LongAdder类源码剖析
为了记录的方便主要参考了死磕LongAdder源码分析-彤哥读源码和LongAdder源码分析
一、LongAdder类的简介

当多个线程更新用于收集统计信息等目的而不是用于细粒度同步控制的公共总和时,此类通常比AtomicLong更可取。在低更新争用的情况下,这两个类具有相似的特征。但在高竞争情况下,此类的预期吞吐量明显更高,但代价是空间消耗更高。此类扩展了Number,但没有定义equals、hashCode和compareTo等方法,因为实例预计会发生变化,因此不能用作集合键。
二、LongAdder类的原理
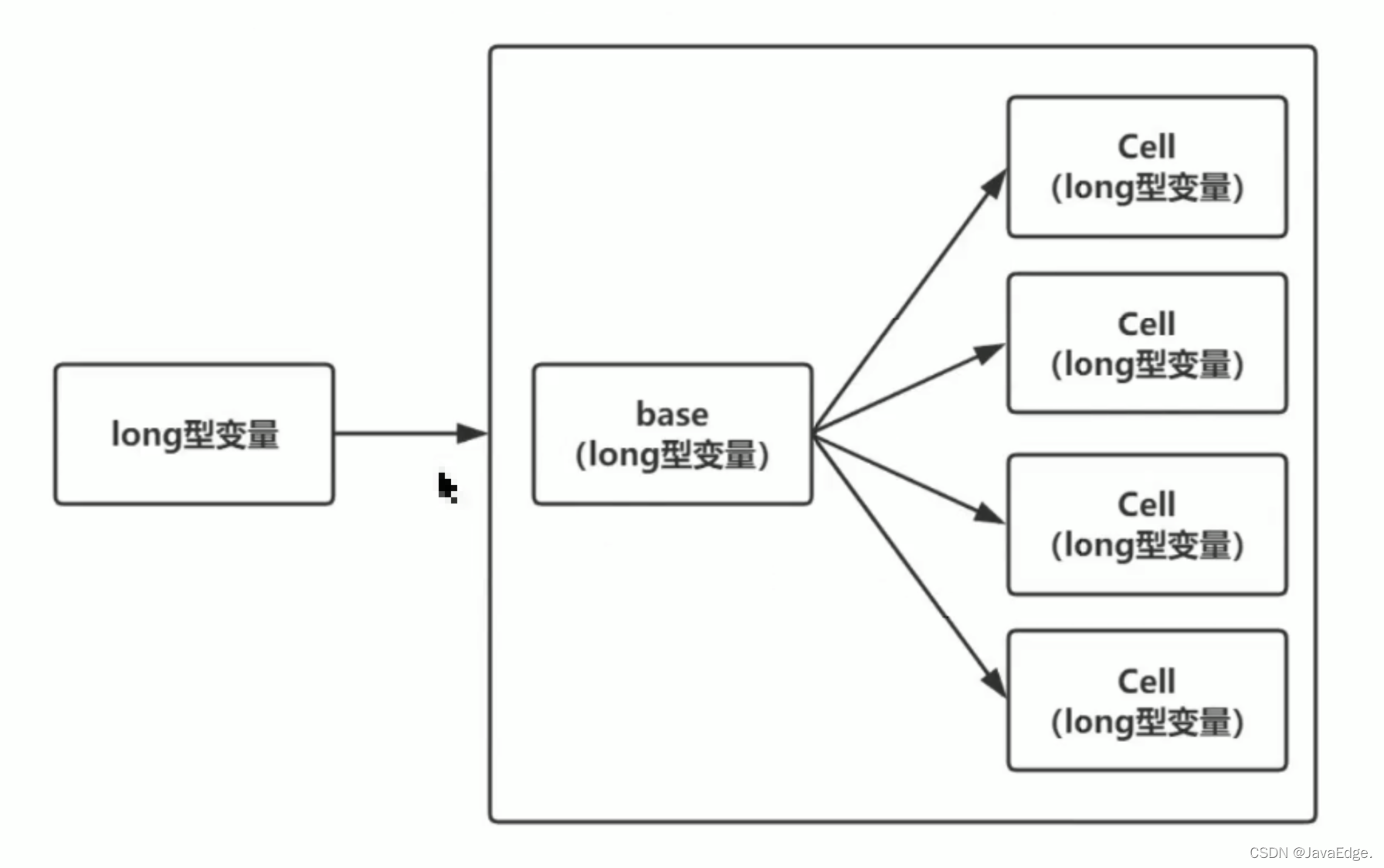
LongAdder的原理是,在最初无竞争时,只更新base的值,当有多线程竞争时通过分段的思想,让不同的线程更新不同的段,最后把这些段相加就得到了完整的LongAdder存储的值。如下图,把一个Long型拆成一个base变量外加多个Cell,每个Cell包装一个Long型变量。当多个线程并发累加的时:
- 如果并发度低,就直接加到base变量上
- 如果并发度高,冲突频繁,就平摊到这些Cell上
最后取值时,再把base和这些Cell求sum运算。
三、Striped64类的解析
下面的内容来自源码注释,第一手资料!
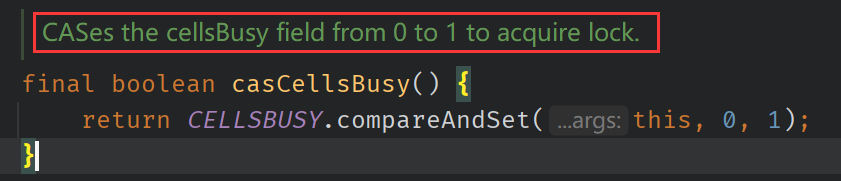
LongAdder继承自Striped64抽象类,Striped64类中定义了Cell内部类和各重要属性。此类维护一个延迟初始化的原子更新变量表即cells数组,以及一个额外的base字段,表的大小是2的幂次,索引使用屏蔽的每线程哈希码。此类中几乎所有声明都是包私有的,可以由子类直接访问,表条目Cell类即AtomicLong填充的变体(通过 @sun.misc.Contished)以减少缓存争用。对于大多数原子来说,填充是多余的,因为它们通常不规则地分散在内存中,因此不会互相干扰。但是驻留在数组中的原子对象往往会彼此相邻放置,因此在没有这种预防措施的情况下,通常会共享缓存行即伪共享(会对性能产生巨大的负面影响)。Cell类相对较大,我们避免在需要它们之前创建它们。当没有争用时,所有更新都对base字段进行;第一次争用时(base进行CAS更新时失败),表将初始化为大小2;在进一步争用时,表大小将加倍,直到达到大于或等于CPUS数量的最接近的2的幂。表槽保持为空 (null),直到需要它们为止。单个自旋锁(“cellsBusy”)用于初始化表和调整表大小,以及用新的Cell填充槽。当锁不可用时,线程尝试其他槽(或base字段)。通过ThreadLocalRandom维护的线程探测字段用作每线程哈希码。我们让它们保持未初始化时为零(如果它们以这种方式出现),直到它们在槽0上竞争,然后它们被初始化为通常不会与其他值冲突的值。执行更新操作时,失败的CAS会指示争用和/或表冲突。发生冲突时,如果表大小小于容量,则大小会加倍,除非其他线程持有锁。如果哈希槽为空,并且锁可用,则会创建一个新的Cell。否则,如果槽存在,则尝试CAS。通过双重散列进行重试,使用辅助散列 (Marsaglia XorShift) 来尝试找到空闲插槽。==表的大小是有上限的,因为当线程数多于CPUs时,假设每个线程都绑定到一个CPU,就会存在一个完美的哈希函数将线程映射到槽,从而消除冲突。当我们达到容量时,我们通过随机改变冲突线程的哈希码来搜索该映射。由于搜索是随机的,并且冲突只能通过CAS故障得知,因此收敛速度可能很慢,而且由于线程通常不会永远绑定到CPUS,因此可能根本不会发生。然而,尽管有这些限制,在这些情况下观察到的争用率通常很低。==
主要内部类
1 | // AtomicLong的填充变体仅支持原始访问和CAS |
CPU缓存行能带来免费加载数据的好处,所以处理数组性能非常高,但同时CPU缓存行也带来了弊端,多线程处理不相干的变量时会相互影响,也就是伪共享;Cell数组中的元素依次顺序排列,存在伪共享的问题,避免伪共享的主要思路就是让不相干的变量不要出现在同一个缓存行中,可以使用Java8提供的注解@sun.misc.Contended。
主要属性
1 | // cells数组,存储各个段的值 |
四、LongAdder类的方法
下面我们看一下LongAdder类的核心方法add:
1 | public void add(long x) { |
总结:开始竞争不激烈的时候直接CAS更新base变量,随着竞争的增加CAS可能失败,随即会创建Cell数组,后续的请求线程会根据线程的threadLocalRandomProbe值计算哈希槽位,如果该槽位为空则创建新Cell,否则对该Cell槽位进行CAS更新,一旦更新失败可能就要扩容了。
1 | final void longAccumulate(long x, LongBinaryOperator fn, |
longAccumulate方法可以看作是LongAdder类底层使用的最重要也是最难的方法,基本上可以分成5种情况:
- 情况1:线程待处理的Cell数组槽位为空,需要创建并初始化新Cell
- 情况2:线程CAS更新相应的Cell槽位失败,判断是否需要扩容,再次重试
- 情况3:线程多次CAS尝试更新对应的Cell槽位均失败,表明竞争过于激烈,需要进行Cell数组扩容
- 情况4:线程开始CAS更新base变量失败后发现Cell数组还未初始化,于是初始化容量为2的Cell数组
- 情况5:cellsBusy锁被占用而无法初始化,表明其他线程在尝试初始化Cell数组,于是CAS更新base变量,这无疑是一个兜底方案!
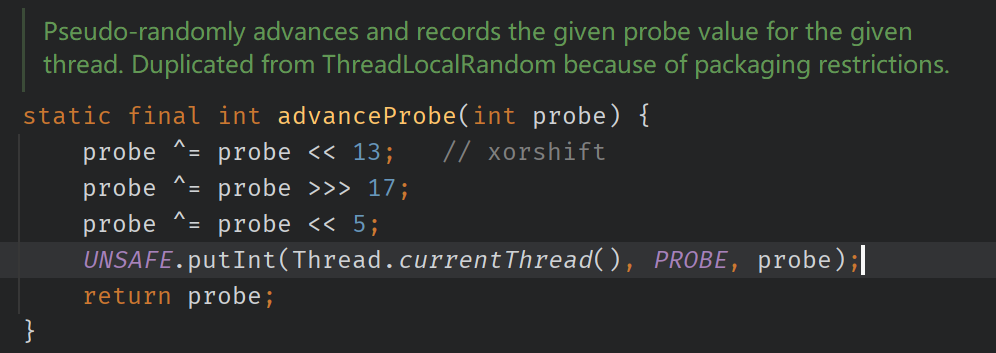
总结来说,LongAdder实例在开始竞争不激烈时通过CAS更新base值就能满足要求,当竞争非常激烈时,单纯靠base遍历维持这么大的并发度已经不切实际了,因此Cell数组就要闪亮登场了。刚开始Cell数组还没有初始化,这时我们通过CAS加锁配合双重检查完成Cell数组的初始化(对应的Cell槽位也初始化完成)。当然,Cell数组初始化后下一次的add操作通过线程安全的随机值散列找到对应的Cell槽位可能为空,这时还是通过CAS加锁配合双重检查完成Cell槽位的初始化。注意,Cell数组一旦初始化后我们就不再更新base了,而是更新Cell数组中的对应Cell实例,我们也知道并发的CAS更新同一个Cell实例可能会失败,此时我们还有尝试机会(下次尝试的Cell实例可能会变化,因为线程安全的随机值通过advanceProbe方法更新了),如果再次尝试失败表明冲突过于频繁,我们就会进行Cell数组的扩容操作来减少冲突(Cell数组的大小超过CPU核心数后就不会再扩容了)。
那么如何获取LongAdder当前的累积总和呢,其实就是通过sum方法获取最终一致性的结果(并非强一致性,因为没有加锁控制这一过程),因此,适合高并发的统计场景,而不适合要对某个Long型变量进行严格同步的场景。
1 | public long sum() { |
LongAdder减少冲突的方法以及在求和场景下比AtomicLong更高效。因为LongAdder在更新数值时并非对一个数进行更新,而是分散到多个Cell,这样在多线程的情况下可以有效的减少冲突和压力,使得更加高效。
有趣的是Cell数组最多扩容到大于或等于NCPU的最小二次幂,因为同一时刻最后只有NCPU个线程同时运行并操作Cell数组,而每个线程会根据自己的
threadLocalRandomProbe哈希值找到对应的Cell槽位,如果发生冲突即CAS失败会重新计算线程的该probe值,因此哈希分布随着时间会逐渐均匀,Cells数组的长度并不需要多长,达到CPU核心数即可。