buf_free(就是标记下一条redo日志应该写入到log buffer的位置的变量)就会指向第一个block的偏移量为12字节(log block header的大小)的地方,那么lsn值也会跟着增加12: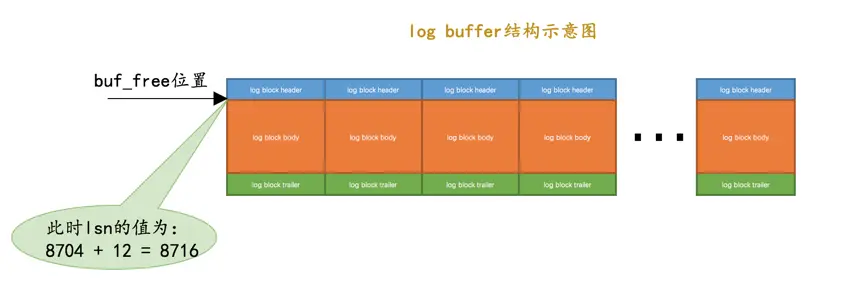
如果某个
mtr产生的一组redo日志占用的存储空间比较小,也就是待插入的block剩余空闲空间能容纳这个mtr提交的日志时,lsn增长的量就是该mtr生成的redo日志占用的字节数,就像这样: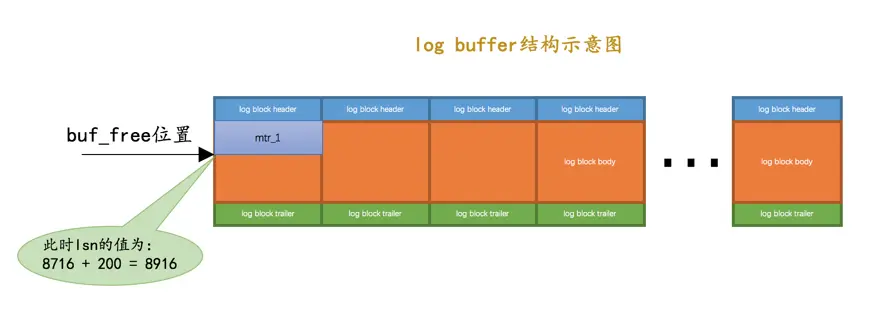
我们假设上图中
mtr_1产生的redo日志量为200字节,那么lsn就要在8716的基础上增加200,变为8916。如果某个
mtr产生的一组redo日志占用的存储空间比较大,也就是待插入的block剩余空闲空间不足以容纳这个mtr提交的日志时,lsn增长的量就是该mtr生成的redo日志占用的字节数加上额外占用的log block header和log block trailer的字节数,就像这样: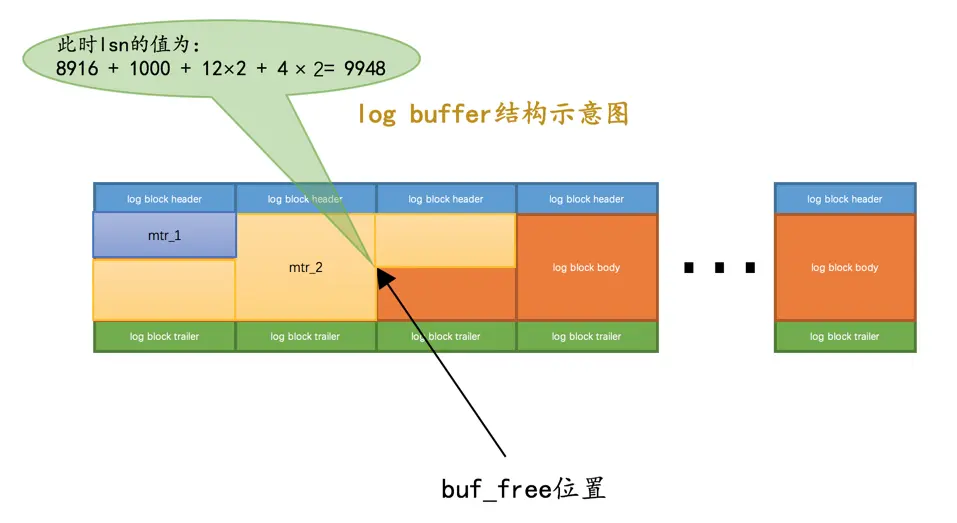
我们假设上图中
mtr_2产生的redo日志量为1000字节,为了将mtr_2产生的redo日志写入log buffer,我们不得不额外多分配两个block,所以lsn的值需要在8916的基础上增加1000 + 12×2 + 4 × 2 = 1032。
从上边的描述中可以看出来,每一组由mtr生成的redo日志都有一个唯一的LSN值与其对应,LSN值越小,说明redo日志产生的越早。
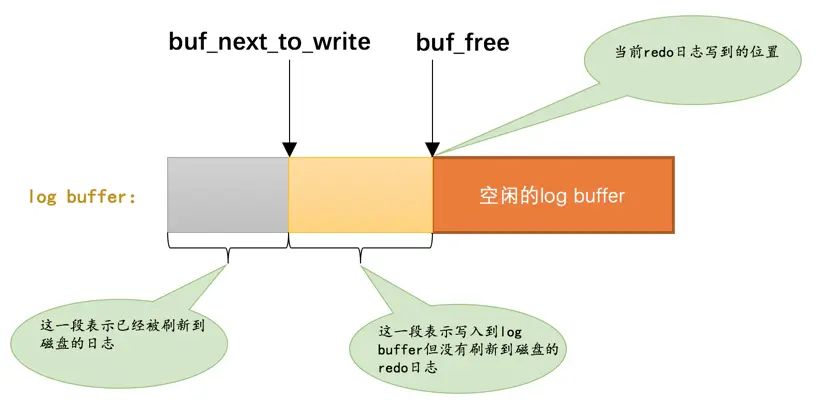
2.6.1flushed_to_disk_lsn
redo日志是首先写到log buffer中,之后才会被刷新到磁盘上的redo日志文件。所以设计InnoDB的大叔提出了一个称之为buf_next_to_write的全局变量,标记当前log buffer中已经有哪些日志被刷新到磁盘中了。画个图表示就是这样:
我们前边说lsn是表示当前系统中写入的redo日志量,这包括了写到log buffer而没有刷新到磁盘的日志,相应的,设计InnoDB的大叔提出了一个表示刷新到磁盘中的redo日志量的全局变量,称之为flushed_to_disk_lsn。系统第一次启动时,该变量的值和初始的lsn值是相同的,都是8704。随着系统的运行,redo日志被不断写入log buffer,但是并不会立即刷新到磁盘,lsn的值就和flushed_to_disk_lsn的值拉开了差距。我们演示一下:
系统第一次启动后,向
log buffer中写入了mtr_1、mtr_2、mtr_3这三个mtr产生的redo日志,假设这三个mtr开始和结束时对应的lsn值分别是:mtr_1:8716 ~ 8916mtr_2:8916 ~ 9948mtr_3:9948 ~ 10000
此时的
lsn已经增长到了10000,但是由于没有刷新操作,所以此时flushed_to_disk_lsn的值仍为8704,如图: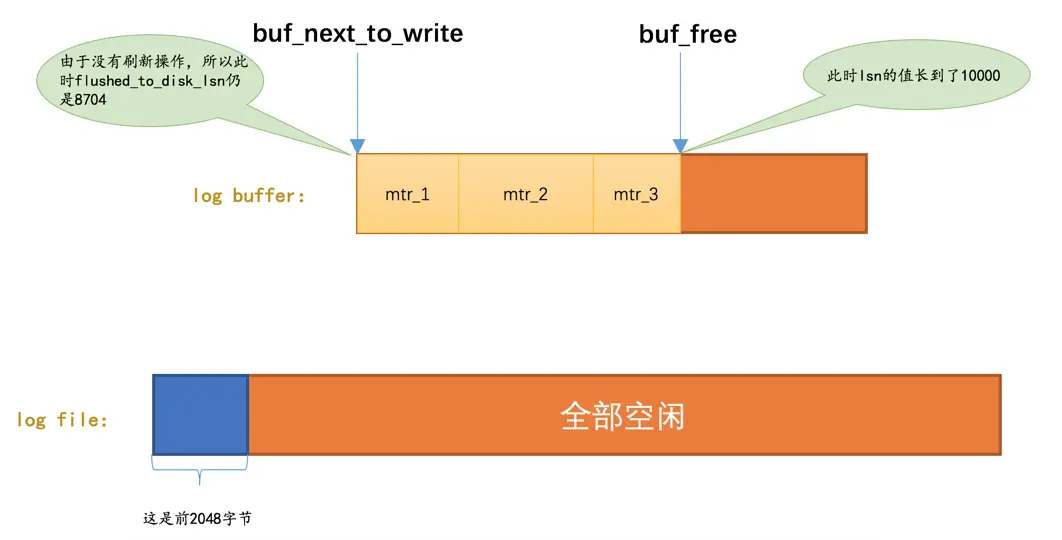
随后进行将
log buffer中的block刷新到redo日志文件的操作,假设将mtr_1和mtr_2的日志刷新到磁盘,那么flushed_to_disk_lsn就应该增长mtr_1和mtr_2写入的日志量,所以flushed_to_disk_lsn的值增长到了9948,如图: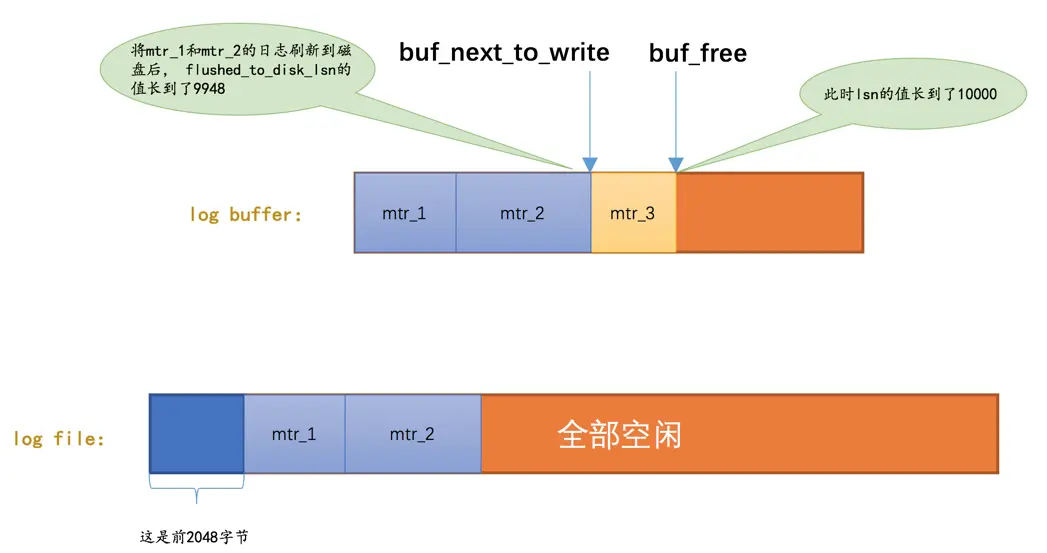
综上所述,当有新的redo日志写入到log buffer时,首先lsn的值会增长,但flushed_to_disk_lsn不变,随后随着不断有log buffer中的日志被刷新到磁盘上,flushed_to_disk_lsn的值也跟着增长。如果两者的值相同时,说明log buffer中的所有redo日志都已经刷新到磁盘中了。
2.6.2lsn值和redo日志文件偏移量的对应关系
因为lsn的值是代表系统写入的redo日志量的一个总和,一个mtr中产生多少日志,lsn的值就增加多少(当然有时候要加上log block header和log block trailer的大小),这样mtr产生的日志写到磁盘中时,很容易计算某一个lsn值在redo日志文件组中的偏移量,如图:
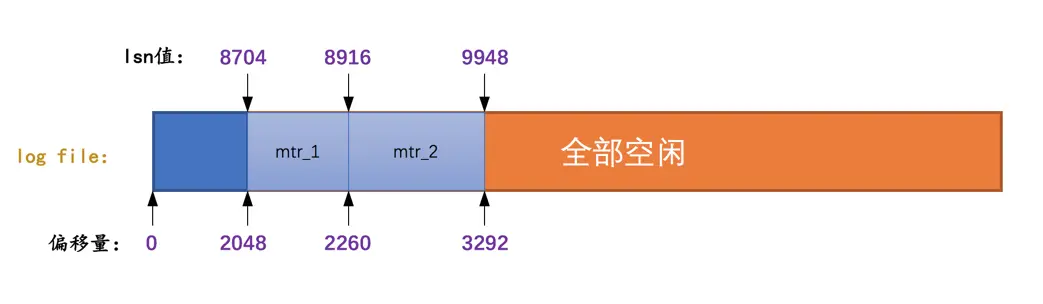
初始时的LSN值是8704,对应文件偏移量2048,之后每个mtr向磁盘中写入多少字节日志,lsn的值就增长多少。
2.6.3flush链表中的LSN
我们知道一个mtr代表一次对底层页面的原子访问,在访问过程中可能会产生一组不可分割的redo日志,在mtr结束时,会把这一组redo日志写入到log buffer中。除此之外,在mtr结束时还有一件非常重要的事情要做,就是把在mtr执行过程中可能修改过的页面加入到Buffer Pool的flush链表。为了防止大家早已忘记flush链表是个啥,我们再看一下图:
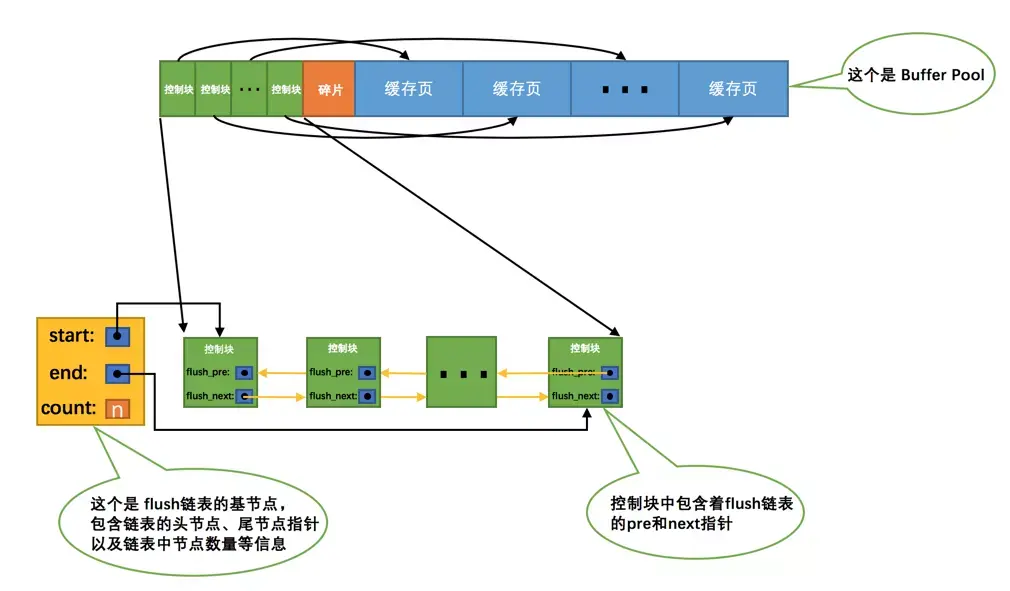
当第一次修改某个缓存在Buffer Pool中的页面时,就会把这个页面对应的控制块插入到flush链表的头部,之后再修改该页面时由于它已经在flush链表中了,就不再次插入了。也就是说flush链表中的脏页是按照页面的第一次修改时间从大到小进行排序的。在这个过程中会在缓存页对应的控制块中记录两个关于页面何时修改的属性:
oldest_modification:如果某个页面被加载到Buffer Pool后进行第一次修改,那么就将修改该页面的mtr开始时对应的lsn值写入这个属性。newest_modification:每修改一次页面,都会将修改该页面的mtr结束时对应的lsn值写入这个属性。也就是说该属性表示页面最近一次修改后对应的系统lsn值。
我们接着上边唠叨flushed_to_disk_lsn的例子看一下:
假设
mtr_1执行过程中修改了页a,那么在mtr_1执行结束时,就会将页a对应的控制块加入到flush链表的头部。并且将mtr_1开始时对应的lsn,也就是8716写入页a对应的控制块的oldest_modification属性中,把mtr_1结束时对应的lsn,也就是8916写入页a对应的控制块的newest_modification属性中。画个图表示一下(为了让图片美观一些,我们把oldest_modification缩写成了o_m,把newest_modification缩写成了n_m):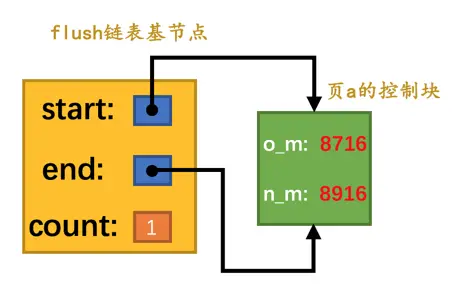
接着假设
mtr_2执行过程中又修改了页b和页c两个页面,那么在mtr_2执行结束时,就会将页b和页c对应的控制块都加入到flush链表的头部。并且将mtr_2开始时对应的lsn,也就是8916写入页b和页c对应的控制块的oldest_modification属性中,把mtr_2结束时对应的lsn,也就是9948写入页b和页c对应的控制块的newest_modification属性中。画个图表示一下: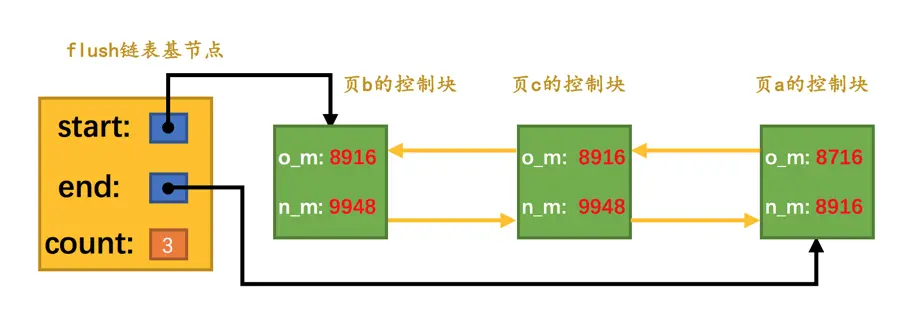
从图中可以看出来,每次新插入到
flush链表中的节点都是被放在了头部,也就是说flush链表中前边的脏页修改的时间比较晚,后边的脏页修改时间比较早。接着假设
mtr_3执行过程中修改了页b和页d,不过页b之前已经被修改过了,所以它对应的控制块已经被插入到了flush链表,所以在mtr_3执行结束时,只需要将页d对应的控制块都加入到flush链表的头部即可。所以需要将mtr_3开始时对应的lsn,也就是9948写入页d对应的控制块的oldest_modification属性中,把mtr_3结束时对应的lsn,也就是10000写入页d对应的控制块的newest_modification属性中。另外,由于页b在mtr_3执行过程中又发生了一次修改,所以需要更新页b对应的控制块中newest_modification的值为10000。画个图表示一下: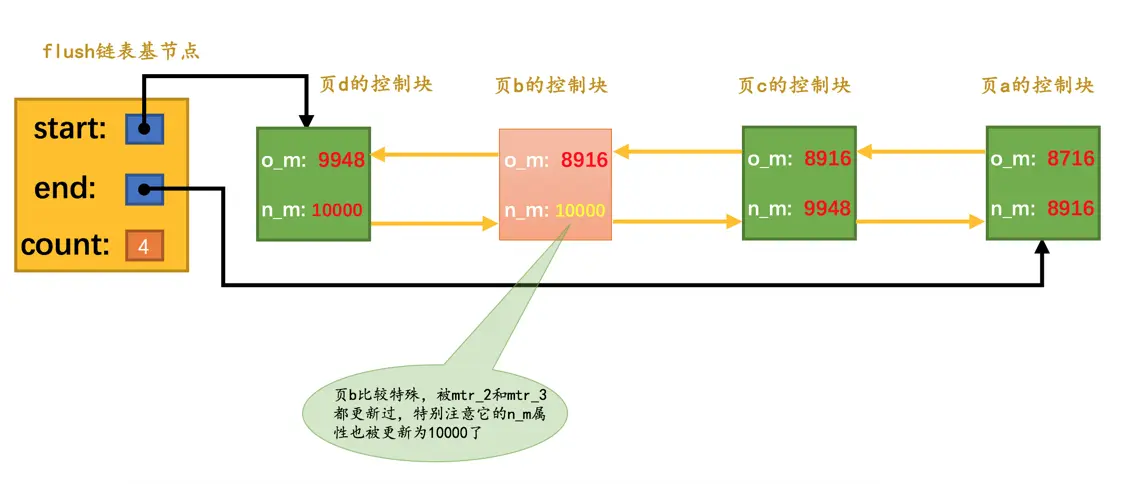
总结一下上边说的,就是:flush链表中的脏页按照修改发生的时间顺序进行排序,也就是按照oldest_modification代表的LSN值进行排序,被多次更新的页面不会重复插入到flush链表中,但是会更新newest_modification属性的值。
2.7checkpoint
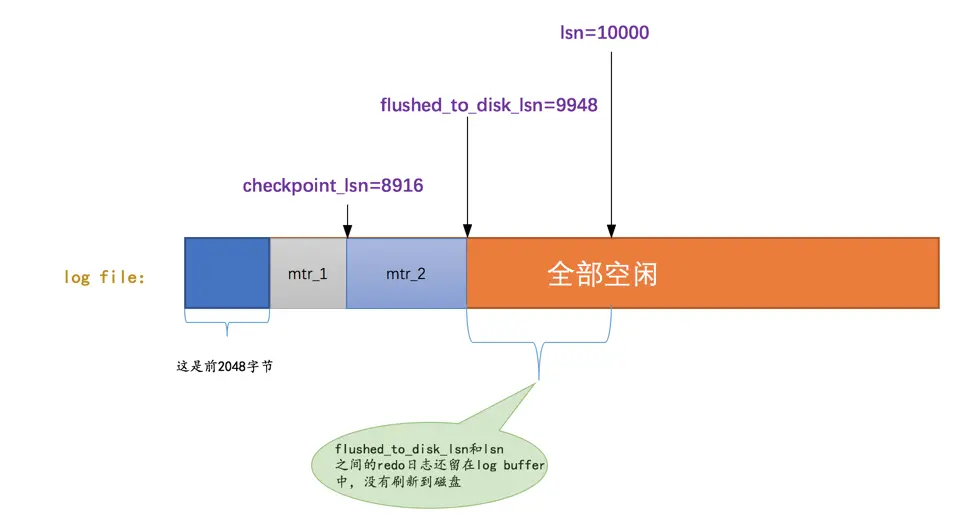
有一个很不幸的事实就是我们的redo日志文件组容量是有限的,我们不得不选择循环使用redo日志文件组中的文件,但是这会造成最后写的redo日志与最开始写的redo日志追尾,这时应该想到:redo日志只是为了系统崩溃后恢复脏页用的,如果对应的脏页已经刷新到了磁盘,也就是说即使现在系统崩溃,那么在重启后也用不着使用redo日志恢复该页面了,所以该redo日志也就没有存在的必要了,那么它占用的磁盘空间就可以被后续的redo日志所重用。也就是说:判断某些redo日志占用的磁盘空间是否可以覆盖的依据就是它对应的脏页是否已经刷新到磁盘里。我们看一下前边一直唠叨的那个例子:
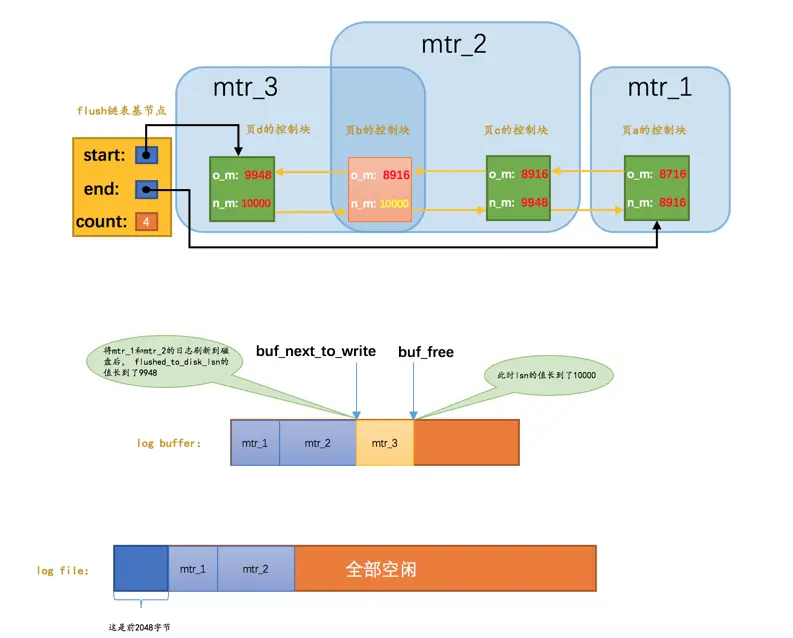
如图,虽然mtr_1和mtr_2生成的redo日志都已经被写到了磁盘上,但是它们修改的脏页仍然留在Buffer Pool中,所以它们生成的redo日志在磁盘上的空间是不可以被覆盖的。之后随着系统的运行,如果页a被刷新到了磁盘,那么它对应的控制块就会从flush链表中移除,就像这样子:
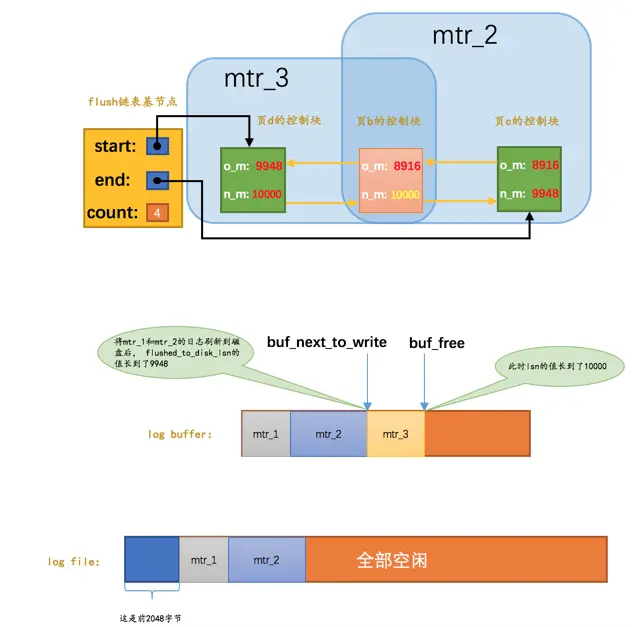
这样mtr_1生成的redo日志就没有用了,它们占用的磁盘空间就可以被覆盖掉了。设计InnoDB的大叔提出了一个全局变量checkpoint_lsn来代表当前系统中可以被覆盖的redo日志总量是多少,这个变量初始值也是8704。
比方说现在页a被刷新到了磁盘,mtr_1生成的redo日志就可以被覆盖了,所以我们可以进行一个增加checkpoint_lsn的操作,我们把这个过程称之为做一次checkpoint。做一次checkpoint其实可以分为两个步骤:
步骤一:计算一下当前系统中可以被覆盖的
redo日志对应的lsn值最大是多少。redo日志可以被覆盖,意味着它对应的脏页被刷到了磁盘,只要我们计算出当前系统中被最早修改的脏页对应的oldest_modification值,那凡是在系统lsn值小于该节点的oldest_modification值时产生的redo日志都是可以被覆盖掉的,我们就把该脏页的oldest_modification赋值给checkpoint_lsn。比方说当前系统中
页a已经被刷新到磁盘,那么flush链表的尾节点就是页c,该节点就是当前系统中最早修改的脏页了,它的oldest_modification值为8916,我们就把8916赋值给checkpoint_lsn(也就是说在redo日志对应的lsn值小于8916时就可以被覆盖掉)。步骤二:将
checkpoint_lsn和对应的redo日志文件组偏移量以及此次checkpint的编号写到日志文件的管理信息(就是checkpoint1或者checkpoint2)中。设计
InnoDB的大叔维护了一个目前系统做了多少次checkpoint的变量checkpoint_no,每做一次checkpoint,该变量的值就加1。我们前边说过计算一个lsn值对应的redo日志文件组偏移量是很容易的,所以可以计算得到该checkpoint_lsn在redo日志文件组中对应的偏移量checkpoint_offset,然后把这三个值都写到redo日志文件组的管理信息中。我们说过,每一个
redo日志文件都有2048个字节的管理信息,但是上述关于checkpoint的信息只会被写到日志文件组的第一个日志文件的管理信息中。不过我们是存储到checkpoint1中还是checkpoint2中呢?设计InnoDB的大叔规定,当checkpoint_no的值是偶数时,就写到checkpoint1中,是奇数时,就写到checkpoint2中。
记录完checkpoint的信息之后,redo日志文件组中各个lsn值的关系就像这样:
2.7.1批量从flush链表中刷出脏页
我们在介绍Buffer Pool的时候说过,一般情况下都是后台的线程在对LRU链表和flush链表进行刷脏操作,这主要因为刷脏操作比较慢,不想影响用户线程处理请求。但是如果当前系统修改页面的操作十分频繁,这样就导致写日志操作十分频繁,系统lsn值增长过快。如果后台的刷脏操作不能将脏页刷出,那么系统无法及时做checkpoint,可能就需要用户线程同步的从flush链表中把那些最早修改的脏页(oldest_modification最小的脏页)刷新到磁盘,这样这些脏页对应的redo日志就没用了,然后就可以去做checkpoint了。
2.7.2查看系统中的各种LSN值
我们可以使用SHOW ENGINE INNODB STATUS命令查看当前InnoDB存储引擎中的各种LSN值的情况,比如:
1 | mysql> SHOW ENGINE INNODB STATUS\G |
Log sequence number:代表系统中的lsn值,也就是当前系统已经写入的redo日志量,包括写入log buffer中的日志。Log flushed up to:代表flushed_to_disk_lsn的值,也就是当前系统已经写入磁盘的redo日志量。Pages flushed up to:代表flush链表中被最早修改的那个页面对应的oldest_modification属性值。Last checkpoint at:当前系统的checkpoint_lsn值。
2.8崩溃恢复
在服务器不挂的情况下,redo日志简直就是个大累赘,不仅没用,反而让性能变得更差。但是万一,我说万一啊,万一数据库挂了,那redo日志可是个宝了,我们就可以在重启时根据redo日志中的记录就可以将页面恢复到系统崩溃前的状态。我们接下来大致看一下恢复过程是个啥样。
2.8.1确定恢复的起点
我们前边说过,checkpoint_lsn之前的redo日志都可以被覆盖,也就是说这些redo日志对应的脏页都已经被刷新到磁盘中了,既然它们已经被刷盘,我们就没必要恢复它们了。对于checkpoint_lsn之后的redo日志,它们对应的脏页可能没被刷盘,也可能被刷盘了,我们不能确定,所以需要从checkpoint_lsn开始读取redo日志来恢复页面。
当然,redo日志文件组的第一个文件的管理信息中有两个block都存储了checkpoint_lsn的信息,我们当然是要选取最近发生的那次checkpoint的信息。衡量checkpoint发生时间早晚的信息就是所谓的checkpoint_no,我们只要把checkpoint1和checkpoint2这两个block中的checkpoint_no值读出来比一下大小,哪个的checkpoint_no值更大,说明哪个block存储的就是最近的一次checkpoint信息。这样我们就能拿到最近发生的checkpoint对应的checkpoint_lsn值以及它在redo日志文件组中的偏移量checkpoint_offset。
2.8.2确定恢复的终点
redo日志恢复的起点确定了,那终点是哪个呢?这个还得从block的结构说起。我们说在写redo日志的时候都是顺序写的,写满了一个block之后会再往下一个block中写:
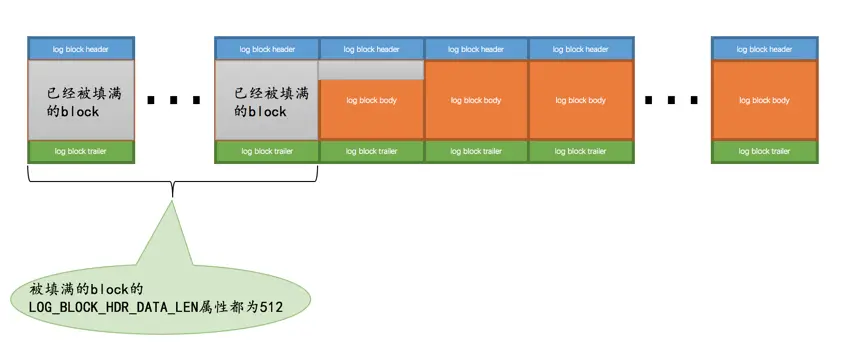
普通block的log block header部分有一个称之为LOG_BLOCK_HDR_DATA_LEN的属性,该属性值记录了当前block里使用了多少字节的空间。对于被填满的block来说,该值永远为512。如果该属性的值不为512,那么就是它了,它就是此次崩溃恢复中需要扫描的最后一个block。
2.8.3怎么恢复
确定了需要扫描哪些redo日志进行崩溃恢复之后,接下来就是怎么进行恢复了。假设现在的redo日志文件中有5条redo日志,如图:
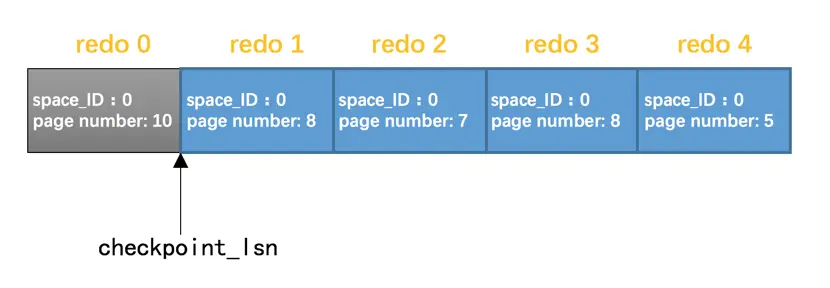
由于redo 0在checkpoint_lsn后边,恢复时可以不管它。我们现在可以按照redo日志的顺序依次扫描checkpoint_lsn之后的各条redo日志,按照日志中记载的内容将对应的页面恢复出来。这样没什么问题,不过设计InnoDB的大叔还是想了一些办法加快这个恢复的过程:
使用哈希表
根据
redo日志的space ID和page number属性计算出散列值,把space ID和page number相同的redo日志放到哈希表的同一个槽里,如果有多个space ID和page number都相同的redo日志,那么它们之间使用链表连接起来,按照生成的先后顺序链接起来的,如图所示: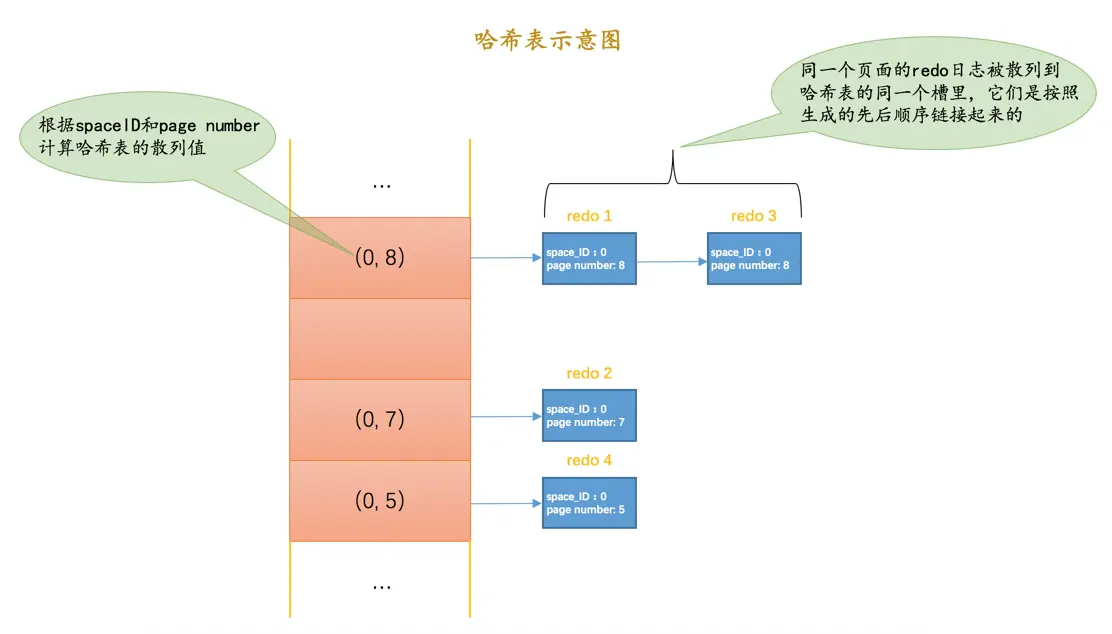
之后就可以遍历哈希表,因为对同一个页面进行修改的
redo日志都放在了一个槽里,所以可以一次性将一个页面修复好(避免了很多读取页面的随机IO),这样可以加快恢复速度。另外需要注意一点的是,同一个页面的redo日志是按照生成时间顺序进行排序的,所以恢复的时候也是按照这个顺序进行恢复,如果不按照生成时间顺序进行排序的话,那么可能出现错误。比如原先的修改操作是先插入一条记录,再删除该条记录,如果恢复时不按照这个顺序来,就可能变成先删除一条记录,再插入一条记录,这显然是错误的。跳过已经刷新到磁盘的页面
我们前边说过,
checkpoint_lsn之前的redo日志对应的脏页确定都已经刷到磁盘了,但是checkpoint_lsn之后的redo日志我们不能确定是否已经刷到磁盘,主要是因为在最近做的一次checkpoint后,可能后台线程又不断的从LRU链表和flush链表中将一些脏页刷出Buffer Pool。这些在checkpoint_lsn之后的redo日志,如果它们对应的脏页在崩溃发生时已经刷新到磁盘,那在恢复时也就没有必要根据redo日志的内容修改该页面了。那在恢复时怎么知道某个
redo日志对应的脏页是否在崩溃发生时已经刷新到磁盘了呢?这还得从页面的结构说起,我们前边说过每个页面都有一个称之为File Header的部分,在File Header里有一个称之为FIL_PAGE_LSN的属性,该属性记载了最近一次修改页面时对应的lsn值(其实就是页面控制块中的newest_modification值)。如果在做了某次checkpoint之后有脏页被刷新到磁盘中,那么该页对应的FIL_PAGE_LSN代表的lsn值肯定大于checkpoint_lsn的值,凡是符合这种情况的页面就不需要重复执行lsn值小于FIL_PAGE_LSN的redo日志了,所以更进一步提升了崩溃恢复的速度。
三、Undo日志
四、MVCC与隔离级别
为了故事的顺利发展,我们需要创建一个表:
1 | CREATE TABLE hero ( |
注意我们把这个hero表的主键命名为number,而不是id,主要是想和后边要用到的事务id做区别,大家不用大惊小怪哈~
然后向这个表里插入一条数据:
1 | INSERT INTO hero VALUES(1, '刘备', '蜀'); |
现在表里的数据就是这样的:
1 | mysql> SELECT * FROM hero; |
4.1事务隔离级别
我们知道MySQL是一个客户端/服务器架构的软件,对于同一个服务器来说,可以有若干个客户端与之连接,每个客户端与服务器连接上之后,就可以称之为一个会话(Session)。每个客户端都可以在自己的会话中向服务器发出请求语句,一个请求语句可能是某个事务的一部分,也就是对于服务器来说可能同时处理多个事务。在事务简介的章节中我们说过事务有一个称之为隔离性的特性,理论上在某个事务对某个数据进行访问时,其他事务应该进行排队,当该事务提交之后,其他事务才可以继续访问这个数据。但是这样子的话对性能影响太大,我们既想保持事务的隔离性,又想让服务器在处理访问同一数据的多个事务时性能尽量高些,鱼和熊掌不可得兼,舍一部分隔离性而取性能者也。
4.1.1事务并发执行遇到的问题
怎么个舍弃法呢?我们先得看一下访问相同数据的事务在不保证串行执行(也就是执行完一个再执行另一个)的情况下可能会出现哪些问题:
脏写(
Dirty Write)如果一个事务修改了另一个未提交事务修改过的数据,那就意味着发生了
脏写,示意图如下: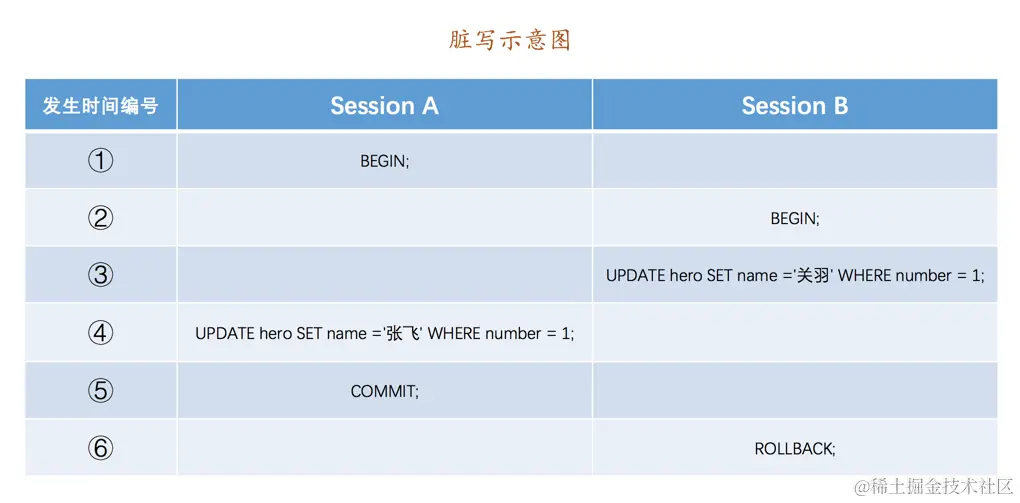
如上图,
Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为'关羽',然后Session A中的事务接着又把这条number列为1的记录的name列更新为张飞。如果之后Session B中的事务进行了回滚,那么Session A中的更新也将不复存在,这种现象就称之为脏写。这时Session A中的事务就很懵逼,我明明把数据更新了,最后也提交事务了,怎么到最后说自己啥也没干呢?脏读(
Dirty Read)如果一个事务读到了另一个未提交事务修改过的数据,那就意味着发生了
脏读,示意图如下: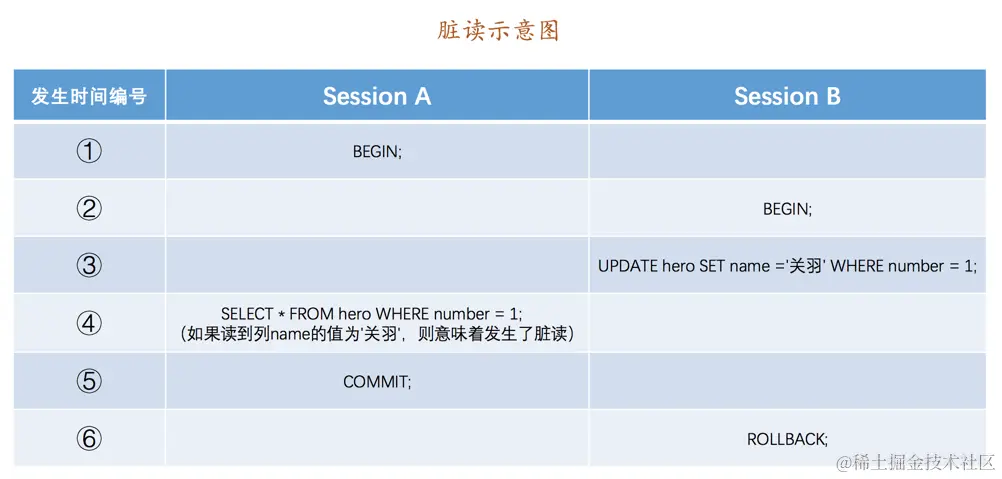
如上图,
Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为'关羽',然后Session A中的事务再去查询这条number为1的记录,如果读到列name的值为'关羽',而Session B中的事务稍后进行了回滚,那么Session A中的事务相当于读到了一个不存在的数据,这种现象就称之为脏读。不可重复读(
Non-Repeatable Read)如果一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,那就意味着发生了
不可重复读,示意图如下: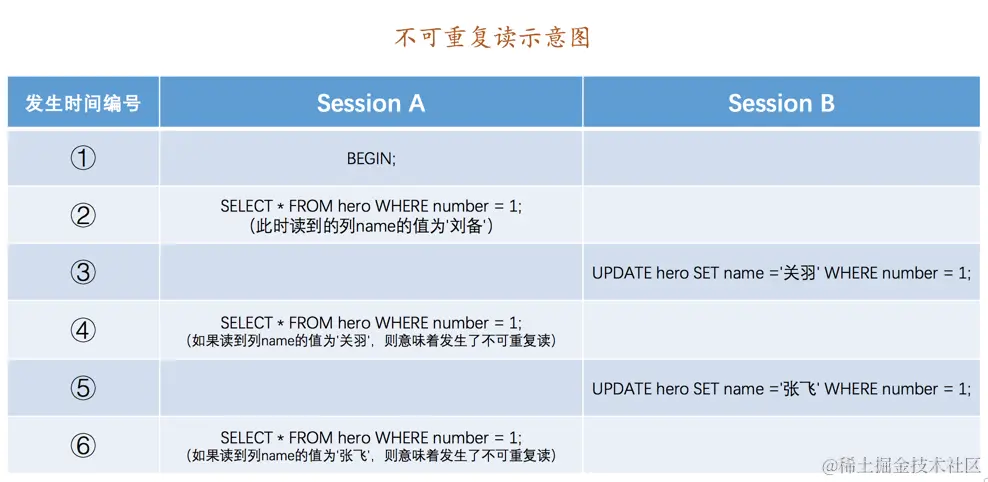
幻读(
Phantom)如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来,那就意味着发生了
幻读,示意图如下:
如上图,
Session A中的事务先根据条件number > 0这个条件查询表hero,得到了name列值为'刘备'的记录;之后Session B中提交了一个隐式事务,该事务向表hero中插入了一条新记录;之后Session A中的事务再根据相同的条件number > 0查询表hero,得到的结果集中包含Session B中的事务新插入的那条记录,这种现象也被称之为幻读。有的同学会有疑问,那如果
Session B中是删除了一些符合number > 0的记录而不是插入新记录,那Session A中之后再根据number > 0的条件读取的记录变少了,这种现象算不算幻读呢?明确说一下,这种现象不属于幻读,幻读强调的是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录。那对于先前已经读到的记录,之后又读取不到这种情况,算啥呢?其实这相当于对每一条记录都发生了不可重复读的现象。幻读只是重点强调了读取到了之前读取没有获取到的记录。
4.1.2SQL标准中的四种隔离级别
我们上边介绍了几种并发事务执行过程中可能遇到的一些问题,这些问题也有轻重缓急之分,我们给这些问题按照严重性来排一下序:
1 | 脏写 > 脏读 > 不可重复读 > 幻读 |
我们上边所说的舍弃一部分隔离性来换取一部分性能在这里就体现在:设立一些隔离级别,隔离级别越低,越严重的问题就越可能发生。有一帮人(并不是设计MySQL的大叔们)制定了一个所谓的SQL标准,在标准中设立了4个隔离级别:
READ UNCOMMITTED:未提交读。READ COMMITTED:已提交读。REPEATABLE READ:可重复读。SERIALIZABLE:可串行化。
SQL标准中规定,针对不同的隔离级别,并发事务可以发生不同严重程度的问题,具体情况如下:
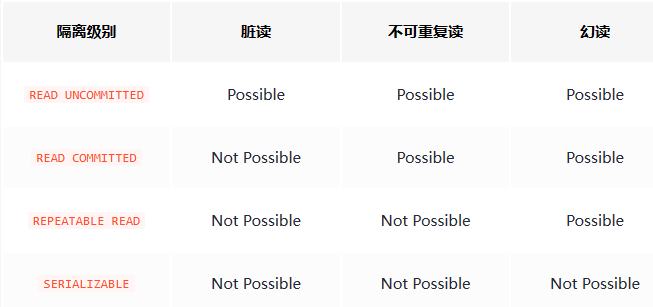
也就是说:
READ UNCOMMITTED隔离级别下,可能发生脏读、不可重复读和幻读问题。READ COMMITTED隔离级别下,可能发生不可重复读和幻读问题,但是不可以发生脏读问题。REPEATABLE READ隔离级别下,可能发生幻读问题,但是不可以发生脏读和不可重复读的问题。SERIALIZABLE隔离级别下,各种问题都不可以发生。
脏写是怎么回事儿?怎么里边都没写呢?这是因为脏写这个问题太严重了,不论是哪种隔离级别,都不允许脏写的情况发生。
4.1.3MySQL中支持的四种隔离级别
不同的数据库厂商对SQL标准中规定的四种隔离级别支持不一样,比方说Oracle就只支持READ COMMITTED和SERIALIZABLE隔离级别。本书中所讨论的MySQL虽然支持4种隔离级别,但与SQL标准中所规定的各级隔离级别允许发生的问题却有些出入,MySQL在REPEATABLE READ隔离级别下,是可以禁止幻读问题的发生的(关于如何禁止我们之后会详细说明的)。
MySQL的默认隔离级别为REPEATABLE READ,我们可以手动修改一下事务的隔离级别。
我们可以通过下边的语句修改事务的隔离级别:
1 | SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level; |
其中的level可选值有4个:
1 | level: { |
设置事务的隔离级别的语句中,在SET关键字后可以放置GLOBAL关键字、SESSION关键字或者什么都不放,这样会对不同范围的事务产生不同的影响,具体如下:
使用
GLOBAL关键字(在全局范围影响):1
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
- 只对执行完该语句之后产生的会话起作用。
- 当前已经存在的会话无效。
使用
SESSION关键字(在会话范围影响):1
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
- 对当前会话的所有后续的事务有效
- 该语句可以在已经开启的事务中间执行,但不会影响当前正在执行的事务。
- 如果在事务之间执行,则对后续的事务有效。
上述两个关键字都不用(只对执行语句后的下一个事务产生影响):
1
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
- 只对当前会话中下一个即将开启的事务有效。
- 下一个事务执行完后,后续事务将恢复到之前的隔离级别。
- 该语句不能在已经开启的事务中间执行,会报错的。
如果我们在服务器启动时想改变事务的默认隔离级别,可以修改启动参数transaction-isolation的值,比方说我们在启动服务器时指定了--transaction-isolation=SERIALIZABLE,那么事务的默认隔离级别就从原来的REPEATABLE READ变成了SERIALIZABLE。
想要查看当前会话默认的隔离级别可以通过查看系统变量transaction_isolation的值来确定:
1 | mysql> SHOW VARIABLES LIKE 'transaction_isolation'; |
4.2MVCC原理
4.2.1版本链
我们前边说过,对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列(row_id并不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含row_id列):
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
比方说我们的表hero现在只包含一条记录:
1 | mysql> SELECT * FROM hero; |
假设插入该记录的事务id为80,那么此刻该条记录的示意图如下所示:
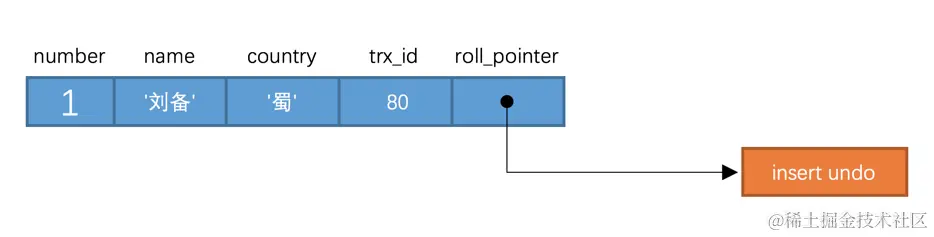
实际上insert undo只在事务回滚时起作用,当事务提交后,该类型的undo日志就没用了,它占用的Undo Log Segment也会被系统回收(也就是该undo日志占用的Undo页面链表要么被重用,要么被释放)。虽然真正的insert undo日志占用的存储空间被释放了,但是roll_pointer的值并不会被清除,roll_pointer属性占用7个字节,第一个比特位就标记着它指向的undo日志的类型,如果该比特位的值为1时,就代表着它指向的undo日志类型为insert undo。所以我们之后在画图时都会把insert undo给去掉,大家留意一下就好了。
假设之后两个事务id分别为100、200的事务对这条记录进行UPDATE操作,操作流程如下:
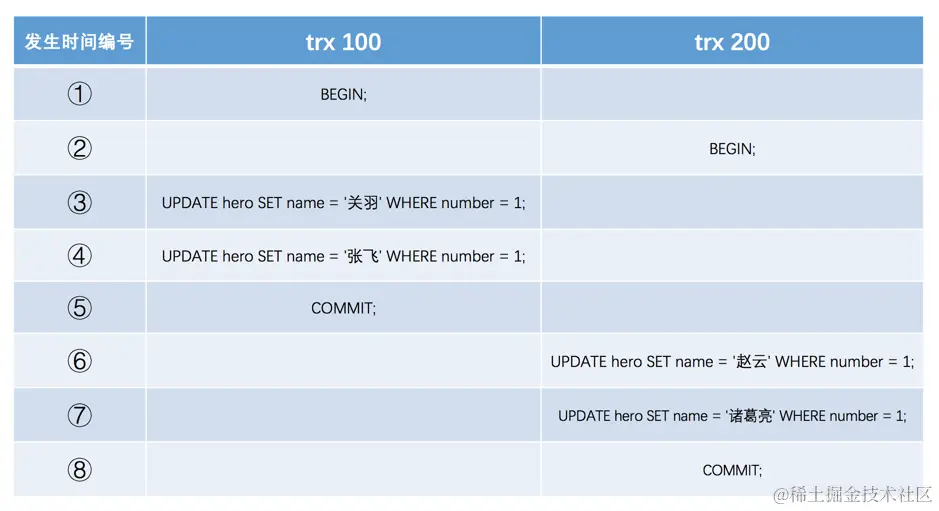
能不能在两个事务中交叉更新同一条记录呢?哈哈,这不就是一个事务修改了另一个未提交事务修改过的数据,沦为了脏写了么?InnoDB使用锁来保证不会有脏写情况的发生,也就是在第一个事务更新了某条记录后,就会给这条记录加锁,另一个事务再次更新时就需要等待第一个事务提交了,把锁释放之后才可以继续更新。关于锁的更多细节我们后续的文章中再唠叨哈~
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
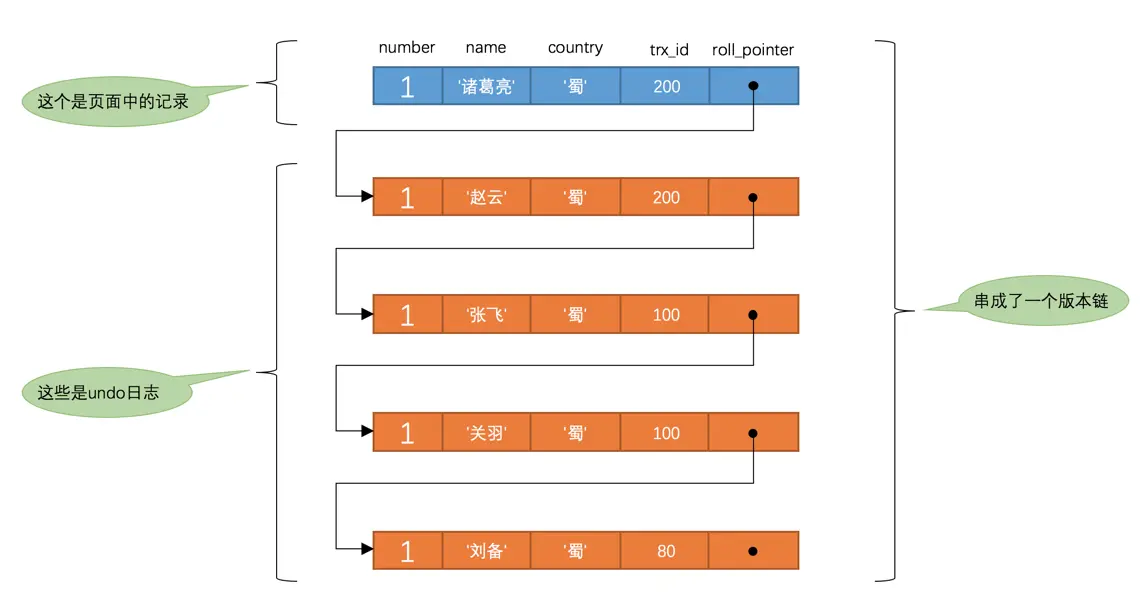
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id,这个信息很重要,我们稍后就会用到。
4.2.2ReadView
对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了;对于使用SERIALIZABLE隔离级别的事务来说,设计InnoDB的大叔规定使用加锁的方式来访问记录(加锁是啥我们后续文章中说哈);对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,设计InnoDB的大叔提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。
creator_trx_id:表示生成该ReadView的事务的事务id。我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的
trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 - 如果被访问版本的
trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。我们还是以表hero为例来,假设现在表hero中只有一条由事务id为80的事务插入的一条记录:
1 | mysql> SELECT * FROM hero; |
接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。
READ COMMITTED —— 每次读取数据前都生成一个ReadView
比方说现在系统里有两个事务id分别为100、200的事务在执行:
1 | # Transaction 100 |
再次强调一遍,事务执行过程中,只有在第一次真正修改记录时(比如使用INSERT、DELETE、UPDATE语句),才会被分配一个单独的事务id,这个事务id是递增的。所以我们才在Transaction 200中更新一些别的表的记录,目的是让它分配事务id。
此刻,表hero中number为1的记录得到的版本链表如下所示:
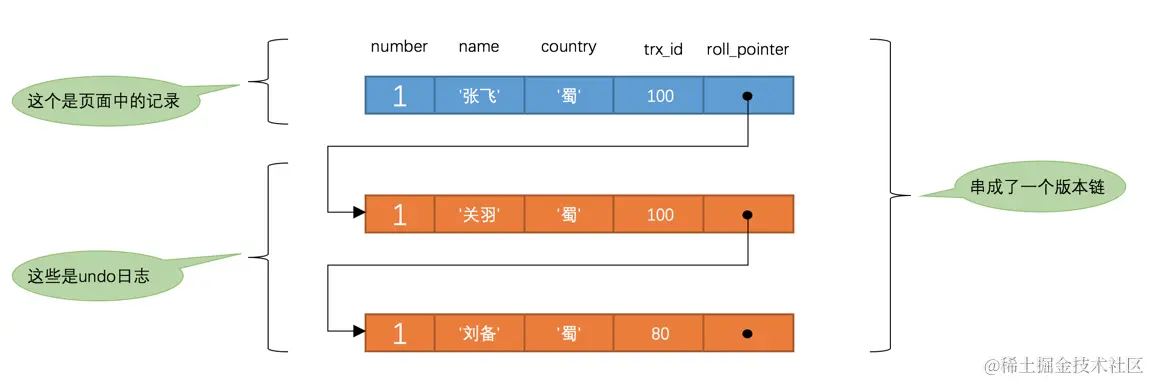
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行:
1 | # 使用READ COMMITTED隔离级别的事务 |
这个SELECT1的执行过程如下:
- 在执行
SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。 - 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列
name的内容是'张飞',该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。 - 下一个版本的列
name的内容是'关羽',该版本的trx_id值也为100,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 - 下一个版本的列
name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为'刘备'的记录。
之后,我们把事务id为100的事务提交一下,就像这样:
1 | # Transaction 100 |
然后再到事务id为200的事务中更新一下表hero中number为1的记录:
1 | # Transaction 200 |
此刻,表hero中number为1的记录的版本链就长这样:
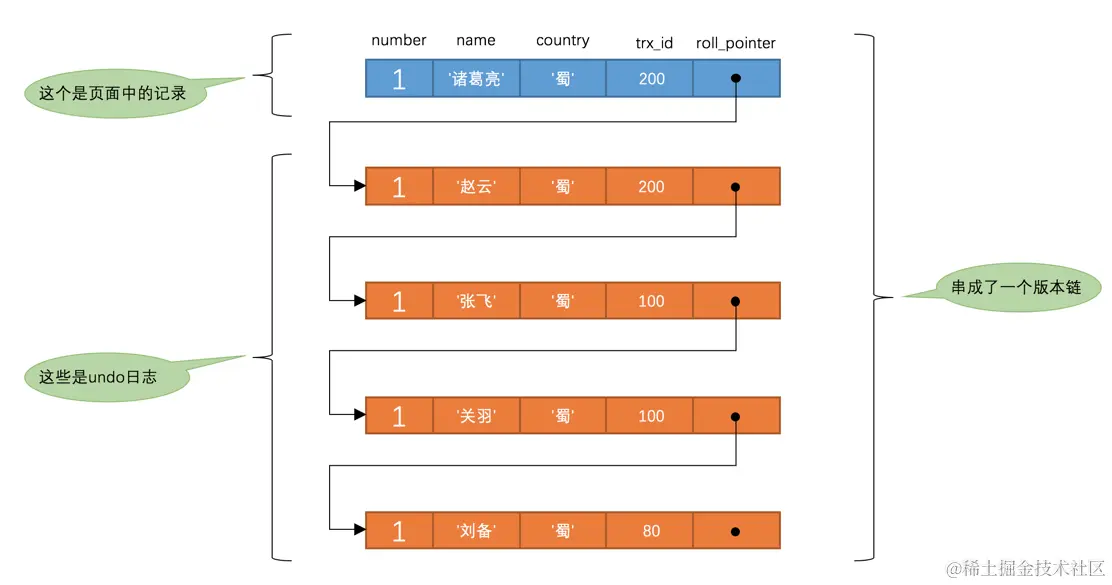
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number为1的记录,如下:
1 | # 使用READ COMMITTED隔离级别的事务 |
这个SELECT2的执行过程如下:
- 在执行
SELECT语句时会又会单独生成一个ReadView,该ReadView的m_ids列表的内容就是[200](事务id为100的那个事务已经提交了,所以再次生成快照时就没有它了),min_trx_id为200,max_trx_id为201,creator_trx_id为0。 - 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列
name的内容是'诸葛亮',该版本的trx_id值为200,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。 - 下一个版本的列
name的内容是'赵云',该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 - 下一个版本的列
name的内容是'张飞',该版本的trx_id值为100,小于ReadView中的min_trx_id值200,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为'张飞'的记录。
以此类推,如果之后事务id为200的记录也提交了,再次在使用READ COMMITTED隔离级别的事务中查询表hero中number值为1的记录时,得到的结果就是'诸葛亮'了,具体流程我们就不分析了。
总结一下就是:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。
REPEATABLE READ —— 在第一次读取数据时生成一个ReadView
对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。
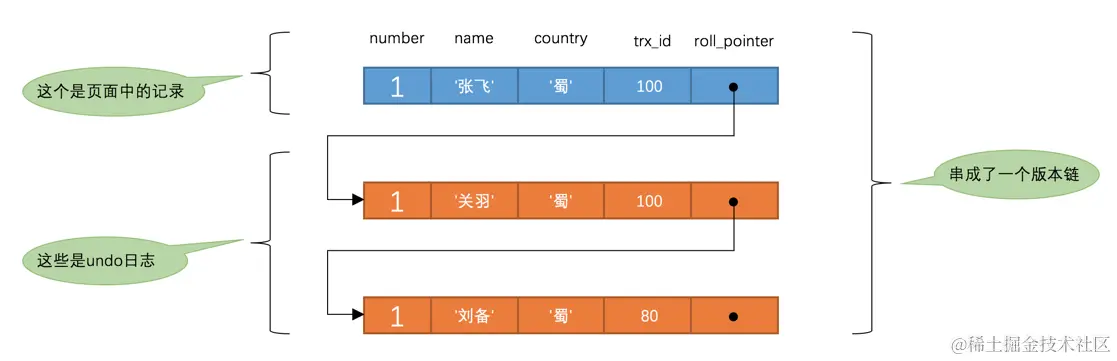
比方说现在系统里有两个事务id分别为100、200的事务在执行:
1 | # Transaction 100 |
此刻,表hero中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行:
1 | # 使用REPEATABLE READ隔离级别的事务 |
这个SELECT1的执行过程如下:
- 在执行
SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。 - 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列
name的内容是'张飞',该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。 - 下一个版本的列
name的内容是'关羽',该版本的trx_id值也为100,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 - 下一个版本的列
name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为'刘备'的记录。
之后,我们把事务id为100的事务提交一下,就像这样:
1 | # Transaction 100 |
然后再到事务id为200的事务中更新一下表hero中number为1的记录:
1 | # Transaction 200 |
此刻,表hero中number为1的记录的版本链就长这样:
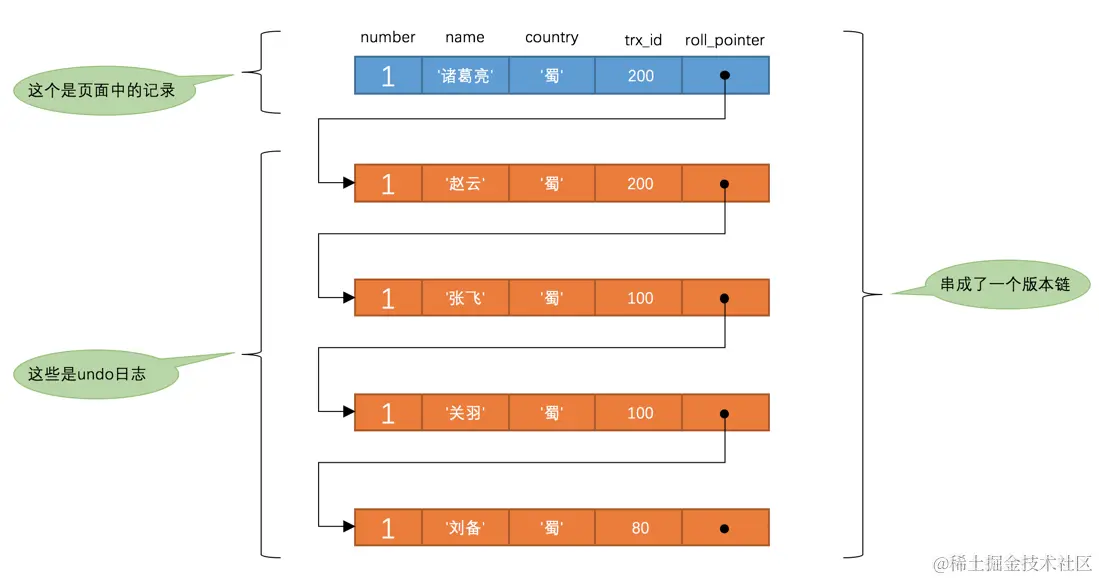
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下:
1 | # 使用REPEATABLE READ隔离级别的事务 |
这个SELECT2的执行过程如下:
- 因为当前事务的隔离级别为
REPEATABLE READ,而之前在执行SELECT1时已经生成过ReadView了,所以此时直接复用之前的ReadView,之前的ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。 - 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列
name的内容是'诸葛亮',该版本的trx_id值为200,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。 - 下一个版本的列
name的内容是'赵云',该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 - 下一个版本的列
name的内容是'张飞',该版本的trx_id值为100,而m_ids列表中是包含值为100的事务id的,所以该版本也不符合要求,同理下一个列name的内容是'关羽'的版本也不符合要求。继续跳到下一个版本。 - 下一个版本的列
name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条列c为'刘备'的记录。
也就是说两次SELECT查询得到的结果是重复的,记录的列c值都是'刘备',这就是可重复读的含义。如果我们之后再把事务id为200的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是'刘备',具体执行过程大家可以自己分析一下。
4.2.3MVCC小结
从上边的描述中我们可以看出来,所谓的MVCC(Multi-Version Concurrency Control,多版本并发控制)指的就是在使用READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行普通的SELECT操作时访问记录的版本链的过程,这样子可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。READ COMMITTD、REPEATABLE READ这两个隔离级别的一个很大不同就是:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了。
我们之前说执行DELETE语句或者更新主键的UPDATE语句并不会立即把对应的记录完全从页面中删除,而是执行一个所谓的delete mark操作,相当于只是对记录打上了一个删除标志位,这主要就是为MVCC服务的,大家可以对比上边举的例子自己试想一下怎么使用。