eBPF程序初使用体验
一、环境搭建
1.虚拟机环境
稳定的运行 eBPF 程序推荐使用5.x内核版本,作为 eBPF 最重大的改进之一,一次编译到处执行(简称 CO-RE)解决了内核数据结构在不同版本差异导致的兼容性问题。不过,在使用 CO-RE 之前,内核需要开启 CONFIG_DEBUG_INFO_BTF=y 和 CONFIG_DEBUG_INFO=y 这两个编译选项。为了避免首次学习 eBPF 时就去重新编译内核,推荐使用已经默认开启这些编译选项的发行版,作为你的开发环境如 Ubuntu22.04-LTS。
2.工具集安装
- 将 eBPF 程序编译成字节码的 LLVM
- C 语言程序编译工具 make
- 最流行的 eBPF 工具集 BCC 和它依赖的内核头文件
- 与内核代码仓库实时同步的 libbpf
- 同样是内核代码提供的 eBPF 程序管理工具 bpftool
1 | For Ubuntu20.10+ |
二、开发自己的eBPF程序
1.开发流程
在开发 eBPF 程序之前,我们先来看一下 eBPF 的开发和执行过程,一般来说,这个过程分为以下 5 步:
- 第一步,使用 C 语言开发一个 eBPF 程序
- 第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码
- 第三步,通过 bpf 系统调用,把 BPF 字节码提交给内核
- 第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中
- 第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态
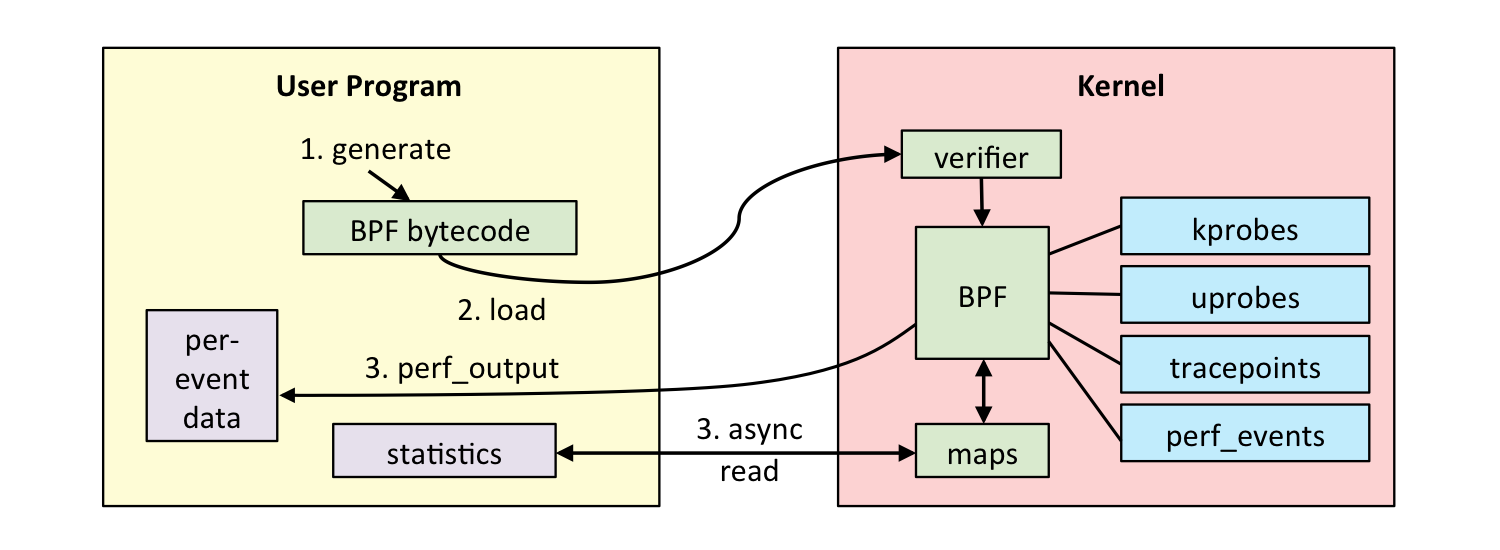
BCC 是一个 BPF 编译器集合,包含了用于构建 BPF 程序的编程框架和库,并提供了大量可以直接使用的工具。使用 BCC 的好处是,它把上述的 eBPF 执行过程通过内置框架抽象了起来,并提供了 Python、C++ 等编程语言接口。这样,你就可以直接通过 Python 语言去跟 eBPF 的各种事件和数据进行交互。
使用 BCC 开发 eBPF 程序,可以把前面讲到的五步简化为下面的三步。下面以跟踪 openat()(即打开文件)这个系统调用为例,带你来看看如何开发并运行第一个 eBPF 程序。
第一步:使用 C 开发一个 eBPF 程序
新建一个 hello.c 文件,并输入下面的内容:
1 | // This is a Hello World example of BPF. |
就像所有编程语言的“ Hello World ”示例一样,这段代码的含义就是打印一句 “Hello, World!” 字符串。其中, bpf_trace_printk() 是一个最常用的 BPF 辅助函数,它的作用是输出一段字符串。不过,由于 eBPF 运行在内核中,它的输出并不是通常的标准输出(stdout),而是内核调试文件 /sys/kernel/debug/tracing/trace_pipe ,你可以直接使用 cat 命令来查看这个文件的内容。
第二步:使用 Python 和 BCC 库开发一个用户态程序
接下来,创建一个 hello.py 文件,并输入下面的内容:
1 | #!/usr/bin/env python3 |
在运行的时候,BCC 会调用 LLVM,把 BPF 源代码编译为字节码,再加载到内核中运行
第三步:执行 eBPF 程序
用户态程序开发完成之后,最后一步就是执行它了。需要注意的是, eBPF 程序需要以 root 用户来运行,非 root 用户需要加上 sudo 来执行:
1 | sudo python3 hello.py |
对应的输出内容是:
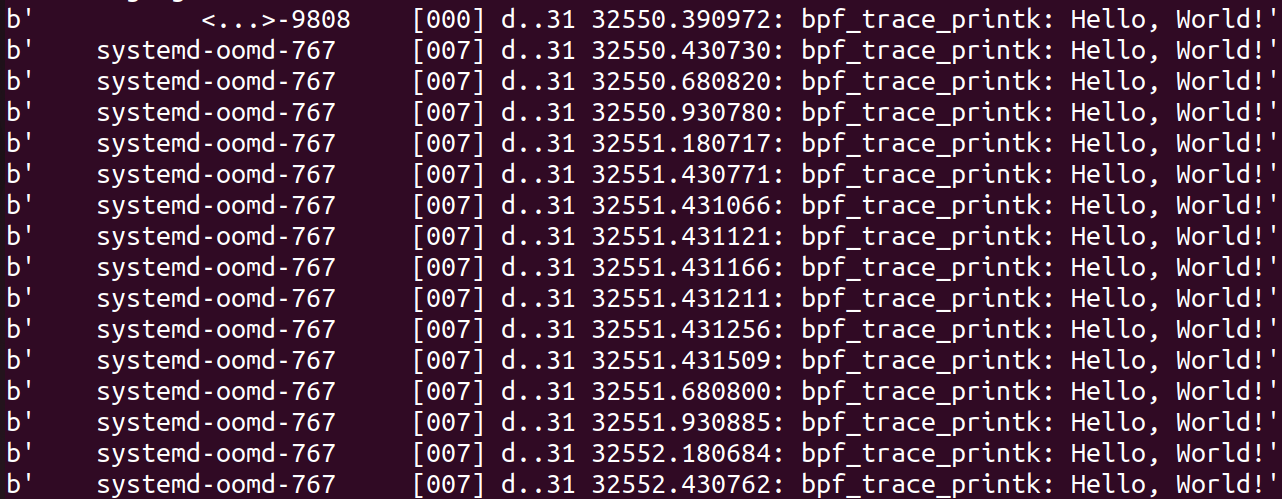
输出格式可由 /sys/kernel/debug/tracing/trace_options 来修改,上面的每一行表示的含义:进程名称-PID [CPU编号] 选项 时间戳 函数名 参数
实际上,我并不推荐通过内核调试文件系统输出日志的方式。一方面,它会带来很大的性能问题;另一方面,所有的 eBPF 程序都会把内容输出到同一个位置,很难根据 eBPF 程序去区分日志的来源。
2.改进流程
到了这里,恭喜你已经成功开发并运行了第一个 eBPF 程序!不过,短暂的兴奋之后,你会发现这个程序还有不少的缺点,比如:
- 既然跟踪的是打开文件的系统调用,除了调用这个接口进程的名字之外,被打开的文件名也应该在输出中;
bpf_trace_printk()的输出格式不够灵活,像是 CPU 编号、bpf_trace_printk 函数名等内容没必要输出;
BPF 程序可以利用 BPF 映射(map)进行数据存储,而用户程序也需要通过 BPF 映射,同运行在内核中的 BPF 程序进行交互。所以,为了解决上面提到的第一个问题,即获取被打开文件名的问题,我们就要引入 BPF 映射。
为了简化 BPF 映射的交互,BCC 定义了一系列的库函数和辅助宏定义。比如,你可以使用 BPF_PERF_OUTPUT 来定义一个 Perf 事件类型的 BPF 映射
1 |
|