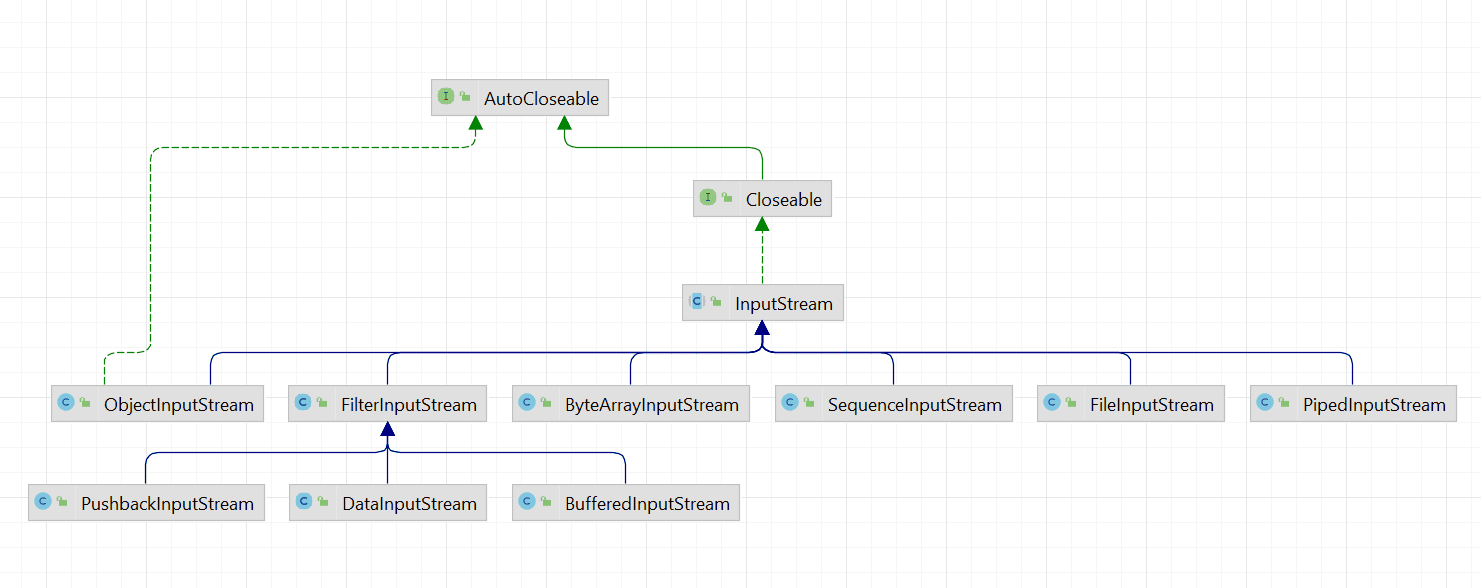
InputStream是所有字节输入流的公共祖先类,下面有很多的实现类,最常用的包括ByteArrayInputStream、FileInputStream和BufferedInputStream,后面我们会单独对这些类一一讲解。
1 2 3 4 5 6 private static final int MAX_SKIP_BUFFER_SIZE = 2048 ;private static final int DEFAULT_BUFFER_SIZE = 8192 ;private static final int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8 ;
字节输入流InputStream中最重要的方法必然就是读取字节数据的read方法了,包含三个重载形式,最终调用的还是原始的read()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public abstract int read () throws IOException;public int read (byte b[]) throws IOException { return read(b, 0 , b.length); } public int read (byte b[], int off, int len) throws IOException { Objects.checkFromIndexSize(off, len, b.length); if (len == 0 ) { return 0 ; } int c = read(); if (c == -1 ) { return -1 ; } b[off] = (byte )c; int i = 1 ; try { for (; i < len ; i++) { c = read(); if (c == -1 ) { break ; } b[off + i] = (byte )c; } } catch (IOException ee) { } return i; }
第二个我们看一下skip方法,这在一些子类中可能会使用到,用于跳过若干字节的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public long skip (long n) throws IOException { long remaining = n; int nr; if (n <= 0 ) { return 0 ; } int size = (int )Math.min(MAX_SKIP_BUFFER_SIZE, remaining); byte [] skipBuffer = new byte [size]; while (remaining > 0 ) { nr = read(skipBuffer, 0 , (int )Math.min(size, remaining)); if (nr < 0 ) { break ; } remaining -= nr; } return n - remaining; }
我们顺便看一下available和close方法的含义。
1 2 3 4 5 6 7 8 9 10 public int available () throws IOException { return 0 ; } public void close () throws IOException {}
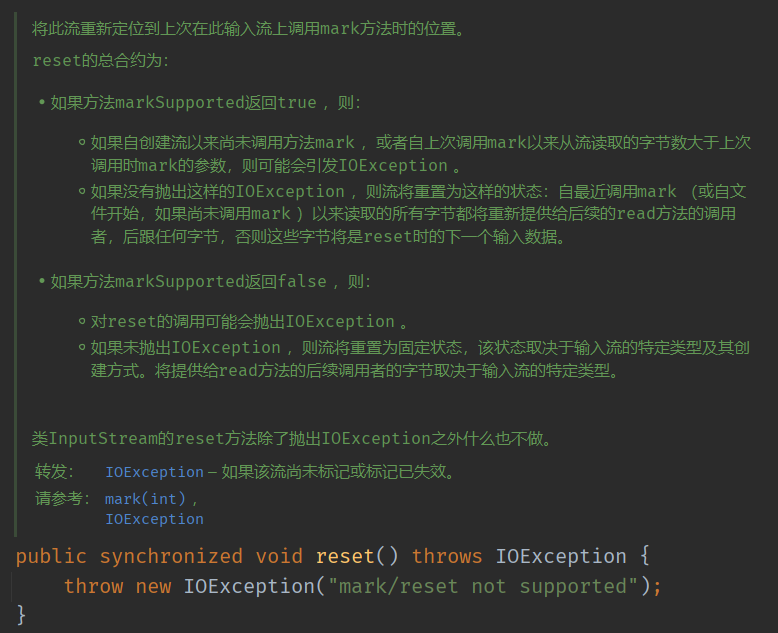
下面,我们看一下跟标记相关的一些方法,这些方法不太常用,我们简单过一遍。
1 2 3 4 5 6 7 8 9 10 public synchronized void mark (int readlimit) {}public boolean markSupported () { return false ; }
自JDK9依赖,InputStream中增加了一些新的方法来读取和复制InputStream中包含的数据。
readAllBytes:读取InputStream中的所有剩余字节。
readNBytes:从InputStream中读取指定数量的字节到数组中。
transferTo:读取InputStream中的全部字节并写入到指定的OutputStream中 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 public byte [] readAllBytes() throws IOException { return readNBytes(Integer.MAX_VALUE); } public byte [] readNBytes(int len) throws IOException { if (len < 0 ) { throw new IllegalArgumentException ("len < 0" ); } List<byte []> bufs = null ; byte [] result = null ; int total = 0 ; int remaining = len; int n; do { byte [] buf = new byte [Math.min(remaining, DEFAULT_BUFFER_SIZE)]; int nread = 0 ; while ((n = read(buf, nread, Math.min(buf.length - nread, remaining))) > 0 ) { nread += n; remaining -= n; } if (nread > 0 ) { if (MAX_BUFFER_SIZE - total < nread) { throw new OutOfMemoryError ("Required array size too large" ); } total += nread; if (result == null ) { result = buf; } else { if (bufs == null ) { bufs = new ArrayList <>(); bufs.add(result); } bufs.add(buf); } } } while (n >= 0 && remaining > 0 ); if (bufs == null ) { if (result == null ) { return new byte [0 ]; } return result.length == total ? result : Arrays.copyOf(result, total); } result = new byte [total]; int offset = 0 ; remaining = total; for (byte [] b : bufs) { int count = Math.min(b.length, remaining); System.arraycopy(b, 0 , result, offset, count); offset += count; remaining -= count; } return result; } public long transferTo (OutputStream out) throws IOException { Objects.requireNonNull(out, "out" ); long transferred = 0 ; byte [] buffer = new byte [DEFAULT_BUFFER_SIZE]; int read; while ((read = this .read(buffer, 0 , DEFAULT_BUFFER_SIZE)) >= 0 ) { out.write(buffer, 0 , read); transferred += read; } return transferred; }