1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
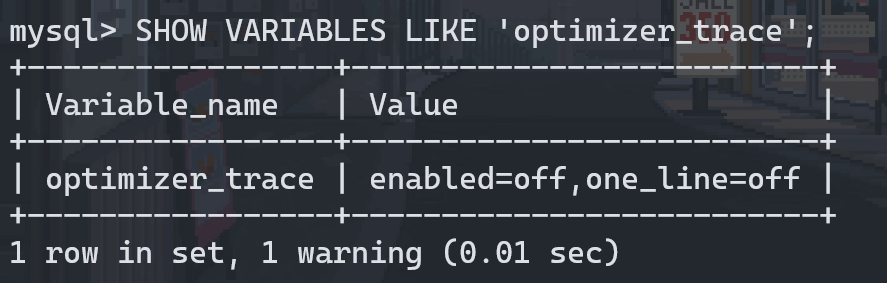
| *************************** 1. row ***************************
# 分析的查询语句是什么
QUERY: SELECT * FROM s1 WHERE
key1 > 'z' AND
key2 < 1000000 AND
key3 IN ('a', 'b', 'c') AND
common_field = 'abc'
# 优化的具体过程
TRACE: {
"steps": [
{
"join_preparation": { # prepare阶段
"select#": 1,
"steps": [
{
"IN_uses_bisection": true
},
{
"expanded_query": "/* select#1 */ select `s1`.`id` AS `id`,`s1`.`key1` AS `key1`,`s1`.`key2` AS `key2`,`s1`.`key3` AS `key3`,`s1`.`key_part1` AS `key_part1`,`s1`.`key_part2` AS `key_part2`,`s1`.`key_part3` AS `key_part3`,`s1`.`common_field` AS `common_field` from `s1` where ((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
"join_optimization": { # optimize阶段
"select#": 1,
"steps": [
{
"condition_processing": { # 处理搜索条件
"condition": "WHERE",
# 原始搜索条件
"original_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))",
"steps": [
{
# 等值传递转换
"transformation": "equality_propagation",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
},
{
# 常量传递转换
"transformation": "constant_propagation",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
},
{
# 去除没用的条件
"transformation": "trivial_condition_removal",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
# 替换虚拟生成列
"substitute_generated_columns": {
}
},
{
# 表的依赖信息
"table_dependencies": [
{
"table": "`s1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
# 预估不同单表访问方法的访问成本
"rows_estimation": [
{
"table": "`s1`",
"range_analysis": {
"table_scan": { # 全表扫描的行数以及成本
"rows": 9688,
"cost": 2036.7
} ,
# 分析可能使用的索引
"potential_range_indexes": [
{
"index": "PRIMARY", # 主键不可用
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_key2", # idx_key2可能被使用
"usable": true,
"key_parts": [
"key2"
]
},
{
"index": "idx_key1", # idx_key1可能被使用
"usable": true,
"key_parts": [
"key1",
"id"
]
},
{
"index": "idx_key3", # idx_key3可能被使用
"usable": true,
"key_parts": [
"key3",
"id"
]
},
{
"index": "idx_key_part", # idx_keypart不可用
"usable": false,
"cause": "not_applicable"
}
] ,
"setup_range_conditions": [
] ,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} ,
# 分析各种可能使用的索引的成本
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
# 使用idx_key2的成本分析
"index": "idx_key2",
# 使用idx_key2的范围区间
"ranges": [
"NULL < key2 < 1000000"
] ,
"index_dives_for_eq_ranges": true, # 是否使用index dive
"rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序
"using_mrr": false, # 是否使用mrr
"index_only": false, # 是否是索引覆盖访问
"rows": 12, # 使用该索引获取的记录条数
"cost": 15.41, # 使用该索引的成本
"chosen": true # 是否选择该索引
},
{
# 使用idx_key1的成本分析
"index": "idx_key1",
# 使用idx_key1的范围区间
"ranges": [
"z < key1"
] ,
"index_dives_for_eq_ranges": true, # 是否使用index dive
"rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序
"using_mrr": false, # 是否使用mrr
"index_only": false, # 是否是索引覆盖访问
"rows": 266, # 使用该索引获取的记录条数
"cost": 320.21, # 使用该索引的成本
"chosen": false, # 是否选择该索引
"cause": "cost" # 因为成本太大所以不选择该索引
},
{
# 使用idx_key3的成本分析
"index": "idx_key3",
# 使用idx_key3的范围区间
"ranges": [
"a <= key3 <= a",
"b <= key3 <= b",
"c <= key3 <= c"
] ,
"index_dives_for_eq_ranges": true, # 是否使用index dive
"rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序
"using_mrr": false, # 是否使用mrr
"index_only": false, # 是否是索引覆盖访问
"rows": 21, # 使用该索引获取的记录条数
"cost": 28.21, # 使用该索引的成本
"chosen": false, # 是否选择该索引
"cause": "cost" # 因为成本太大所以不选择该索引
}
] ,
# 分析使用索引合并的成本
"analyzing_roworder_intersect": {
"usable": false, # 是否使用Intersection索引合并
"cause": "too_few_roworder_scans" # 因为索引获取的记录主键值不是有序的,并且索引获取的记录数很小,回表的代价很小,没有必要访问多个B+树索引求交集再回表
}
} ,
# 对于上述单表查询s1最优的访问方法
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan", # 访问方法
"index": "idx_key2", # 使用的索引
"rows": 12, # 使用该索引获取的记录条数
"ranges": [
"NULL < key2 < 1000000" # 索引的范围区间
]
} ,
"rows_for_plan": 12,
"cost_for_plan": 15.41,
"chosen": true
}
}
}
]
},
{
# 分析各种可能的执行计划
#(对多表查询这可能有很多种不同的方案,单表查询的方案上边已经分析过了,直接选取idx_key2就好)
"considered_execution_plans": [
{
"plan_prefix": [
] ,
"table": "`s1`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 12,
"access_type": "range",
"range_details": {
"used_index": "idx_key2"
} ,
"resulting_rows": 12,
"cost": 17.81,
"chosen": true
}
]
} ,
"condition_filtering_pct": 100,
"rows_for_plan": 12,
"cost_for_plan": 17.81,
"chosen": true
}
]
},
{
# 尝试给查询添加一些其他的查询条件
"attaching_conditions_to_tables": {
"original_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))",
"attached_conditions_computation": [
] ,
"attached_conditions_summary": [
{
"table": "`s1`",
"attached": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
# 再稍稍的改进一下执行计划
"refine_plan": [
{
"table": "`s1`",
"pushed_index_condition": "(`s1`.`key2` < 1000000)",
"table_condition_attached": "((`s1`.`key1` > 'z') and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
]
}
},
{
"join_execution": { # execute阶段
"select#": 1,
"steps": [
]
}
}
]
}
# 因优化过程文本太多而丢弃的文本字节大小,值为0时表示并没有丢弃
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
# 权限字段
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.00 sec)
|