CopyOnWriteArrayList类源码剖析
一、ArrayList的线程安全问题
1 | public static void main(String[] args) throws InterruptedException { |

ArrayList是线程不安全的List实现类,在多线程情况下可能会发生底层数组下标越界或值覆盖,通过add方法的源码我们一探究竟:
1 | public boolean add(E e) { |
在 JDK1.5 之前,如果想要使用并发安全的 List 只能选择 Vector。而 Vector 是一种老旧的集合,已经被淘汰。Vector 对于增删改查等方法基本都加了 synchronized,这种方式虽然能够保证同步,但这相当于对整个 Vector 加上了一把大锁,使得每个方法执行的时候都要去获得锁,导致性能非常低下。
JDK1.5 引入了 Java.util.concurrent(JUC)包,其中提供了很多线程安全且并发性能良好的容器,其中唯一的线程安全 List 实现就是 CopyOnWriteArrayList 。
1 | public static void main(String[] args) throws InterruptedException { |

二、ConpyOnWriteArrayList的简介
对于大部分业务场景来说,读取操作往往是远大于写入操作的。由于读取操作不会对原有数据进行修改,因此,对于每次读取都进行加锁其实是一种资源浪费。相比之下,我们应该允许多个线程同时访问 List 的内部数据,毕竟对于读取操作来说是安全的。
这种思路与 ReentrantReadWriteLock 读写锁的设计思想非常类似,即读读不互斥、读写互斥、写写互斥(只有读读不互斥)。CopyOnWriteArrayList 更进一步地实现了这一思想。为了将读操作性能发挥到极致,CopyOnWriteArrayList 中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
CopyOnWriteArrayList 线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略,从 CopyOnWriteArrayList 的名字就能看出了。
写入时复制(英语:Copy-on-write,简称 COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这个过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
这里再以 CopyOnWriteArrayList为例介绍:当需要修改( add,set、remove 等操作)CopyOnWriteArrayList 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
可以看出,写时复制机制非常适合读多写少的并发场景,能够极大地提高系统的并发性能。
不过,写时复制机制并不是银弹,其依然存在一些缺点,下面列举几点:
内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
三、ConpyOnWriteArrayList的定义
1 | public class CopyOnWriteArrayList<E> |
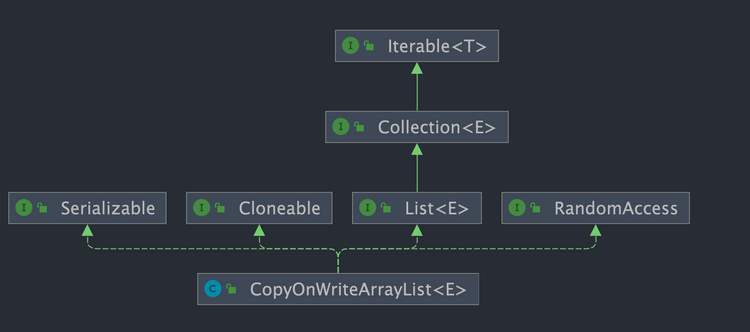
CopyOnWriteArrayList 实现了以下接口:
List: 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。RandomAccess:这是一个标志接口,表明实现这个接口的List集合是支持 快速随机访问 的。Cloneable:表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。Serializable: 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
四、ConpyOnWriteArrayList的构造方法
CopyOnWriteArrayList 中有一个无参构造函数和两个有参构造函数。
1 | // 创建一个空的 CopyOnWriteArrayList |
五、CopyOnWriteArrayList的add方法
CopyOnWriteArrayList 的 add()方法有三个版本:
add(E e):在CopyOnWriteArrayList的尾部插入元素。add(int index, E element):在CopyOnWriteArrayList的指定位置插入元素。addIfAbsent(E e):如果指定元素不存在,那么添加该元素。如果成功添加元素则返回 true。
这里以add(E e)为例进行介绍:
1 | // 插入元素到 CopyOnWriteArrayList 的尾部 |
从上面的源码可以看出:
add方法内部用到了synchronized加锁,保证了同步,避免了多线程写的时候会复制出多个副本出来。CopyOnWriteArrayList通过复制底层数组的方式实现写操作,即先创建一个新的数组来容纳新添加的元素,然后在新数组中进行写操作,最后将新数组赋值给底层数组的引用,替换掉旧的数组。这也就证明了我们前面说的:CopyOnWriteArrayList线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略。- 每次写操作都需要通过
Arrays.copyOf复制底层数组,时间复杂度是 O(n) 的,且会占用额外的内存空间。因此,CopyOnWriteArrayList适用于读多写少的场景,在写操作不频繁且内存资源充足的情况下,可以提升系统的性能表现。 CopyOnWriteArrayList中并没有类似于ArrayList的grow()方法扩容的操作。
Arrays.copyOf方法的时间复杂度是 O(n),其中 n 表示需要复制的数组长度。因为这个方法的实现原理是先创建一个新的数组,然后将源数组中的数据复制到新数组中,最后返回新数组。这个方法会复制整个数组,因此其时间复杂度与数组长度成正比,即 O(n)。值得注意的是,由于底层调用了系统级别的拷贝指令,因此在实际应用中这个方法的性能表现比较优秀,但是也需要注意控制复制的数据量,避免出现内存占用过高的情况。
六、CopyOnWriteArrayList的get方法
CopyOnWriteArrayList 的读取操作是基于内部数组 array 并没有发生实际的修改,因此在读取操作时不需要进行同步控制和锁操作,可以保证数据的安全性。这种机制下,多个线程可以同时读取列表中的元素。
1 | // 底层数组,只能通过getArray和setArray方法访问 |
不过,get方法是弱一致性的,在某些情况下可能读到旧的元素值。
get(int index)方法是分两步进行的:
- 通过
getArray()获取当前数组的引用; - 直接从数组中获取下标为 index 的元素。
这个过程并没有加锁,所以在并发环境下可能出现如下情况:
- 线程 1 调用
get(int index)方法获取值,内部通过getArray()方法获取到了 array 属性; - 线程 2 调用
CopyOnWriteArrayList的add、set、remove等修改方法时,内部通过setArray方法修改了array属性的值; - 线程 1 还是从旧的
array数组中取值。
七、CopyOnWriteArrayList的size方法
1 | public int size() { |
CopyOnWriteArrayList中的array数组每次复制都刚好能够容纳下所有元素,并不像ArrayList那样会预留一定的空间。因此,CopyOnWriteArrayList中并没有size属性,CopyOnWriteArrayList的底层数组的长度就是元素个数,因此size()方法只要返回数组长度就可以了。
八、CopyOnWriteArrayList的remove方法
CopyOnWriteArrayList删除元素相关的方法一共有 4 个:
remove(int index):移除此列表中指定位置上的元素,将任何后续元素向左移动(从它们的索引中减去 1)。boolean remove(Object o):删除此列表中首次出现的指定元素,如果不存在该元素则返回 false。boolean removeAll(Collection<?> c):从此列表中删除指定集合中包含的所有元素。void clear():移除此列表中的所有元素。
这里以remove(int index)为例进行介绍:
1 | public E remove(int index) { |
九、CopyOnWriteArrayList的contains方法
CopyOnWriteArrayList提供了两个用于判断指定元素是否在列表中的方法:
contains(Object o):判断是否包含指定元素。containsAll(Collection<?> c):判断是否保证指定集合的全部元素。
1 | // 判断是否包含指定元素 |