String类源码剖析 一、String类的简介 该String类表示字符串。Java程序中的所有字符串文本(如”abc”)都作为此类的实例实现。字符串是常量,它们的值在创建后无法更改。字符串缓冲区(也就是StringBuffer或者StringBuilder)支持可变字符串。由于字符串对象是不可变的,因此可以共享它们(不存在线程安全问题)。下面是如何使用字符串的更多示例:
1 2 3 4 5 System.out.println("abc" ); String cde = "cde" ;System.out.println("abc" + cde); String c = "abc" .substring(2 ,3 );String d = cde.substring(1 , 2 );
下面是String类的详细解读,需要注意特别注意String的拼接操作和对象转String操作。例如,javac编译器可能会利用StringBuffer、StringBuilder、StringConcatFactory等实现字符串拼接操作,而字符串转换操作往往利用从Object类继承的toString方法实现。
当String采用UTF-16编码格式时,辅助多语言平面的字符由一项代理对表示,String类中的索引值表示char码元,因此一个辅助字符在String中占据两个索引位置(两个码元)。String类提供了处理码位的方法以及处理码元(char值)的方法。关于编码相关的内容参考Character类以及Java基础-实用类 | 大军的秘密花园 (hulingf.github.io) 。
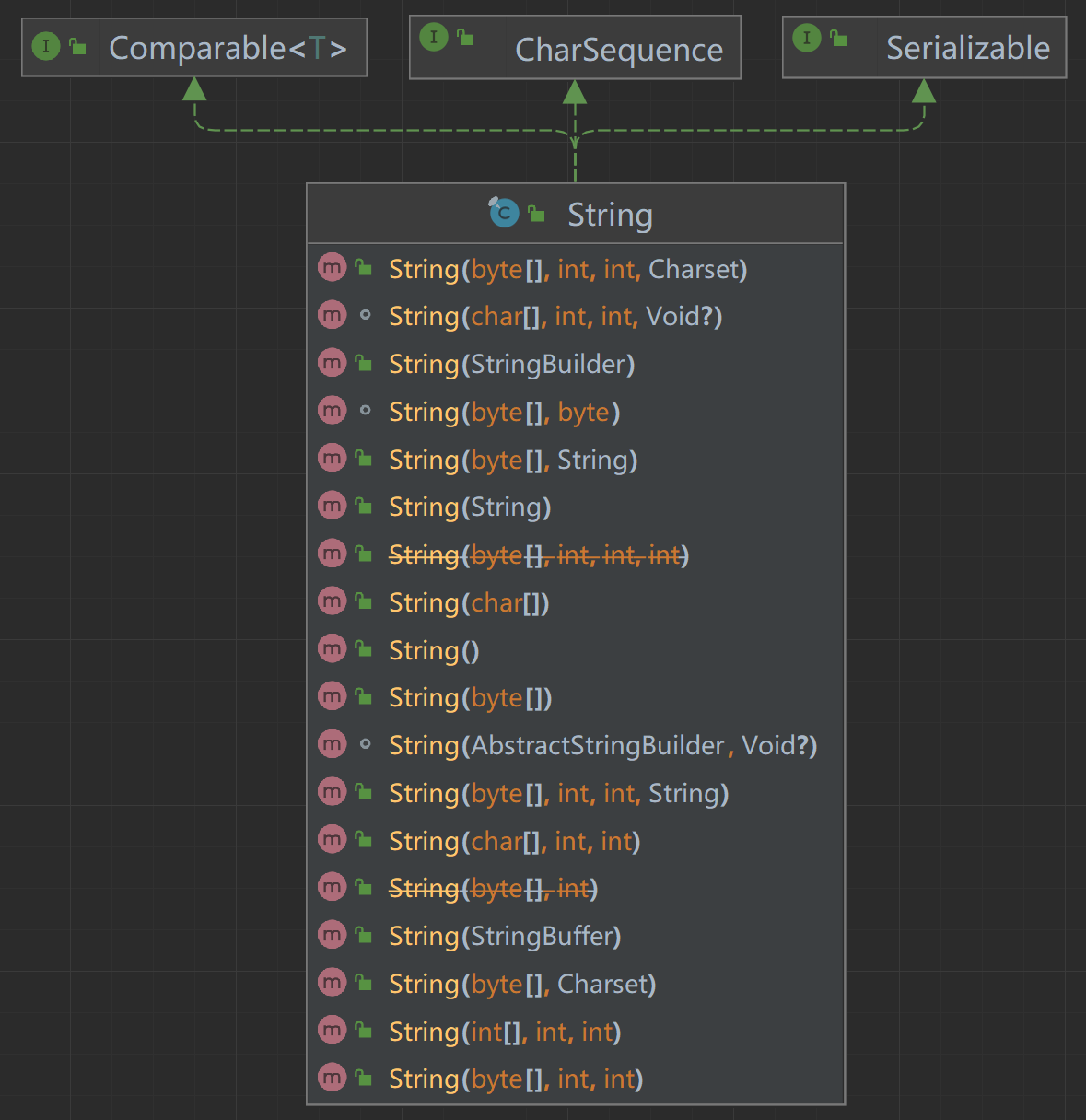
二、String类的重要字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public final class String implements Serializable , Comparable<String>, CharSequence { @Stable private final byte [] value; private final byte coder; private int hash; private static final long serialVersionUID = -6849794470754667710L ; static final boolean COMPACT_STRINGS = true ; private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField [0 ]; static final byte LATIN1 = 0 ; static final byte UTF16 = 1 ; }
从实现的接口角度看String:
String类被final关键字修饰,因此不能被继承。
String的成员变量value使用final修饰,因此是不可变的,线程安全;
String类实现了Serializable接口,可以实现序列化。
String类实现了Comparable,可以比较大小。
String类实现了CharSequence接口,String本质是个数组,低版本中是char数组,JDK9以后优化成byte数组,从String的成员变量value就可以看出来。
关于value字段:字符存储的字节数组,该字段受虚拟机信任,如果String实例是常量,则该字段会被常量折叠。
关于coder字段:用于对value中的字节进行编码的编码标识符。本实现支持的编码值为LATIN1和UTF16。
关于hash字段:缓存的字符串的hashcode值,默认为0。
关于serialVersionUID字段:serialVersionUID是一个序列化版本号,Java 通过这个 UID 来判定反序列化时的字节流与本地类的一致性,如果相同则可以进行反序列化,不同就会异常。
关于serialPersistentFields字段:这个用来保存要进行序列化的字段。默认情况下,所有的非transient、非static修饰的字段都会被序列化,但可以用这个来选择序列化的字段。
关于COMPACT_STRINGS字段:如果禁用了字符串压缩,value中的字节总是以 UTF16 编码。对于有几种可能实现路径的方法,如果禁用字符串压缩,则只采用一种编码路径。对于优化 JIT 编译器来说,实例字段值通常是不透明的。因此,在对性能敏感的地方,首先要明确检查静态布尔值 COMPACT_STRINGS,然后再检查 coder 字段,因为静态布尔值 COMPACT_STRINGS 会被优化的 JIT 编译器常量折叠。对于代码如: if (coder == LATIN1) { … } 可以更优化地写成 if (coder() == LATIN1) { … } 或if (COMPACT_STRINGS && coder == LATIN1) { … } ,优化的 JIT 编译器可以将上述条件折叠为 COMPACT_STRINGS == true => if (coder == LATIN1) { … } 或 COMPACT_STRINGS == false => if (false) { … }。
三、String类的构造方法 第一个构造方法是无参构造方法,因为String是不可变类,因此创建一个空的String类没有必要!
1 2 3 4 public String () { this .value = "" .value; this .coder = "" .coder; }
第二个构造方法是复制构造方法,注意value是个字节数组,直接赋值相当于两个字符型的value引用都指向同一个字节数组,但是因为String中的字节数组被final修饰不可变且String类没有暴露任何修改字节数组内容的方法 ,因此共享是允许的!
1 2 3 4 5 public String (String original) { this .value = original.value; this .coder = original.coder; this .hash = original.hash; }
第三个构造方法根据给定的char数组创建一个String对象,需要一一复制字符数组的内容,对字符数组的后续修改不会影响该String对象!
1 2 3 public String (char value[]) { this (value, 0 , value.length, null ); }
第四个构造方法与上一个类似,不过更加灵活,能够控制char数组的拷贝起始位置和拷贝长度,同时内部函数会检查参数有效性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public String (char value[], int offset, int count) { this (value, offset, count, rangeCheck(value, offset, count)); } private static Void rangeCheck (char [] value, int offset, int count) { checkBoundsOffCount(offset, count, value.length); return null ; } static void checkBoundsOffCount (int offset, int count, int length) { if (offset < 0 || count < 0 || offset > length - count) { throw new StringIndexOutOfBoundsException ( "offset " + offset + ", count " + count + ", length " + length); } }
第五个构造方法是包私有的,尾部的Void参数是为了区别于其他(公开的)的构造方法,默认情况下COMPACT_STRING是开启的,关闭该选项可以使用-XX:-CompactStrings参数,如果字符数组的所有字符元素都位于Lantin1的范围内(0x00~0xFF)则使用单字节表示一个char码元,否则使用UTF-16即双字节表示一个char码元(BMP内的字符,如果是辅助平面的字符需要4字节即2个char码元)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 String(char [] value, int off, int len, Void sig) { if (len == 0 ) { this .value = "" .value; this .coder = "" .coder; return ; } if (COMPACT_STRINGS) { byte [] val = StringUTF16.compress(value, off, len); if (val != null ) { this .value = val; this .coder = LATIN1; return ; } } this .coder = UTF16; this .value = StringUTF16.toBytes(value, off, len); }
观察StringUTF16.compress方法,逐一判断char数组的元素是否超出Latin1的最大表示范围0xFF,如果未超出则把char数组的char元素一一强转为byte类型,否则使用UTF-16编码方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static byte [] compress(char [] val, int off, int len) { byte [] ret = new byte [len]; if (compress(val, off, ret, 0 , len) == len) { return ret; } return null ; } @HotSpotIntrinsicCandidate public static int compress (char [] src, int srcOff, byte [] dst, int dstOff, int len) { for (int i = 0 ; i < len; i++) { char c = src[srcOff]; if (c > 0xFF ) { len = 0 ; break ; } dst[dstOff] = (byte )c; srcOff++; dstOff++; } return len; }
观察StringUTF16.toBytes方法,所做的工作就是把char数组转换成byte数组,具体看代码注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public static byte [] toBytes(char [] value, int off, int len) { byte [] val = newBytesFor(len); for (int i = 0 ; i < len; i++) { putChar(val, i, value[off]); off++; } return val; } public static byte [] newBytesFor(int len) { if (len < 0 ) { throw new NegativeArraySizeException (); } if (len > MAX_LENGTH) { throw new OutOfMemoryError ("UTF16 String size is " + len + ", should be less than " + MAX_LENGTH); } return new byte [len << 1 ]; } static void putChar (byte [] val, int index, int c) { assert index >= 0 && index < length(val) : "Trusted caller missed bounds check" ; index <<= 1 ; val[index++] = (byte )(c >> HI_BYTE_SHIFT); val[index] = (byte )(c >> LO_BYTE_SHIFT); } public static int length (byte [] value) { return value.length >> 1 ; } static final int HI_BYTE_SHIFT;static final int LO_BYTE_SHIFT;static {if (isBigEndian()) { HI_BYTE_SHIFT = 8 ; LO_BYTE_SHIFT = 0 ; } else { HI_BYTE_SHIFT = 0 ; LO_BYTE_SHIFT = 8 ; } }
第六个构造函数是根据int码位数组创建String对象的,这跟上一个构造方法类似,不过需要注意的是采用UTF-16编码方式时需要计算int码位数组对应的byte数组的长度,尤其是==辅助平面的码位需要两个char码元==。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public String (int [] codePoints, int offset, int count) { checkBoundsOffCount(offset, count, codePoints.length); if (count == 0 ) { this .value = "" .value; this .coder = "" .coder; return ; } if (COMPACT_STRINGS) { byte [] val = StringLatin1.toBytes(codePoints, offset, count); if (val != null ) { this .coder = LATIN1; this .value = val; return ; } } this .coder = UTF16; this .value = StringUTF16.toBytes(codePoints, offset, count); }
观察StringLatin1.toBytes方法,使用单字节表示一个码位,压缩了String对象的占用空间(相比于UTF-16减少了50%):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static byte [] toBytes(int [] val, int off, int len) { byte [] ret = new byte [len]; for (int i = 0 ; i < len; i++) { int cp = val[off++]; if (!canEncode(cp)) { return null ; } ret[i] = (byte )cp; } return ret; } public static boolean canEncode (int cp) { return cp >>> 8 == 0 ; }
观察StringUTF16.toBytes,具体逻辑见代码注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public static byte [] toBytes(int [] val, int index, int len) { final int end = index + len; int n = len; for (int i = index; i < end; i++) { int cp = val[i]; if (Character.isBmpCodePoint(cp)) continue ; else if (Character.isValidCodePoint(cp)) n++; else throw new IllegalArgumentException (Integer.toString(cp)); } byte [] buf = newBytesFor(n); for (int i = index, j = 0 ; i < end; i++, j++) { int cp = val[i]; if (Character.isBmpCodePoint(cp)) { putChar(buf, j, cp); } else { putChar(buf, j++, Character.highSurrogate(cp)); putChar(buf, j, Character.lowSurrogate(cp)); } } return buf; } public static byte [] newBytesFor(int len) { if (len < 0 ) { throw new NegativeArraySizeException (); } if (len > MAX_LENGTH) { throw new OutOfMemoryError ("UTF16 String size is " + len + ", should be less than " + MAX_LENGTH); } return new byte [len << 1 ]; } public static boolean isBmpCodePoint (int codePoint) { return codePoint >>> 16 == 0 ; } public static boolean isValidCodePoint (int codePoint) { int plane = codePoint >>> 16 ; return plane < ((MAX_CODE_POINT + 1 ) >>> 16 ); } public static char highSurrogate (int codePoint) { return (char ) ((codePoint >>> 10 ) + (MIN_HIGH_SURROGATE - (MIN_SUPPLEMENTARY_CODE_POINT >>> 10 ))); } public static char lowSurrogate (int codePoint) { return (char ) ((codePoint & 0x3ff ) + MIN_LOW_SURROGATE); } static void putChar (byte [] val, int index, int c) { assert index >= 0 && index < length(val) : "Trusted caller missed bounds check" ; index <<= 1 ; val[index++] = (byte )(c >> HI_BYTE_SHIFT); val[index] = (byte )(c >> LO_BYTE_SHIFT); }
四、String类的一些方法 length()方法返回String对象中char码元的数量:
1 2 3 4 5 6 7 8 public int length () { return value.length >> coder(); } byte coder () { return COMPACT_STRINGS ? coder : UTF16; } @Native static final byte LATIN1 = 0 ;@Native static final byte UTF16 = 1 ;
isEmpty()方法判断String对象是否是空字符串:
1 2 3 public boolean isEmpty () { return value.length == 0 ; }
isLatin1()方法判断String对象是否采用Latin1编码方式:
1 2 3 private boolean isLatin1 () { return COMPACT_STRINGS && coder == LATIN1; }
charAt(int index)方法返回char指定索引处的值。索引的范围从0到length()-1。char序列的第一个值在索引0处,下一个值在索引1处,依此类推,就像数组索引一样。如果索引指定的chat值是代理项,则返回代理项值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public char charAt (int index) { if (isLatin1()) { return StringLatin1.charAt(value, index); } else { return StringUTF16.charAt(value, index); } } public static char charAt (byte [] value, int index) { if (index < 0 || index >= value.length) { throw new StringIndexOutOfBoundsException (index); } return (char )(value[index] & 0xff ); } public static char charAt (byte [] value, int index) { checkIndex(index, value); return getChar(value, index); } public static void checkIndex (int off, byte [] val) { String.checkIndex(off, length(val)); } public static int length (byte [] value) { return value.length >> 1 ; } static void checkIndex (int index, int length) { if (index < 0 || index >= length) { throw new StringIndexOutOfBoundsException ("index " + index + ",length " + length); } } static char getChar (byte [] val, int index) { assert index >= 0 && index < length(val) : "Trusted caller missed bounds check" ; index <<= 1 ; return (char )(((val[index++] & 0xff ) << HI_BYTE_SHIFT) | ((val[index] & 0xff ) << LO_BYTE_SHIFT)); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public int codePointAt (int index) { if (isLatin1()) { checkIndex(index, value.length); return value[index] & 0xff ; } int length = value.length >> 1 ; checkIndex(index, length); return StringUTF16.codePointAt(value, index, length); } public static int codePointAt (byte [] value, int index, int end) { return codePointAt(value, index, end, false ); } private static int codePointAt (byte [] value, int index, int end, boolean checked) { assert index < end; if (checked) { checkIndex(index, value); } char c1 = getChar(value, index); if (Character.isHighSurrogate(c1) && ++index < end) { if (checked) { checkIndex(index, value); } char c2 = getChar(value, index); if (Character.isLowSurrogate(c2)) { return Character.toCodePoint(c1, c2); } } return c1; } public static int toCodePoint (char high, char low) { return ((high << 10 ) + low) + (MIN_SUPPLEMENTARY_CODE_POINT - (MIN_HIGH_SURROGATE << 10 ) - MIN_LOW_SURROGATE);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public void getChars (int srcBegin, int srcEnd, char dst[], int dstBegin) { checkBoundsBeginEnd(srcBegin, srcEnd, length()); checkBoundsOffCount(dstBegin, srcEnd - srcBegin, dst.length); if (isLatin1()) { StringLatin1.getChars(value, srcBegin, srcEnd, dst, dstBegin); } else { StringUTF16.getChars(value, srcBegin, srcEnd, dst, dstBegin); } } static void checkBoundsBeginEnd (int begin, int end, int length) { if (begin < 0 || begin > end || end > length) { throw new StringIndexOutOfBoundsException ( "begin " + begin + ", end " + end + ", length " + length); } } static void checkBoundsOffCount (int offset, int count, int length) { if (offset < 0 || count < 0 || offset > length - count) { throw new StringIndexOutOfBoundsException ( "offset " + offset + ", count " + count + ", length " + length); } } public static void getChars (byte [] value, int srcBegin, int srcEnd, char dst[], int dstBegin) { inflate(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); } @HotSpotIntrinsicCandidate public static void inflate (byte [] src, int srcOff, char [] dst, int dstOff, int len) { for (int i = 0 ; i < len; i++) { dst[dstOff++] = (char )(src[srcOff++] & 0xff ); } } public static void getChars (byte [] value, int srcBegin, int srcEnd, char dst[], int dstBegin) { if (srcBegin < srcEnd) { checkBoundsOffCount(srcBegin, srcEnd - srcBegin, value); } for (int i = srcBegin; i < srcEnd; i++) { dst[dstBegin++] = getChar(value, i); } } static char getChar (byte [] val, int index) { assert index >= 0 && index < length(val) : "Trusted caller missed bounds check" ; index <<= 1 ; return (char )(((val[index++] & 0xff ) << HI_BYTE_SHIFT) | ((val[index] & 0xff ) << LO_BYTE_SHIFT)); }
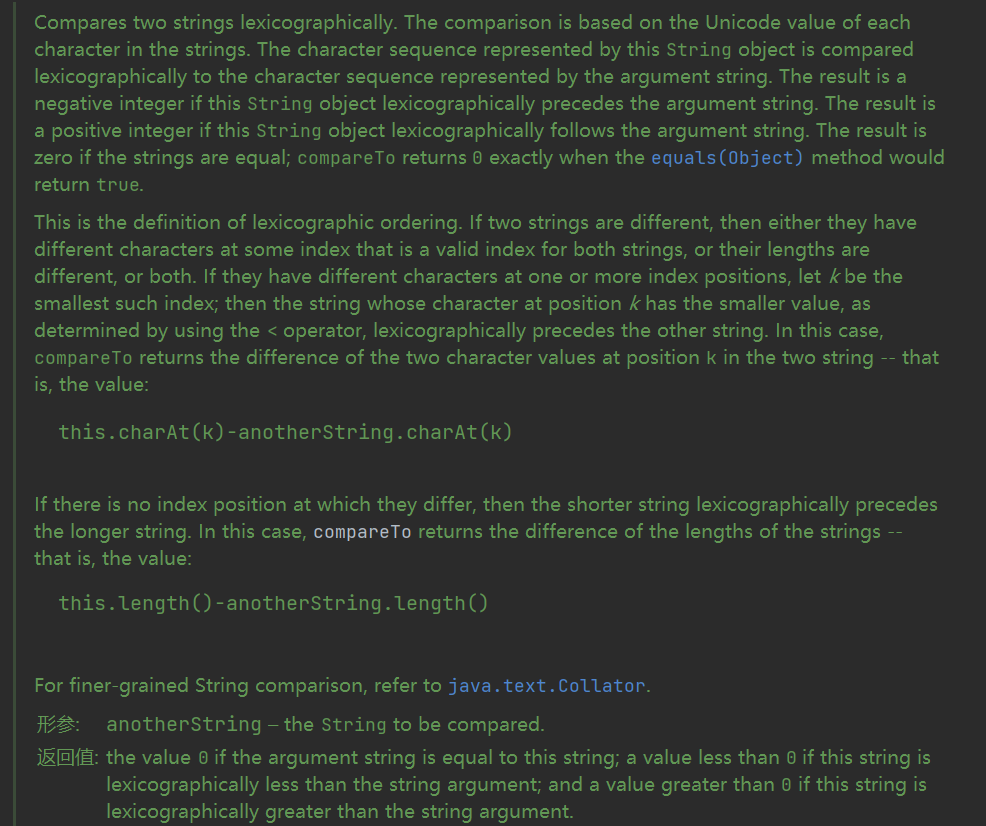
五、String类的equals方法 将此字符串与指定的对象进行比较。当且仅当参数不是null,并且是与此对象具有相同字符序列的String对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public boolean equals (Object anObject) { if (this == anObject) { return true ; } if (anObject instanceof String) { String aString = (String)anObject; if (coder() == aString.coder()) { return isLatin1() ? StringLatin1.equals(value, aString.value) : StringUTF16.equals(value, aString.value); } } return false ; } public static boolean equals (byte [] value, byte [] other) { if (value.length == other.length) { for (int i = 0 ; i < value.length; i++) { if (value[i] != other[i]) { return false ; } } return true ; } return false ; } public static boolean equals (byte [] value, byte [] other) { if (value.length == other.length) { int len = value.length >> 1 ; for (int i = 0 ; i < len; i++) { if (getChar(value, i) != getChar(other, i)) { return false ; } } return true ; } return false ; }
六、String类的compareTo方法
String继承Comparable接口并重写compareTo方法,比较的原则是从前往后逐个char码元按字典顺序比较大小,如果都相同则比较String对象的长度!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public int compareTo (String anotherString) { byte v1[] = value; byte v2[] = anotherString.value; if (coder() == anotherString.coder()) { return isLatin1() ? StringLatin1.compareTo(v1, v2) : StringUTF16.compareTo(v1, v2); } return isLatin1() ? StringLatin1.compareToUTF16(v1, v2) : StringUTF16.compareToLatin1(v1, v2); } public static int compareTo (byte [] value, byte [] other) { int len1 = value.length; int len2 = other.length; return compareTo(value, other, len1, len2); } public static int compareTo (byte [] value, byte [] other, int len1, int len2) { int lim = Math.min(len1, len2); for (int k = 0 ; k < lim; k++) { if (value[k] != other[k]) { return getChar(value, k) - getChar(other, k); } } return len1 - len2; } public static int compareTo (byte [] value, byte [] other) { int len1 = length(value); int len2 = length(other); return compareValues(value, other, len1, len2); } private static int compareValues (byte [] value, byte [] other, int len1, int len2) { int lim = Math.min(len1, len2); for (int k = 0 ; k < lim; k++) { char c1 = getChar(value, k); char c2 = getChar(other, k); if (c1 != c2) { return c1 - c2; } } return len1 - len2; } public static int compareToUTF16 (byte [] value, byte [] other) { int len1 = length(value); int len2 = StringUTF16.length(other); return compareToUTF16Values(value, other, len1, len2); } private static int compareToUTF16Values (byte [] value, byte [] other, int len1, int len2) { int lim = Math.min(len1, len2); for (int k = 0 ; k < lim; k++) { char c1 = getChar(value, k); char c2 = StringUTF16.getChar(other, k); if (c1 != c2) { return c1 - c2; } } return len1 - len2; } public static int compareToLatin1 (byte [] value, byte [] other) { return -StringLatin1.compareToUTF16(other, value); }
七、String类的startWith方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public boolean startsWith (String prefix, int toffset) { if (toffset < 0 || toffset > length() - prefix.length()) { return false ; } byte ta[] = value; byte pa[] = prefix.value; int po = 0 ; int pc = pa.length; if (coder() == prefix.coder()) { int to = isLatin1() ? toffset : toffset << 1 ; while (po < pc) { if (ta[to++] != pa[po++]) { return false ; } } } else { if (isLatin1()) { return false ; } while (po < pc) { if (StringUTF16.getChar(ta, toffset++) != (pa[po++] & 0xff )) { return false ; } } } return true ; } public boolean startsWith (String prefix) { return startsWith(prefix, 0 ); } public boolean endsWith (String suffix) { return startsWith(suffix, length() - suffix.length()); }
八、String类的hashCode方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public int hashCode () { int h = hash; if (h == 0 && value.length > 0 ) { hash = h = isLatin1() ? StringLatin1.hashCode(value) : StringUTF16.hashCode(value); } return h; } public static int hashCode (byte [] value) { int h = 0 ; for (byte v : value) { h = 31 * h + (v & 0xff ); } return h; } public static int hashCode (byte [] value) { int h = 0 ; int length = value.length >> 1 ; for (int i = 0 ; i < length; i++) { h = 31 * h + getChar(value, i); } return h; }
九、String类的subString方法 subString方法是截取子字符串的方法,截取的开始索引范围是0~length。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public String substring (int beginIndex) { if (beginIndex < 0 ) { throw new StringIndexOutOfBoundsException (beginIndex); } int subLen = length() - beginIndex; if (subLen < 0 ) { throw new StringIndexOutOfBoundsException (subLen); } if (beginIndex == 0 ) { return this ; } return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen) : StringUTF16.newString(value, beginIndex, subLen); } public static String newString (byte [] val, int index, int len) { return new String (Arrays.copyOfRange(val, index, index + len), LATIN1); } public static String newString (byte [] val, int index, int len) { if (String.COMPACT_STRINGS) { byte [] buf = compress(val, index, len); if (buf != null ) { return new String (buf, LATIN1); } } int last = index + len; return new String (Arrays.copyOfRange(val, index << 1 , last << 1 ), UTF16); } public static byte [] compress(byte [] val, int off, int len) { byte [] ret = new byte [len]; if (compress(val, off, ret, 0 , len) == len) { return ret; } return null ; } public static int compress (byte [] src, int srcOff, byte [] dst, int dstOff, int len) { checkBoundsOffCount(srcOff, len, src); for (int i = 0 ; i < len; i++) { char c = getChar(src, srcOff); if (c > 0xFF ) { len = 0 ; break ; } dst[dstOff] = (byte )c; srcOff++; dstOff++; } return len; } static char getChar (byte [] val, int index) { assert index >= 0 && index < length(val) : "Trusted caller missed bounds check" ; index <<= 1 ; return (char )(((val[index++] & 0xff ) << HI_BYTE_SHIFT) | ((val[index] & 0xff ) << LO_BYTE_SHIFT)); }
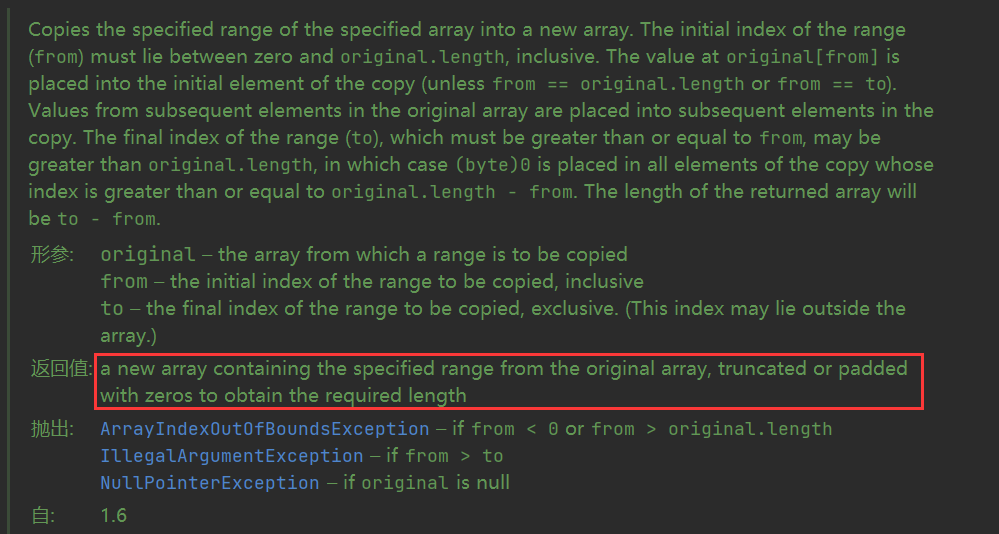
从上面可以看出,最终很多都会调用到Arrays.copyOfRange方法进行实际的数组拷贝操作,需要注意的是当需要拷贝的长度即to-from大于原始数组的剩余长度即origin.length-from时,进行补零操作!
1 2 3 4 5 6 7 8 9 10 11 12 13 public static byte [] copyOfRange(byte [] original, int from, int to) { int newLength = to - from; if (newLength < 0 ) throw new IllegalArgumentException (from + " > " + to); byte [] copy = new byte [newLength]; System.arraycopy(original, from, copy, 0 , Math.min(original.length - from, newLength)); return copy; } public static native void arraycopy (Object src, int srcPos, Object dest, int destPos, int length) ;
当然,subString方法还有重载方法,可以控制子字符串的起始位置和终止位置,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public String substring (int beginIndex, int endIndex) { int length = length(); checkBoundsBeginEnd(beginIndex, endIndex, length); int subLen = endIndex - beginIndex; if (beginIndex == 0 && endIndex == length) { return this ; } return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen) : StringUTF16.newString(value, beginIndex, subLen); } static void checkBoundsBeginEnd (int begin, int end, int length) { if (begin < 0 || begin > end || end > length) { throw new StringIndexOutOfBoundsException ( "begin " + begin + ", end " + end + ", length " + length); } }
十、String类的concat方法 将指定的字符串连接到此字符串的末尾。如果参数字符串的长度为0,则返回此String对象。否则,将返回一个String表示字符序列的对象,该字符序列是此String对象表示的字符序列和参数字符串表示的字符序列的串联。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public String concat (String str) { if (str.isEmpty()) { return this ; } if (coder() == str.coder()) { byte [] val = this .value; byte [] oval = str.value; int len = val.length + oval.length; byte [] buf = Arrays.copyOf(val, len); System.arraycopy(oval, 0 , buf, val.length, oval.length); return new String (buf, coder); } int len = length(); int olen = str.length(); byte [] buf = StringUTF16.newBytesFor(len + olen); getBytes(buf, 0 , UTF16); str.getBytes(buf, len, UTF16); return new String (buf, UTF16); } void getBytes (byte dst[], int dstBegin, byte coder) { if (coder() == coder) { System.arraycopy(value, 0 , dst, dstBegin << coder, value.length); } else { StringLatin1.inflate(value, 0 , dst, dstBegin, value.length); } }