Object类源码剖析
一、Object类的简介
Object类是类层次结构中的根类,每个类都使用它作为父类,所有的对象(包括数组)都实现了这个类中的方法。
1 | package test.lang; |
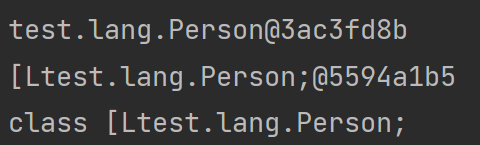
这里我们可以看出,数组也是一种类(如int数组类、String数组类、Person数组类),上面代码中的arr就是一个数组对象,数组对象具有length字段,同样继承自Object类,能访问toString等一系列方法,甚至还可以通过[]使用下标访问数组元素。下面是一段验证代码:
1 | // 数组也是一种类,可以称之为数组类 |
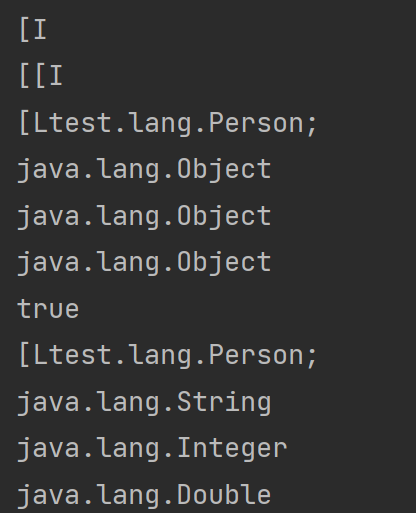
Object类非常有意思,其中包含与反射相关的getClass方法、经常使用的toString方法、与哈希表的键相关的hashCode和equals方法、拷贝复制相关的clone方法、线程同步相关的wait/notify/notifyAll方法以及跟本地方法映射相关的registerNatives方法。(finalize方法从JDK9已经废弃了,不再建议使用)

二、registerNatives方法解析
1 | private static native void registerNatives(); |
创建对象时,先调用静态代码块(即registerNatives()方法)。native关键字表示该方法不是由Java语言编写,而是通过C/C++来完成的,并被编译成.dll之后才由Java调用,方法的具体实现是在dll文件中。registerNatives()方法主要作用就是将C/C++中的方法映射到Java中的native方法,实现方法命名的解耦。
registerNatives本质上就是一个本地方法,但这又是一个有别于一般本地方法的本地方法,从方法名我们可以猜测该方法应该是用来注册本地方法的。细心的你可能还会发现,在Object类中,除了有registerNatives这个本地方法之外,还有hashCode()、clone()等本地方法,而在Class类中有forName0()这样的本地方法等等。也就是说,凡是包含registerNatives()本地方法的类,同时也包含了其他本地方法。所以,显然,==当包含registerNatives()方法的类被加载的时候,注册的方法就是该类所包含的除了registerNatives()方法以外的所有本地方法。==
那么为什么要注册本地方法呢?
一个Java程序要想调用一个本地方法,需要执行两个步骤:第一,通过System.loadLibrary()将包含本地方法实现的动态文件加载进内存;第二,当Java程序需要调用本地方法时,虚拟机在加载的动态文件中定位并链接该本地方法,从而得以执行本地方法。registerNatives()方法的作用就是取代第二步,让程序主动将本地方法链接到调用方,当Java程序需要调用本地方法时就可以直接调用,而不需要虚拟机再去定位并链接。这样做有一些好处:
- 通过registerNatives方法在类被加载的时候就主动将本地方法链接到调用方,比当方法被使用时再由虚拟机来定位和链接更方便有效。
- 如果本地方法在程序运行中更新了,可以通过调用registerNative方法进行更新。
- Java程序需要调用一个本地应用提供的方法时,因为虚拟机只会检索本地动态库,因而虚拟机是无法定位到本地方法实现的,这个时候就只能使用registerNatives()方法进行主动链接。
- 通过registerNatives()方法,在定义本地方法实现的时候,可以不遵守JNI命名规范。
那什么是JNI命名规范呢?举个例子,我们在Object中定义的本地方法registerNatives,那这个方法对应的本地方法名就叫Java_java_lang_Object_registerNatives,而在System类中定义的registerNatives方法对应的本地方法名叫Java_java_lang_System_registerNatives等等。也就是说,JNI命名规范要求本地方法名由“包名”+“方法名”构成,我们将Java中定义的方法名“func”和本地方法名“func_impl”链接了起来,这就是通过registerNatives方法的第四个好处。
三、getClass方法解析
1 |
|
返回此对象的运行时类。返回的Class对象是由所表示类的静态同步方法锁定的对象。实际结果类型为Class<?extensions X>其中X是对调用getClass的表达式的静态类型的擦除。例如,在这个代码片段中不需要强制转换:
1 | Number n = 0; |
四、hashCode方法解析
1 |
|
返回该对象的哈希值,支持此方法有利于哈希表的性能 比如由java.util.HashMap提供的哈希表哈希值的常规约定:在Java应用程序执行期间,在对同一对象多次调用hashCode方法时,必须一致地返回相同的整数。前提是对象进行比较时的euqals方法所用的信息没有被修改。从应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
如果根据equals(Object)方法,两个对象是相等的,那么对这两个对象中的每个对象调用hashCode方法都必须生成相同的整数结果。如果根据equals(java.lang.Object)方法,两个对象不相等,那么对这两个对象中的任一对象上调用hashCode方法不要求一定生成不同的整数结果。然而程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
实际上,由Object类定义的hashCode方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是Java编程语言不需要这种实现技巧)
五、equals方法解析
1 | public boolean equals(Object obj) { |
equals方法在非空对象引用上实现相等关系:
- 自反性:对于任何非空引用值x,x.equals(x)都应返回true。
- 对称性:对于任何非空引用值x和y,当且仅当y.equals(x)返回true时,x.equals(y)也应返回true。
- 传递性:对于任何非空引用值x、y和z,如果x.equals(y)返回true,并且y.equals(z)返回true,那么x.equals(z)应返回 true。
- 一致性:对于任何非空引用值x和y,多次调用x.equals(y)始终返回true或始终返回false,前提是对象上equals比较中所用的信息没有被修改。
对于任何非空引用值x,x.equals(null)都应返回false。Object类的equals方法实现判别可能性最大的相等关系,即对于任何非空引用值x和y,当且仅当x和y引用同一个对象时,此方法才返回true(x==y具有值true)。
1 | static class ObjectTest1 { |
注意:当此方法被重写时,通常有必要重写hashCode方法,以维护hashCode方法的常规约定,该约定声明相等对象必须具有相等的哈希码。
六、clone方法解析
1 |
|

按照惯例,此方法返回的对象应该独立于该对象(正被复制的对象)。要获得此独立性,在super.clone返回对象之前,有必要对该对象的一个或多个字段进行修改。这通常意味着要深复制在被复制对象的内部的所有可变对象,并使用对副本的引用替换对这些对象的引用。==如果一个类只包含原始字段或对不可变对象的引用,那么通常情况下,不需要修改由克隆返回的对象中的字段。==Object的clone方法默认是字段的逐一赋值,属于浅拷贝,引用类型的字段拷贝后还是指向原来的引用对象,因此必要时我们需要手动创建引用对象的副本,更新拷贝对象的引用字段,属于深拷贝。
Object类的clone方法执行特定的复制操作。首先,如果此对象的类没有实现接口Cloneable,则会抛出 CloneNotSupportedException。
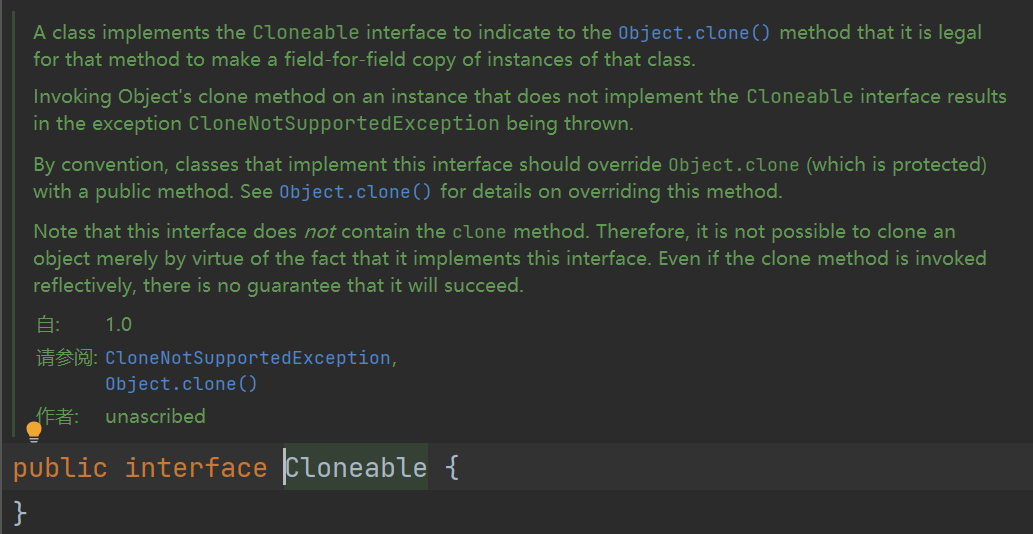
注意,所有的数组都被视为实现接口Cloneable,且数组类型T[]的clone方法返回的类型是T[],T可以是任何引用或基本类型
Object类本身不实现接口Cloneable,所以在Object类的对象上调用clone方法将会导致在运行时抛出异常。
clone()是Object的protected方法,它不是public,一个类不显式去重写clone(),其它类就不能直接去调用该类实例的clone()方法。Object.clone方法执行浅拷贝,如果对象中包含的字段引用了可变对象,使用Object.clone可能会导致灾难性的后果。
1 | public class ObjectCloneTest{ |

只有可变对象的引用才会出现上述问题,
不可变类(IMMUTABLE CLASS)的引用,如String、基本类型的包装类、BigInteger和BigDecimal等,每次对不可变对象的修改都将产生一个新的不可变对象,因此无论修改clone出的对象的可变对象,还是修改原对象中的可变对象,都会导致可变对象的引用值发生变化,而不是可变对象本身发生变化。
由于浅拷贝并不能保证clone出的对象和原对象完全独立,所以在很多时候会导致这样那样的问题,子类覆盖clone一般都是实现深拷贝。
1.首先调用父类super.clone方法(父类必须实现clone方法),这个方法最终会调用Object中的clone方法完成浅拷贝。
2.对类中的引用类型进行单独拷贝。
3.检查clone中是否有不完全拷贝,进行额外的复制。
1 |
|

七、toString方法解析
1 | public String toString() { |
返回该对象的字符串表示。通常,toString方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。Object类的toString方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、标记符“@”和此对象哈希码的无符号十六进制表示组成。
八、wait方法解析
1 | public final void wait(long timeoutMillis, int nanos) throws InterruptedException { |
在其他线程调用此对象的notify()方法或notifyAll()方法,或者超过指定的时间量前,导致当前线程等待。当前线程必须拥有此对象监视器。此方法导致当前线程(称之为T)将其自身放置在对象的等待集中,然后放弃此对象上的所有同步要求。出于线程调度目的,在发生以下四种情况之一前,线程T被禁用,且处于休眠状态:
- 其他某个线程调用此对象的notify方法,并且线程T碰巧选为被唤醒的线程。
- 其他某个线程调用此对象的notifyAll方法
- 其他某个线程中断线程T
- 已经到达指定的实际时间。但是,如果timeout为零,则不考虑实际时间,在获得通知前该线程将一直等待
然后,从对象的等待集中删除线程T,并重新进行线程调度,该线程以常规方式与其他线程竞争,一旦获得该对象监视器,该对象上的所有同步声明都将恢复到以前的状态,这就是调用wait方法时的情况。然后,线程T从wait方法的调用中返回,此时该对象和线程T的同步状态与调用wait方法时的情况完全相同
在没有被通知、中断或超时的情况下,线程还存在所谓的虚假唤醒 (spurious wakeup)场景,虽然这种情况在实践中很少发生,但是应用程序必须通过以下方式防止其发生,即对应该导致该线程被唤醒的条件进行测试,如果不满足该条件,则继续等待。换句话说,等待应总是发生在循环中,如下面的示例:
1 | synchronized (obj) { |
如果当前线程在等待之前或在等待时被任何线程中断,则会抛出InterruptedException。==这个异常直到在按上述形式恢复此对象的锁定状态时才会抛出。==
九、notify方法解析
1 |
|
唤醒在此对象监视器上等待的单个线程。如果多个线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个wait方法,在对象监视器上等待。
==直到当前线程放弃此对象上的锁定,才能继续执行被唤醒的线程。==被唤醒的线程将以常规方式与在该对象上主动synchronize的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的优势或劣势。此方法只应由作为此对象监视器的所有者的线程来调用。
通过以下三种方法之一,线程可以成为此对象监视器的所有者:
- 通过执行此对象的同步实例方法。
- 通过执行在此对象上进行同步synchronized语句的正文。
- 对于Class类型的对象,可以通过执行该类的同步静态方法。
一次只能有一个线程拥有对象的监视器。
:thinking: 使用wait/notify的顺序:
- 使用wait,notify和notifyAll时需要先对调用对象
加锁。 - 调用wait方法后,线程状态由
Runnable变为Waiting,并将当前线程放置到对象的等待队列。 - notify或者notifyAll方法调用后,等待线程依旧不会从wait立刻返回,需要调用noitfy的线程
释放锁之后,等待线程才有机会从 wait返回。 - notify方法将等待队列的一个等待线程从等待队列转移到
同步队列中,而notifyAll方法则是将等待队列中所有的线程全部移到同步队列,被移动的线程状态由Waiting变为Blocked。 - 从wait方法返回的前提是
获得了调用对象的锁。
从上述细节可以看到,等待/通知机制依托于同步机制,其目的就是确保等待线程从wait方法返回后能够感知到通知线程对变量做出的修改。
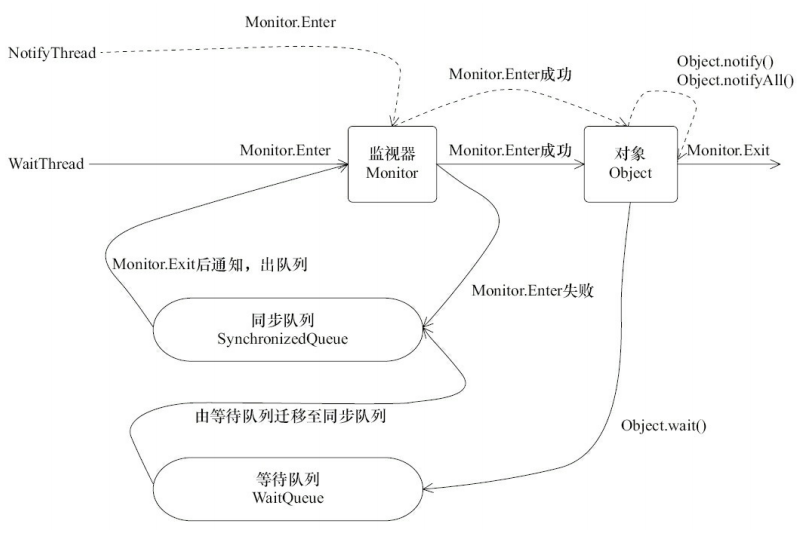
WaitThread获得了对象的锁,调用对象的wait方法,放弃了锁,进入了等待队列,然后NotifyThread拿到了对象的锁,然后调用对象的notify方法,将WatiThread移动到同步队列中,最后,NotifyThread执行完毕,释放锁,WaitThread再次获得锁并从wait方法返回继续执行。