Servlet高级之过滤器
1.Filter简单使用
在一个比较复杂的Web应用程序中,通常都有很多URL映射,对应的,也会有多个Servlet来处理URL。我们考察这样一个论坛应用程序:
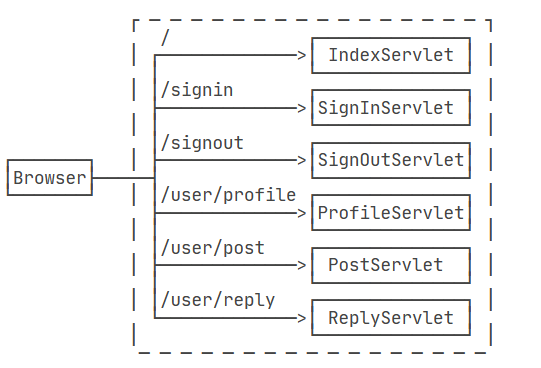
各个Servlet设计功能如下:
- IndexServlet:浏览帖子;
- SignInServlet:登录;
- SignOutServlet:登出;
- ProfileServlet:修改用户资料;
- PostServlet:发帖;
- ReplyServlet:回复。
其中,ProfileServlet、PostServlet和ReplyServlet都需要用户登录后才能操作,否则,应当直接跳转到登录页面。
我们可以直接把判断登录的逻辑写到这3个Servlet中,但是,同样的逻辑重复3次没有必要,并且,如果后续继续加Servlet并且也需要验证登录时,还需要继续重复这个检查逻辑。
为了把一些公用逻辑从各个Servlet中抽离出来,JavaEE的Servlet规范还提供了一种Filter组件,即过滤器,它的作用是,在HTTP请求到达Servlet之前,可以被一个或多个Filter预处理,类似打印日志、登录检查等逻辑,完全可以放到Filter中。
例如,我们编写一个最简单的EncodingFilter,它强制把输入和输出的编码设置为UTF-8:
1
2
3
4
5
6
7
8
9
10
| @WebFilter(urlPatterns = "/*")
public class EncodingFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
System.out.println("EncodingFilter:doFilter");
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
chain.doFilter(request, response);
}
}
|
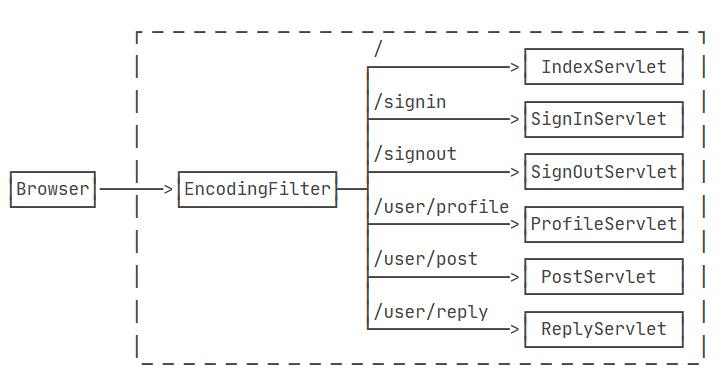
编写Filter时,必须实现Filter接口,在doFilter()方法内部,要继续处理请求,必须调用chain.doFilter()。最后,用@WebFilter注解标注该Filter需要过滤的URL。这里的/*表示所有路径。
添加了Filter之后,整个请求的处理架构如下:
还可以继续添加其他Filter,例如LogFilter:
1
2
3
4
5
6
7
8
| @WebFilter("/*")
public class LogFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
System.out.println("LogFilter: process " + ((HttpServletRequest) request).getRequestURI());
chain.doFilter(request, response);
}
}
|
多个Filter会组成一个链,每个请求都被链上的Filter依次处理:
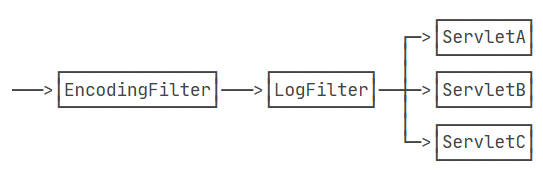
那么有多个Filter的时候,Filter的顺序如何指定?多个Filter按不同顺序处理会造成处理结果不同吗?
答案是Filter的顺序确实对处理的结果有影响。但遗憾的是,Servlet规范并没有对@WebFilter注解标注的Filter规定顺序。如果一定要给每个Filter指定顺序,就必须在web.xml文件中对这些Filter再配置一遍。
注意到上述两个Filter的过滤路径都是/*,即它们会对所有请求进行过滤。也可以编写只对特定路径进行过滤的Filter,例如AuthFilter:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @WebFilter("/user/*")
public class AuthFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
System.out.println("AuthFilter: check authentication");
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
if (req.getSession().getAttribute("user") == null) {
System.out.println("AuthFilter: not signin!");
resp.sendRedirect("/signin");
} else {
chain.doFilter(request, response);
}
}
}
|
注意到AuthFilter只过滤以/user/开头的路径,因此:
- 如果一个请求路径类似
/user/profile,那么它会被上述3个Filter依次处理;
- 如果一个请求路径类似
/test,那么它会被上述2个Filter依次处理(不会被AuthFilter处理)。
再注意观察AuthFilter,当用户没有登录时,在AuthFilter内部,直接调用resp.sendRedirect()发送重定向,且没有调用chain.doFilter(),因此,当用户没有登录时,请求到达AuthFilter后,不再继续处理,即后续的Filter和任何Servlet都没有机会处理该请求了。
可见,Filter可以有针对性地拦截或者放行HTTP请求。
如果一个Filter在当前请求中生效,但什么都没有做:
1
2
3
4
5
6
7
| @WebFilter("/*")
public class MyFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
}
}
|
那么,用户将看到一个空白页,因为请求没有继续处理,默认响应是200+空白输出。
如果Filter要使请求继续被处理,就一定要调用chain.doFilter()!
如果我们使用上一节介绍的MVC模式,即一个统一的DispatcherServlet入口,加上多个Controller,这种模式下Filter仍然是正常工作的。例如,一个处理/user/*的Filter实际上作用于那些处理/user/开头的Controller方法之前。
2.Filter修改请求
Filter可以对请求进行预处理,因此,我们可以把很多公共预处理逻辑放到Filter中完成。
考察这样一种需求:我们在Web应用中经常需要处理用户上传文件,例如,一个UploadServlet可以简单地编写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @WebServlet(urlPatterns = "/upload/file")
public class UploadServlet extends HttpServlet {
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
InputStream input = req.getInputStream();
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
for (;;) {
int len = input.read(buffer);
if (len == -1) {
break;
}
output.write(buffer, 0, len);
}
String uploadedText = output.toString(StandardCharsets.UTF_8);
PrintWriter pw = resp.getWriter();
pw.write("<h1>Uploaded:</h1>");
pw.write("<pre><code>");
pw.write(uploadedText);
pw.write("</code></pre>");
pw.flush();
}
}
|
但是要保证文件上传的完整性怎么办?我们知道,如果在上传文件的同时,把文件的哈希也传过来,服务器端做一个验证,就可以确保用户上传的文件一定是完整的。这个验证逻辑非常适合写在ValidateUploadFilter中,因为它可以复用。
我们先写一个简单的版本,快速实现ValidateUploadFilter的逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| @WebFilter("/upload/*")
public class ValidateUploadFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
String digest = req.getHeader("Signature-Method");
String signature = req.getHeader("Signature");
if (digest == null || digest.isEmpty() || signature == null || signature.isEmpty()) {
sendErrorPage(resp, "Missing signature.");
return;
}
MessageDigest md = getMessageDigest(digest);
InputStream input = new DigestInputStream(request.getInputStream(), md);
byte[] buffer = new byte[1024];
for (;;) {
int len = input.read(buffer);
if (len == -1) {
break;
}
}
String actual = toHexString(md.digest());
if (!signature.equals(actual)) {
sendErrorPage(resp, "Invalid signature.");
return;
}
chain.doFilter(request, response);
}
private String toHexString(byte[] digest) {
StringBuilder sb = new StringBuilder();
for (byte b : digest) {
sb.append(String.format("%02x", b));
}
return sb.toString();
}
private MessageDigest getMessageDigest(String name) throws ServletException {
try {
return MessageDigest.getInstance(name);
} catch (NoSuchAlgorithmException e) {
throw new ServletException(e);
}
}
private void sendErrorPage(HttpServletResponse resp, String errorMessage) throws IOException {
resp.setStatus(HttpServletResponse.SC_BAD_REQUEST);
PrintWriter pw = resp.getWriter();
pw.write("<html><body><h1>");
pw.write(errorMessage);
pw.write("</h1></body></html>");
pw.flush();
}
}
|
这个ValidateUploadFilter的逻辑似乎没有问题,我们可以用curl命令测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| $ curl http://localhost:8080/upload/file -v -d 'test-data' \
-H 'Signature-Method: SHA-1' \
-H 'Signature: 7115e9890f5b5cc6914bdfa3b7c011db1cdafedb' \
-H 'Content-Type: application/octet-stream'
* Trying ::1...
* TCP_NODELAY set
* Connected to localhost (::1) port 8080 (#0)
> POST /upload/file HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.64.1
> Accept: */*
> Signature-Method: SHA-1
> Signature: 7115e9890f5b5cc6914bdfa3b7c011db1cdafedb
> Content-Type: application/octet-stream
> Content-Length: 9
>
* upload completely sent off: 9 out of 9 bytes
< HTTP/1.1 200
< Transfer-Encoding: chunked
< Date: Thu, 30 Jan 2020 13:56:39 GMT
<
* Connection #0 to host localhost left intact
<h1>Uploaded:</h1><pre><code></code></pre>
* Closing connection 0
|
ValidateUploadFilter对签名进行验证的逻辑是没有问题的,但是,细心的童鞋注意到,UploadServlet并未读取到任何数据!
这里的原因是对HttpServletRequest进行读取时,只能读取一次。如果Filter调用getInputStream()读取了一次数据,后续Servlet处理时,再次读取,将无法读到任何数据。怎么办?
这个时候,我们需要一个“伪造”的HttpServletRequest,具体做法是使用代理模式,对getInputStream()和getReader()返回一个新的流:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| class ReReadableHttpServletRequest extends HttpServletRequestWrapper {
private byte[] body;
private boolean open = false;
public ReReadableHttpServletRequest(HttpServletRequest request, byte[] body) {
super(request);
this.body = body;
}
public ServletInputStream getInputStream() throws IOException {
if (open) {
throw new IllegalStateException("Cannot re-open input stream!");
}
open = true;
return new ServletInputStream() {
private int offset = 0;
public boolean isFinished() {
return offset >= body.length;
}
public boolean isReady() {
return true;
}
public void setReadListener(ReadListener listener) {
}
public int read() throws IOException {
if (offset >= body.length) {
return -1;
}
int n = body[offset] & 0xff;
offset++;
return n;
}
};
}
public BufferedReader getReader() throws IOException {
if (open) {
throw new IllegalStateException("Cannot re-open reader!");
}
open = true;
return new BufferedReader(new InputStreamReader(new ByteArrayInputStream(body), "UTF-8"));
}
}
|
注意观察ReReadableHttpServletRequest的构造方法,它保存了ValidateUploadFilter读取的byte[]内容,并在调用getInputStream()时通过byte[]构造了一个新的ServletInputStream。
然后,我们在ValidateUploadFilter中,把doFilter()调用时传给下一个处理者的HttpServletRequest替换为我们自己“伪造”的ReReadableHttpServletRequest:
1
2
3
4
5
| public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
...
chain.doFilter(new ReReadableHttpServletRequest(req, output.toByteArray()), response);
}
|
再注意到我们编写ReReadableHttpServletRequest时,是从HttpServletRequestWrapper继承,而不是直接实现HttpServletRequest接口。这是因为,Servlet的每个新版本都会对接口增加一些新方法,从HttpServletRequestWrapper继承可以确保新方法被正确地覆写了,因为HttpServletRequestWrapper是由Servlet的jar包提供的,目的就是为了让我们方便地实现对HttpServletRequest接口的代理。
我们总结一下对HttpServletRequest接口进行代理的步骤:
- 从
HttpServletRequestWrapper继承一个XxxHttpServletRequest,需要传入原始的HttpServletRequest实例;
- 覆写某些方法,使得新的
XxxHttpServletRequest实例看上去“改变”了原始的HttpServletRequest实例;
- 在
doFilter()中传入新的XxxHttpServletRequest实例。
虽然整个Filter的代码比较复杂,但它的好处在于:这个Filter在整个处理链中实现了灵活的“可插拔”特性,即是否启用对Web应用程序的其他组件(Filter、Servlet)完全没有影响。
3.Filter修改响应
既然我们能通过Filter修改HttpServletRequest,自然也能修改HttpServletResponse,因为这两者都是接口。
我们来看一下在什么情况下我们需要修改HttpServletResponse。
假设我们编写了一个Servlet,但由于业务逻辑比较复杂,处理该请求需要耗费很长的时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @WebServlet(urlPatterns = "/slow/hello")
public class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
PrintWriter pw = resp.getWriter();
pw.write("<h1>Hello, world!</h1>");
pw.flush();
}
}
|
好消息是每次返回的响应内容是固定的,因此,如果我们能使用缓存将结果缓存起来,就可以大大提高Web应用程序的运行效率。
缓存逻辑最好不要在Servlet内部实现,因为我们希望能复用缓存逻辑,所以,编写一个CacheFilter最合适:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @WebFilter("/slow/*")
public class CacheFilter implements Filter {
private Map<String, byte[]> cache = new ConcurrentHashMap<>();
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
String url = req.getRequestURI();
byte[] data = this.cache.get(url);
resp.setHeader("X-Cache-Hit", data == null ? "No" : "Yes");
if (data == null) {
CachedHttpServletResponse wrapper = new CachedHttpServletResponse(resp);
chain.doFilter(request, wrapper);
data = wrapper.getContent();
cache.put(url, data);
}
ServletOutputStream output = resp.getOutputStream();
output.write(data);
output.flush();
}
}
|
实现缓存的关键在于,调用doFilter()时,我们不能传入原始的HttpServletResponse,因为这样就会写入Socket,我们也就无法获取下游组件写入的内容。如果我们传入的是“伪造”的HttpServletResponse,让下游组件写入到我们预设的ByteArrayOutputStream,我们就“截获”了下游组件写入的内容,于是,就可以把内容缓存起来,再通过原始的HttpServletResponse实例写入到网络。
这个CachedHttpServletResponse实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class CachedHttpServletResponse extends HttpServletResponseWrapper {
private boolean open = false;
private ByteArrayOutputStream output = new ByteArrayOutputStream();
public CachedHttpServletResponse(HttpServletResponse response) {
super(response);
}
public PrintWriter getWriter() throws IOException {
if (open) {
throw new IllegalStateException("Cannot re-open writer!");
}
open = true;
return new PrintWriter(output, false, StandardCharsets.UTF_8);
}
public ServletOutputStream getOutputStream() throws IOException {
if (open) {
throw new IllegalStateException("Cannot re-open output stream!");
}
open = true;
return new ServletOutputStream() {
public boolean isReady() {
return true;
}
public void setWriteListener(WriteListener listener) {
}
public void write(int b) throws IOException {
output.write(b);
}
};
}
public byte[] getContent() {
return output.toByteArray();
}
}
|
可见,如果我们想要修改响应,就可以通过HttpServletResponseWrapper构造一个“伪造”的HttpServletResponse,这样就能拦截到写入的数据。修改响应时,最后不要忘记把数据写入原始的HttpServletResponse实例。
这个CacheFilter同样是一个“可插拔”组件,它是否启用不影响Web应用程序的其他组件(Filter、Servlet)。