Git原理实践
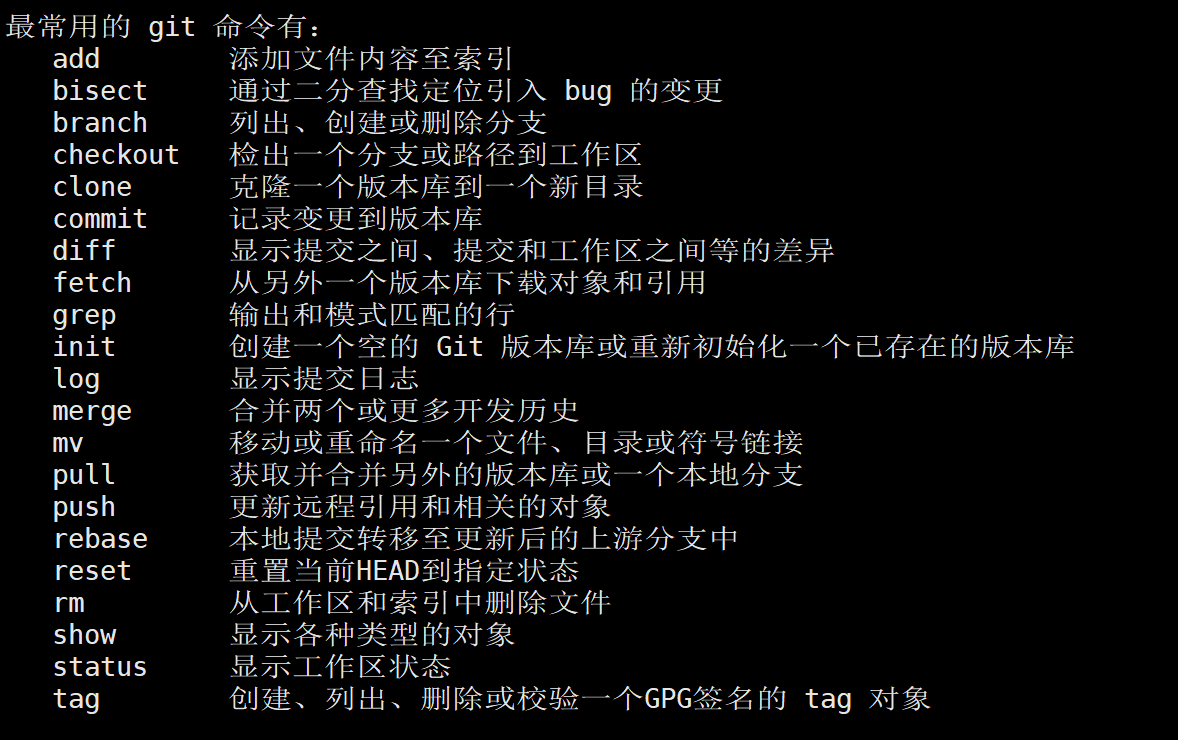
:runner:预备知识:Git的各种指令的使用,参考下图
开始我们的Git原理探索之路,感谢UP主麦兜搞IT的系列视频,这也是我参考的来源,下面将从一系列实战探索Git在背后帮我们做了哪些工作。
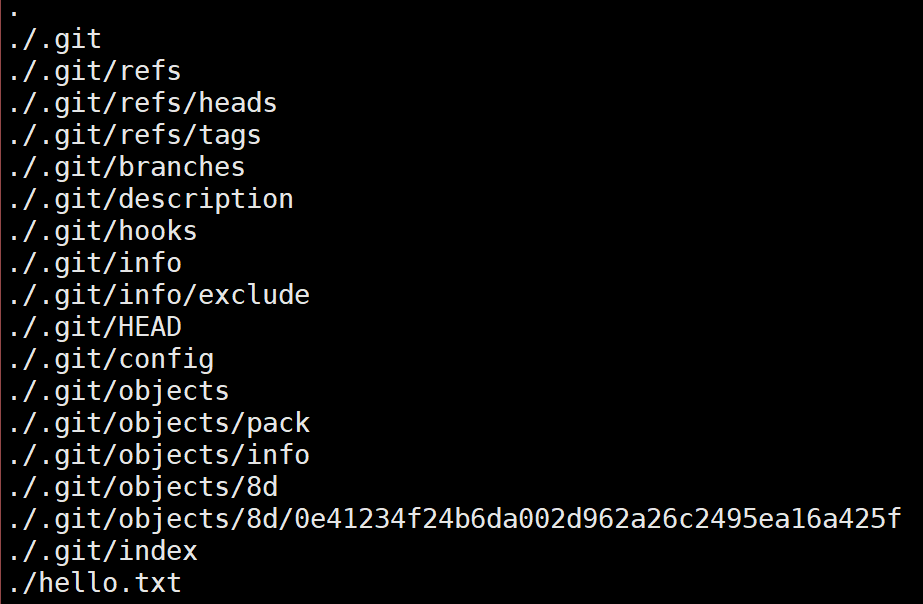
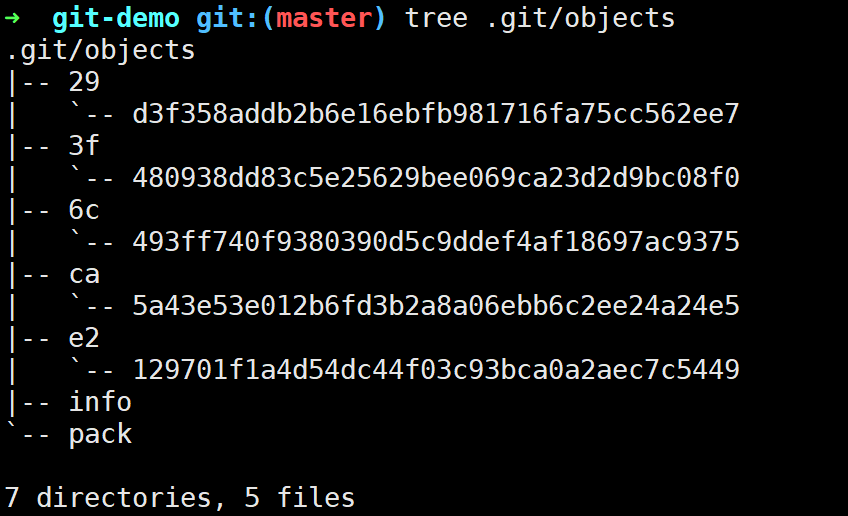
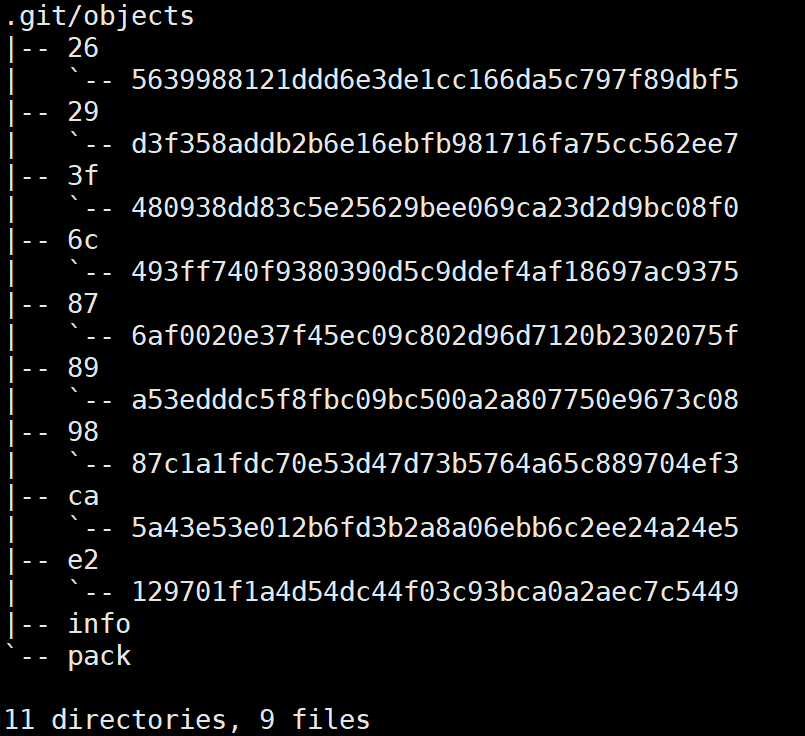
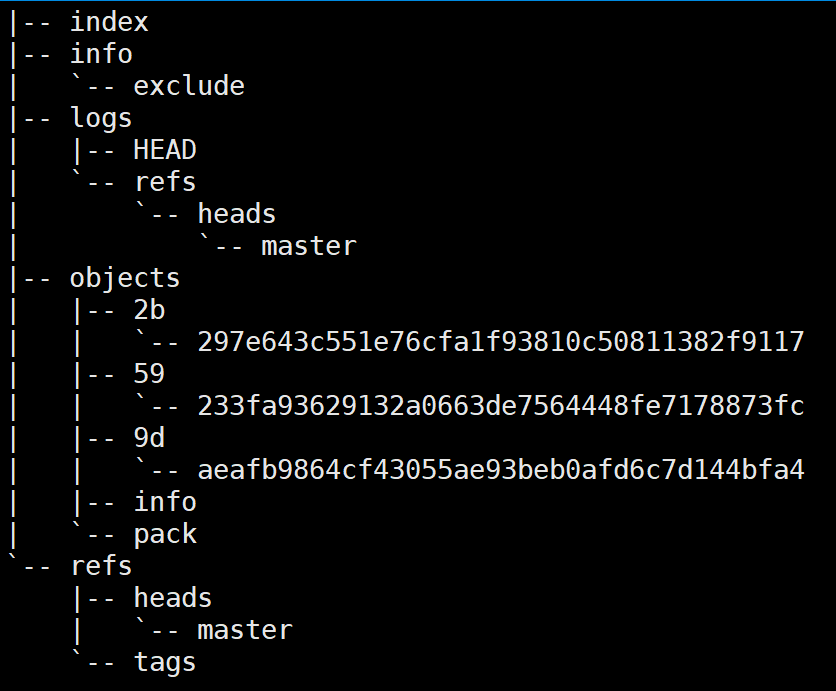
当运行git init时,当前目录下会生成一个名为.git/的Git初始仓库,其目录结构如下(为了方便观察已经rm -r .git/hooks/*.sample)
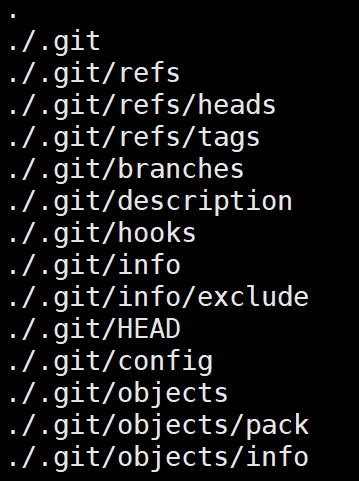
我们先简单地说一下Git仓库下每个目录及文件的作用或概念:
- HEAD:可以理解为一个指向当前工作分支的的指针,一般内容类似
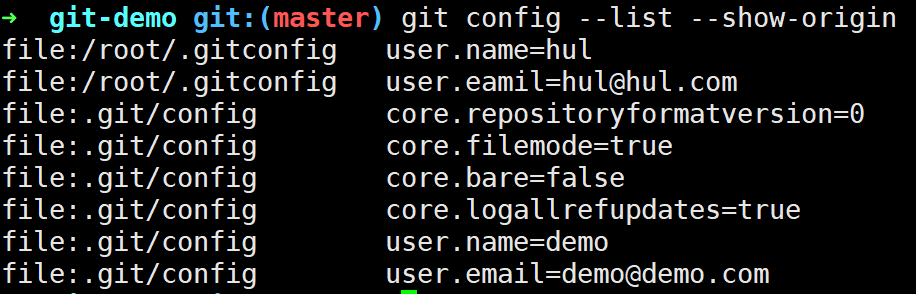
ref: refs/heads/master,当然发生HEAD分离时(使用git checkout SHA-1)其内容也可以是具体commit对象的SHA-1值。 - config:可以理解为当前Git仓库的本地配置文件,存储着
local级别的配置,Git中有三个级别的配置,其中system对应配置文件/etc/gitconfig,global对应配置文件~/.gitconfig,local级别对应配置文件当前工作目录/.git/config,默认优先级local>global>system。
index:初始化Git仓库时index文件尚不存在,当首次调用
git add xx时会创建index文件即暂存区,存放着下一次提交的快照信息(类似于root tree),可以使用Git底层命令git ls-file -s。info目录:包含一个全局性排除(global exclude)文件 , 用以放置那些不希望被记录在
.gitignore文件中的忽略模式。hooks目录:包含客户端或服务端的钩子脚本。
object目录:存储所有的数据内容,其中文件的命名根据SHA-1算法计算,类似于
b0/2h846gjsy99uuussxlnn2600su4n8d55ku8902,SHA-1值的前2位作为目录名,剩下38位作为文件名,每个文件存储的都是压缩后的数据,无法直接查看(乱码,需要使用Git底层命令git cat-file)。refs目录:存储指向数据(分支、远程仓库和标签等)的提交对象的指针。
当我们创建了一个hello.txt文件后并使用git add hello.txt加入暂存区后,一句话概括就是Git帮我们创建一个压缩对象,并在暂存区添加文件信息,具体如下:
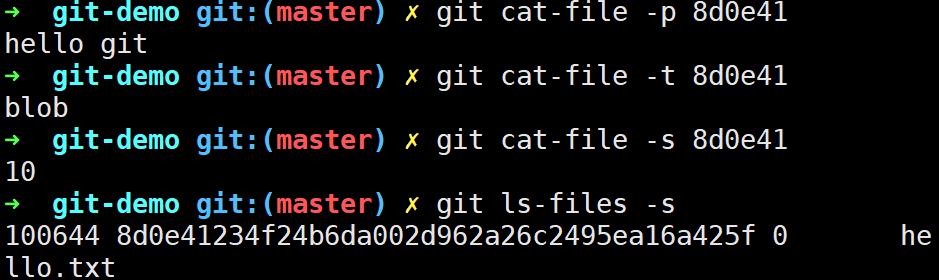
我们可以利用Git的底层命令查看具体文件的内容,此时会发现Git帮我们创建了一个blob对象,存储的正是hello.txt中的数据hello git\n,共计10字节。同时,暂存区也添加了对应一行信息,包括文件模型、SHA-1值、文件名,其中文件模式为 100644,表明这是一个普通文件。 其他选择包括:100755,表示一个可执行文件;120000,表示一个符号链接。 这里的文件模式参考了常见的 UNIX 文件模式,但远没那么灵活——上述三种模式即是 Git 文件(即数据对象)的所有合法模式。
从这里可以看出,暂存区保存着下一次提交时的仓库快照信息,当我们提交时会根据暂存区的信息创建相应的tree对象和commit对象,这也解释了为什么我们调用
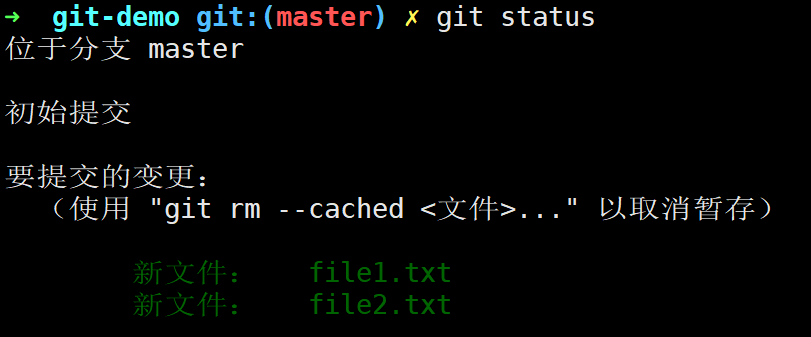
git status时Git能自动识别哪些文件是untracked,哪些文件是tracked,哪些文件是modified,那些文件是to be commited,这都是通过比较工作目录下的文件与暂存区内指向的文件(blob对象)数据的差异得到的。
我们这里稍微阐述一下objects目录下的文件名怎么计算得到的:以blob对象举例,上面的hello.txt文件的SHA-1值是通过”blob 10\0hello git\n”散列得到的,其中blob代表对象类型是blob类型;10代表文件的长度;\0代表头部的结束;后面的都是文件的具体内容。
==注意:实际存储文件内容需要进行压缩,查看文件内容时需要进行解压缩,这些通过zlib库实现。==
这也解释了
git cat-file底层命令的选项-t -s -p的意义,通过SHA-1值找到压缩文件并解压缩查看文件内容hello git\n并计算文件长度10,最后通过散列算法SHA-1与文件名8d0e41234f24b6da002d962a26c2495ea16a425f推出对象类型blob。
当我们进行git commit时Git会帮我们做哪些工作呢?
简而言之就是根据暂存区创建类似于目录结构的tree对象和commit对象,并更新refs目录下的分支引用如refs/heads/master和系统日志(logs目录下的内容)。
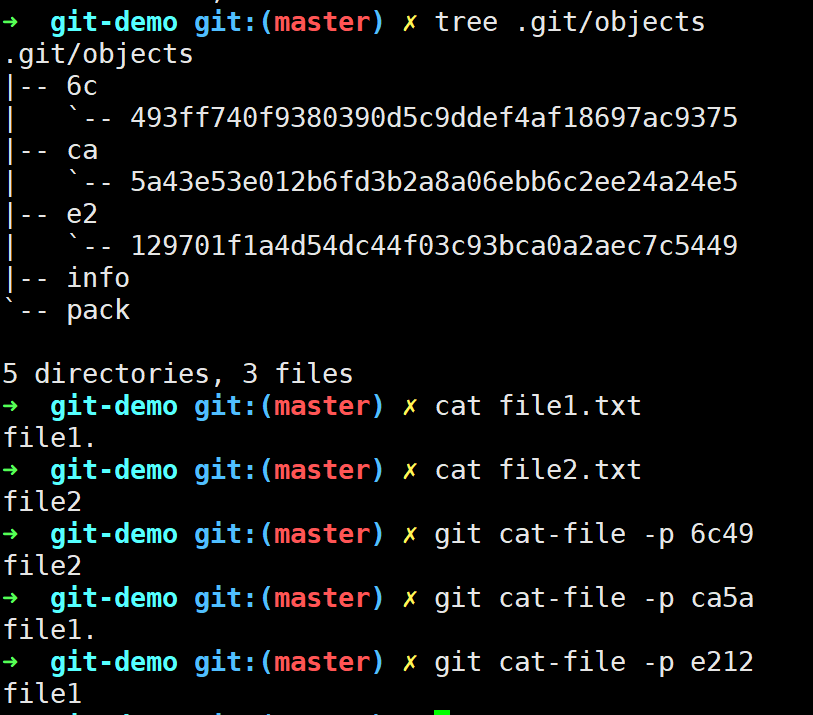
上图我们也能看到暂存区存放的是添加到暂存区的最新的blob对象的SHA-1值。
我们使用git status查看当前仓库状态:
我们使用git commit提交当前版本:

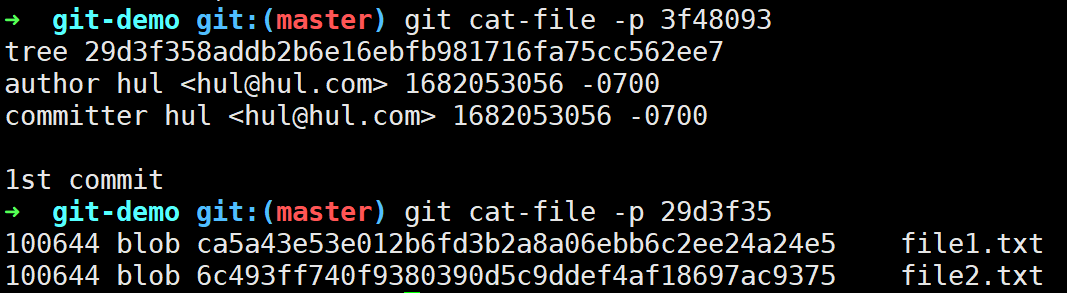
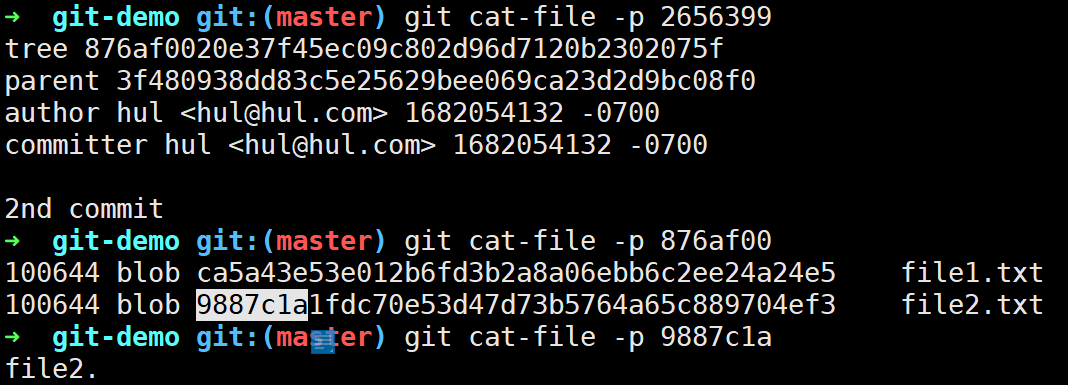
此时发现objects目录下多出来两个文件,其实就是Git创建的tree对象和commit对象。
查看这两个对象的信息,commit对象存储了其指向的tree对象和父提交对象(root commit不存在parent commit)以及作者、提交者信息和提交信息;tree对象存储了下一级tree对象(可能不存在)和blob对象的信息。
一个树对象包含了一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或者子树对象的SHA-1指针,以及相应的模式、类型、文件名信息
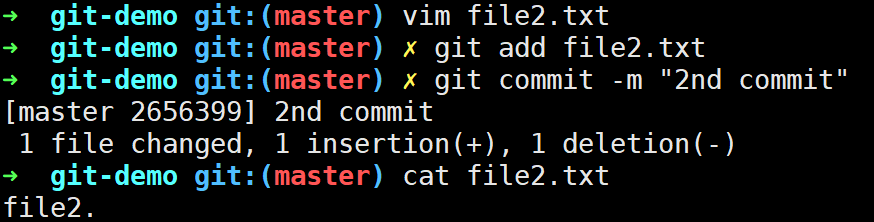
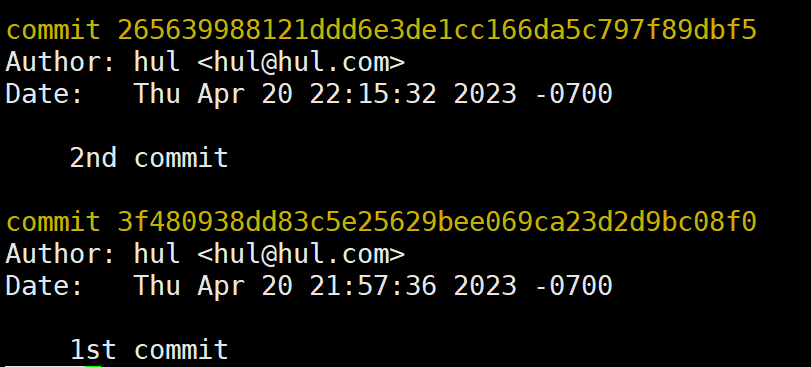
当我们修改file2.txt文件并再次提交时,Git会帮我们创建三个压缩文件:新的file2.txt的blob对象、新的tree对象、新的commit对象。
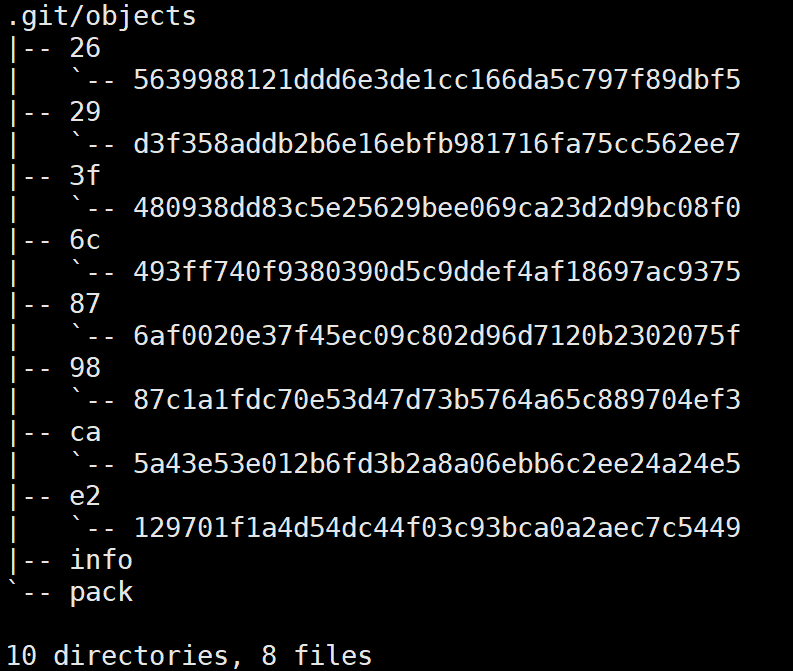
我们查看多出来的三个文件的详细信息,可以看出Git自动形成了一个commit对象的版本链(通过parent指针),此时refs目录下的引用文件存储着最新的commit对象的SHA-1值,因此可以沿着版本链回溯版本变更历史!

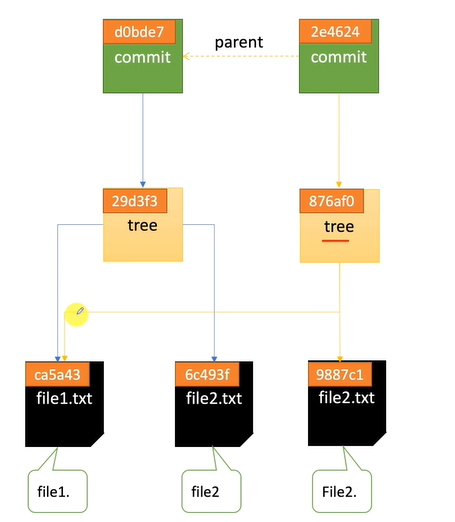
此时我们可以看一下Git对象的层级结构(忽略commit对象的SHA-1,因为借鉴的网图)
我们再来看一下稍微复杂一点的提交过程,即当前工作目录下有子目录的情况。
当我们添加一个folder1/file3.txt文件并git add folder1/时,Git会帮我们创建一个新的blob对象存储file3.txt的内容,并更新暂存区:

暂存区存储着代码的目录结构,当提交代码库时会生成所有必要的tree对象,下面调用git commit并查看多出了哪些文件:

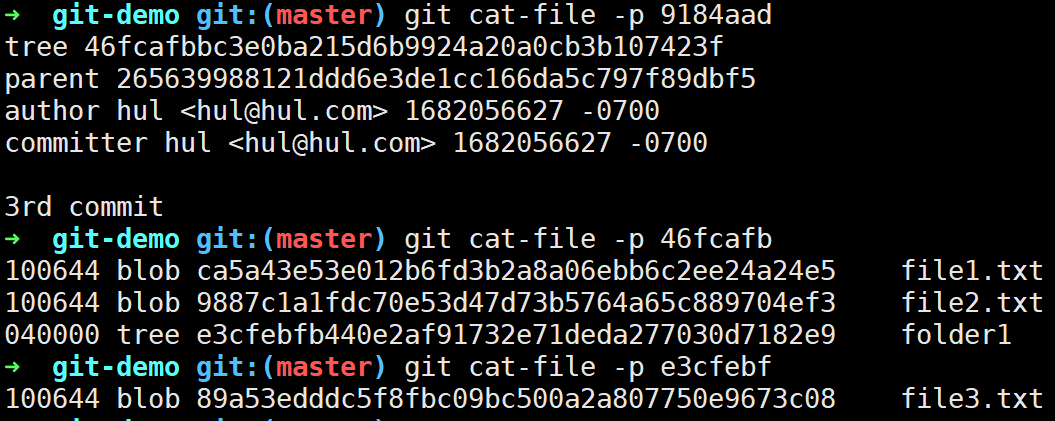
此时我们可以看一下Git对象的层级结构(忽略commit对象的SHA-1,因为借鉴的网图)
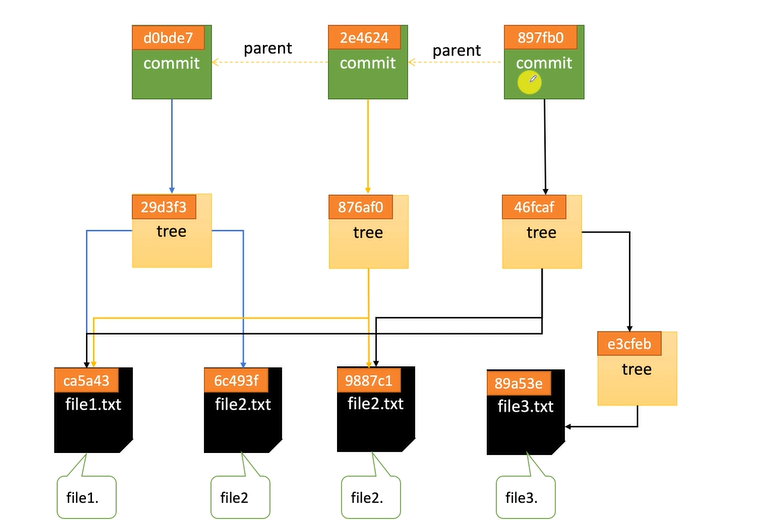
Git中文件状态是如何转变的呢,可以参考下图:
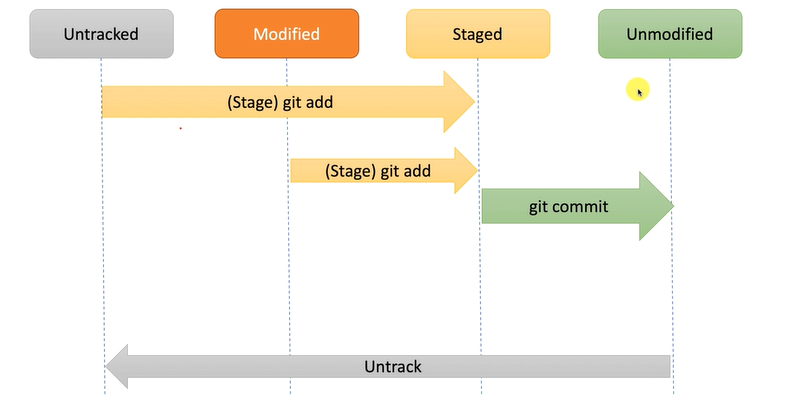
:fallen_leaf:这里我们引申一下Git的基本工作流程方便我们理解Git的reset和checkout命令
理解reset和checkout的最简方法,就是以Git的思维框架(将其作为内容管理器)来管理三棵不同的树。“树” 在我们这里的实际意思是 “文件的集合”,而不是指特定的数据结构。 (在某些情况下索引看起来并不像一棵树,不过我们现在的目的是用简单的方式思考它。)
Git作为一个系统,是以它的一般操作来管理并操纵这三棵树的:
| 树 | 用途 |
|---|---|
| HEAD | 上一次提交的快照,下一次提交的父结点 |
| Index | 预期的下一次提交的快照 |
| Working Directory | 沙盒 |
:arrow_heading_down:HEAD
HEAD是当前分支引用的指针,它总是指向该分支上的最后一次提交。 这表示HEAD将是下一次提交的父结点。 通常,理解HEAD的最简方式,就是将它看做该分支上的最后一次提交的快照。
其实,查看快照的样子很容易。 下例就显示了HEAD快照实际的目录列表,以及其中每个文件的 SHA-1 校验和:
1 | git cat-file -p HEAD |
:sagittarius:Index
索引是你的预期的下一次提交。 我们也会将这个概念引用为Git的“暂存区”,这就是当你运行git commit时Git看起来的样子。
Git将上一次检出到工作目录中的所有文件填充到索引区,它们看起来就像最初被检出时的样子。 之后你会将其中一些文件替换为新版本,接着通过git commit将它们转换为树来用作新的提交。
1 | git ls-files -s |
确切来说,索引在技术上并非树结构,它其实是以扁平的清单实现的。不过对我们而言,把它当做树就够了。
:file_folder:Working Directory
最后,你就有了自己的工作目录(通常也叫工作区)。 另外两棵树以一种高效但并不直观的方式,将它们的内容存储在.git文件夹中。 工作目录会将它们解包为实际的文件以便编辑。 你可以把工作目录当做沙盒。在你将修改提交到暂存区并记录到历史之前,可以随意更改。
1 | tree |
:factory:工作流程
经典的Git工作流程是通过操纵这三个区域来以更加连续的状态记录项目快照的。
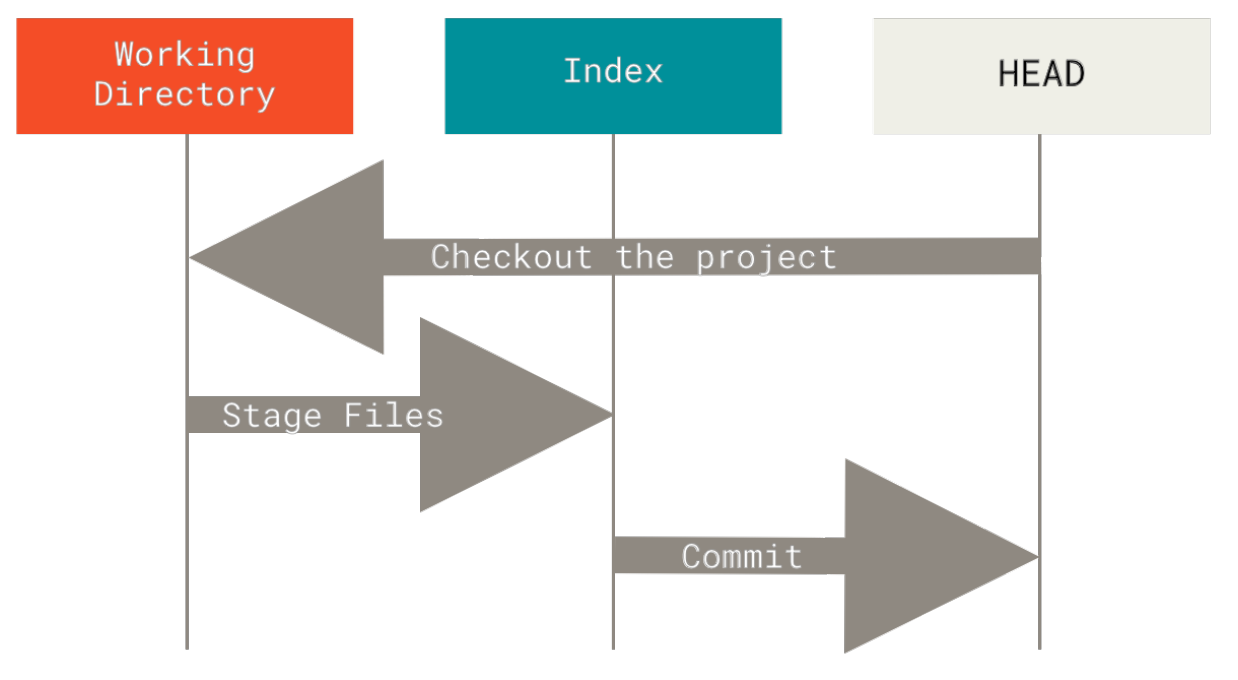
让我们来可视化这个过程:假设我们进入到一个新目录,其中有一个文件。 我们称其为该文件的v1版本,将它标记为蓝色。 现在运行git init,这会创建一个Git仓库,其中的HEAD引用指向未创建的 master 分支。
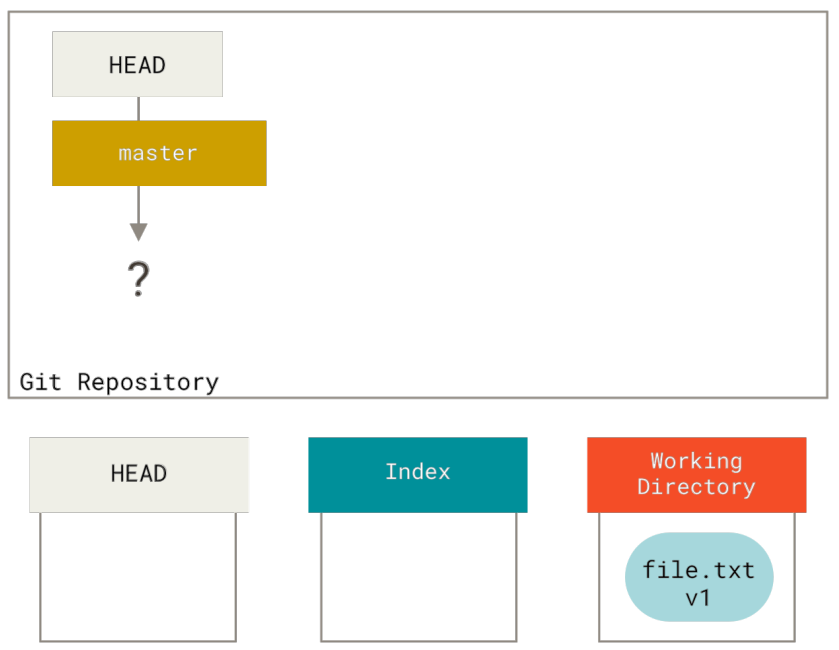
此时,只有工作目录有内容。现在我们想要提交这个文件,所以用git add来获取工作目录中的内容,并将其复制到索引中。
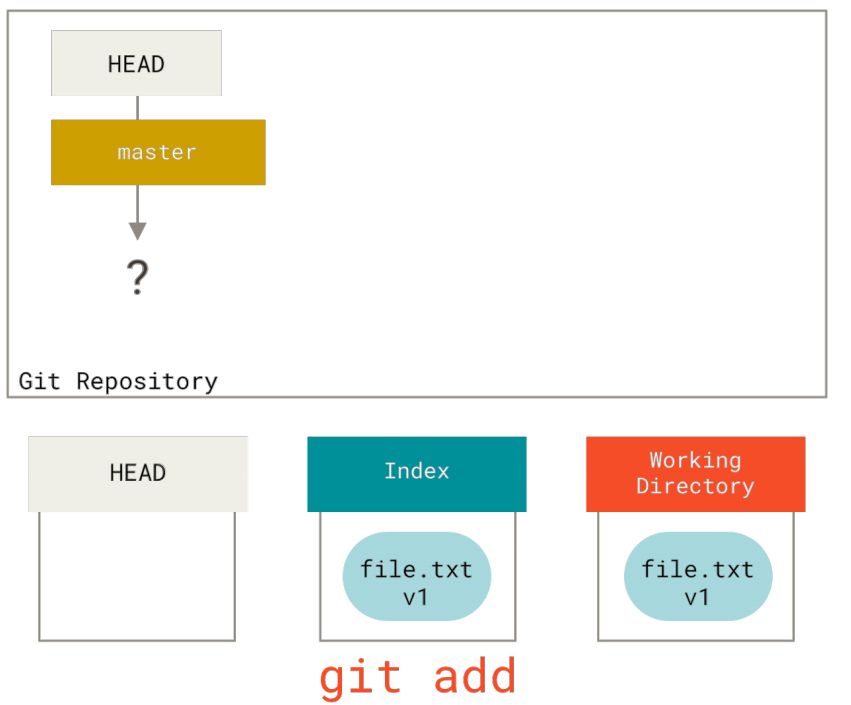
接着运行git commit,它会取得索引中的内容并将它保存为一个永久的快照, 然后创建一个指向该快照的提交对象,最后更新master来指向本次提交。
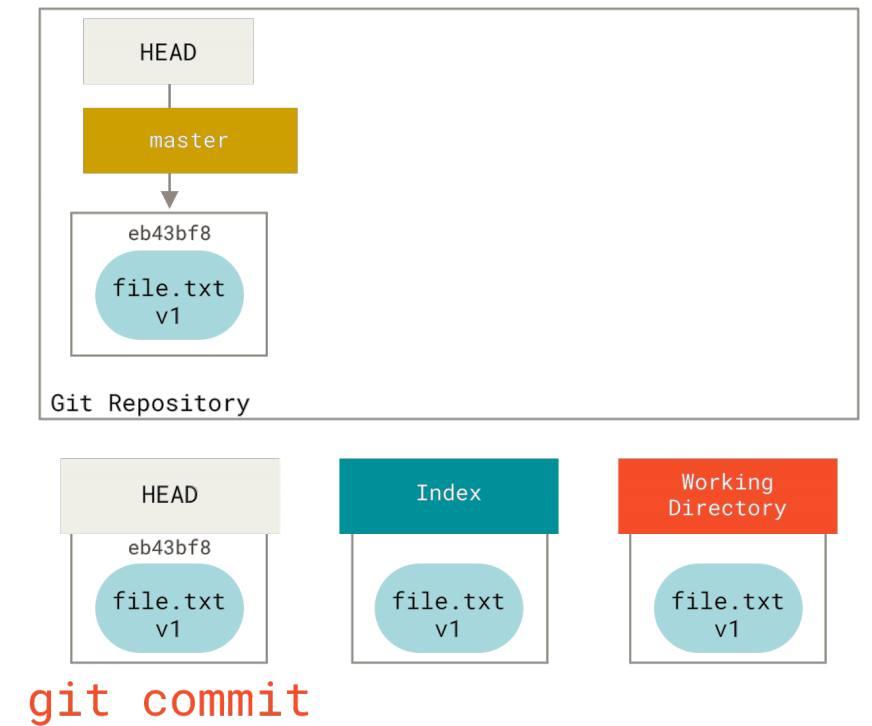
此时如果我们运行git status,会发现没有任何改动,因为现在三棵树完全相同。
现在我们想要对文件进行修改然后提交它。 我们将会经历同样的过程;首先在工作目录中修改文件。 我们称其为该文件的v2版本,并将它标记为红色。
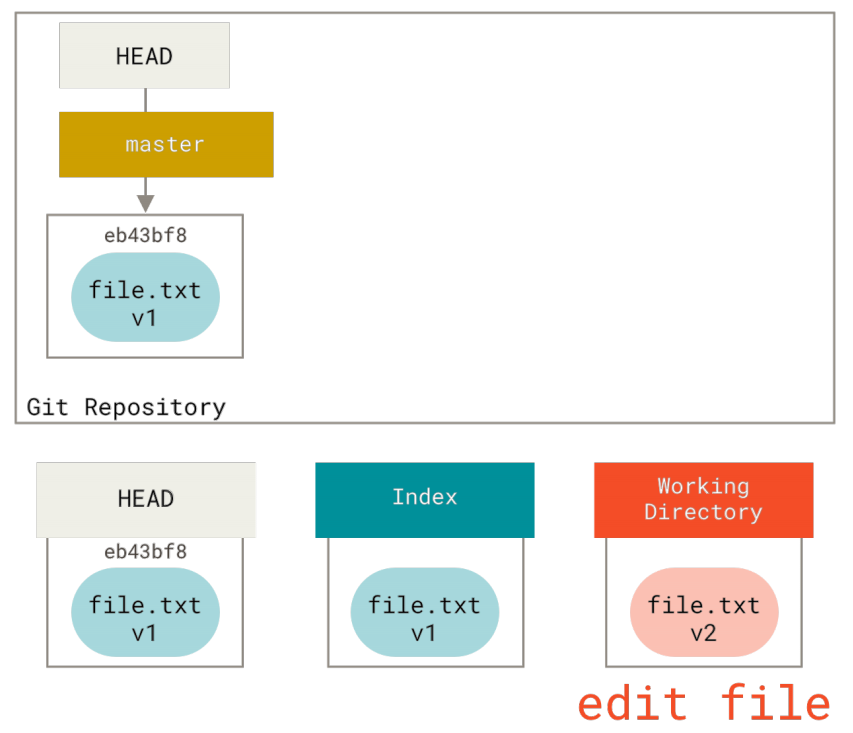
如果现在运行git status,我们会看到文件显示在 “Changes not staged for commit” 下面并被标记为红色,因为该条目在索引与工作目录之间存在不同。 接着我们运行git add来将它暂存到索引中。
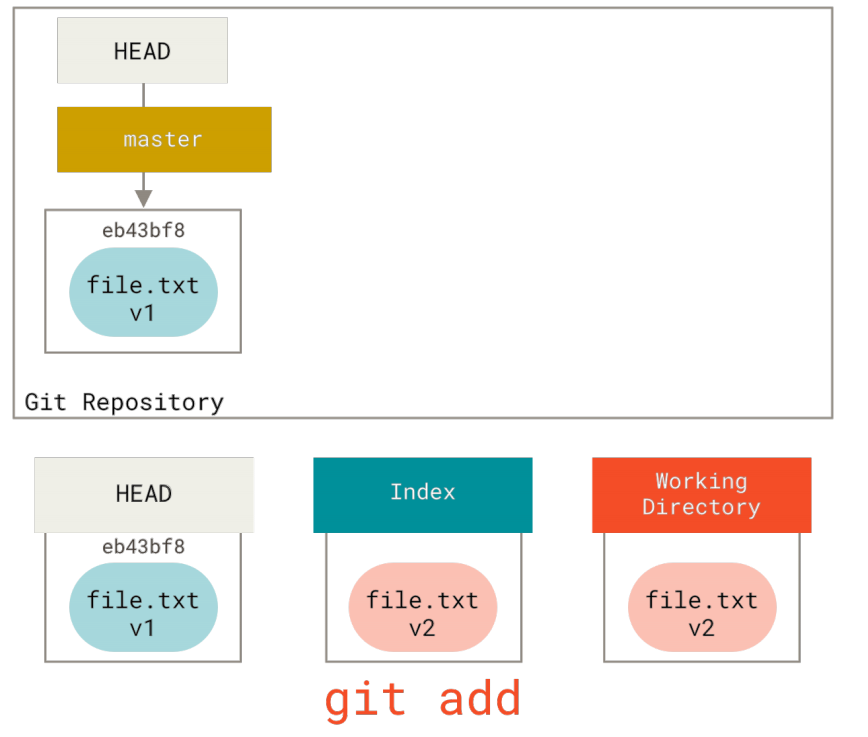
此时,由于索引和HEAD不同,若运行git status的话就会看到 “Changes to be committed” 下的该文件变为绿色 ——也就是说,现在预期的下一次提交与上一次提交不同。 最后,我们运行git commit来完成提交。
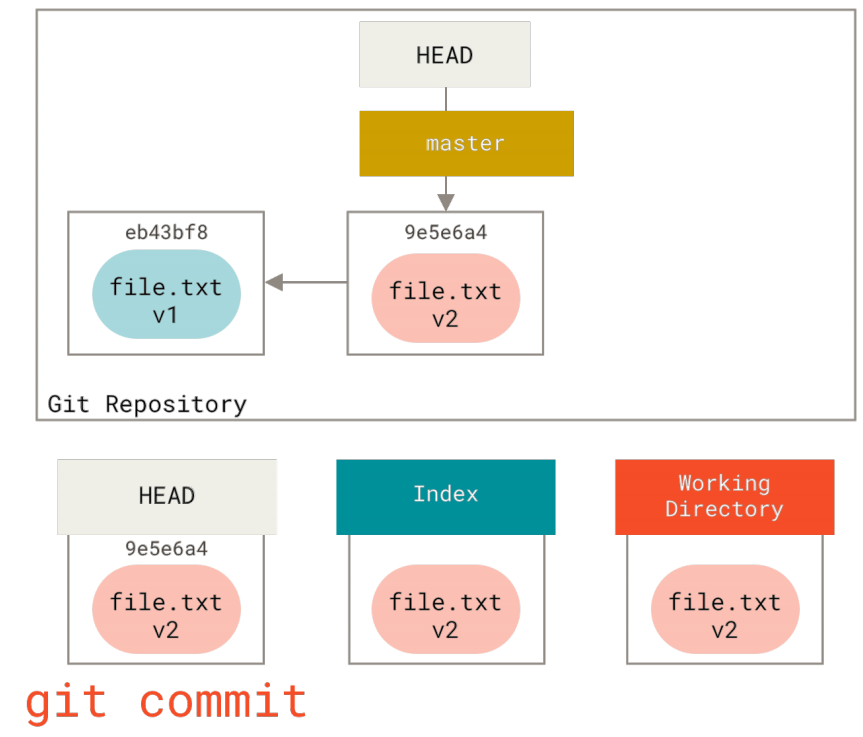
现在运行git status会没有输出,因为三棵树又变得相同了。
切换分支或克隆的过程也类似。 ==当检出一个分支时,它会修改HEAD指向新的分支引用,将索引填充为该次提交的快照, 然后将索引的内容复制到工作目录中。==
:railway_car:重置的作用
在以下情景中观察reset命令会更有意义。
为了演示这些例子,假设我们再次修改了file.txt文件并第三次提交它。 现在的历史看起来是这样的:
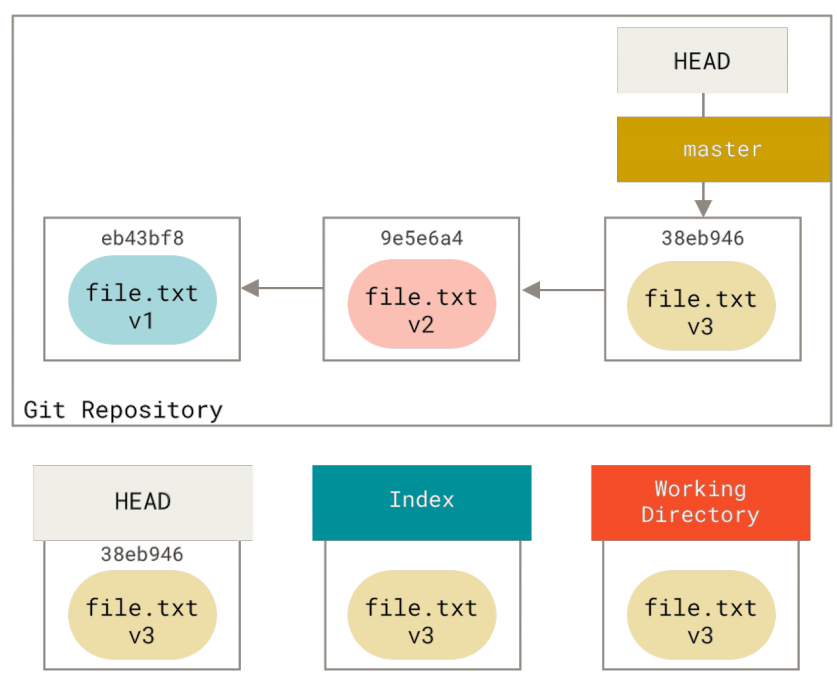
让我们跟着reset看看它都做了什么。 它以一种简单可预见的方式直接操纵这三棵树。 它做了三个基本操作。
- ==第1步:移动 HEAD==
reset做的第一件事是移动HEAD的指向。 这与改变HEAD自身不同(checkout所做的);reset移动HEAD指向的分支。 这意味着如果HEAD设置为master分支(例如,你正在master分支上), 运行git reset 9e5e6a4将会使master指向9e5e6a4。
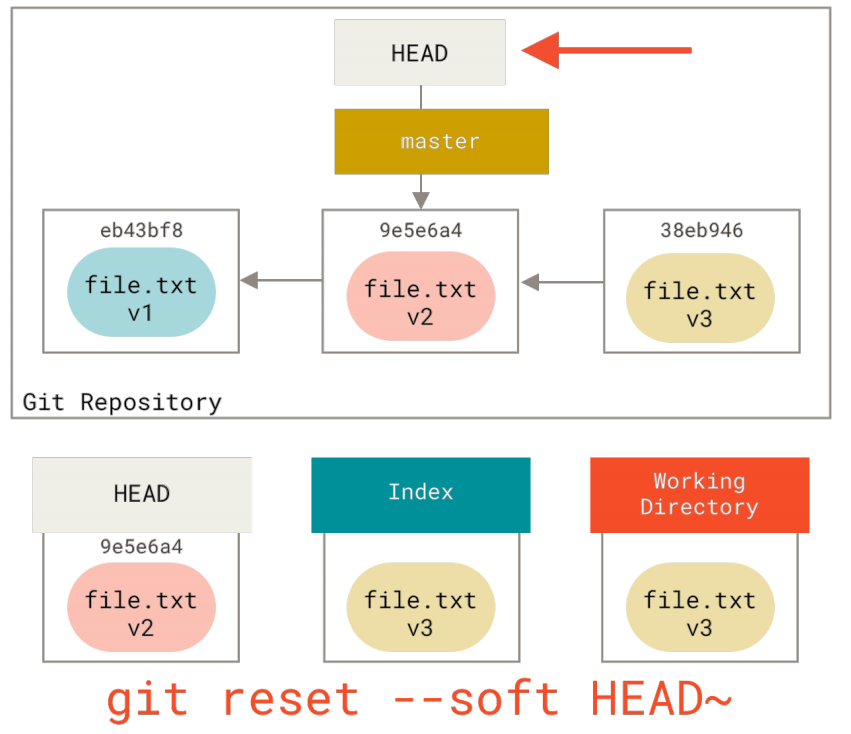
无论你调用了何种形式的带有一个提交的reset,它首先都会尝试这样做。 使用reset --soft,它将仅仅停在那儿。
现在看一眼上图,理解一下发生的事情:它本质上是撤销了上一次git commit命令。 当你在运行git commit时,Git会创建一个新的提交,并移动HEAD所指向的分支来使其指向该提交。 当你将它reset回HEAD~(HEAD的父结点)时,其实就是把该分支移动回原来的位置,而不会改变索引和工作目录。 现在你可以更新索引并再次运行git commit来完成git commit --amend所要做的事情了`。
- ==第2步:更新索引(–mixed)==
注意,如果你现在运行git status的话,就会看到新的HEAD和以绿色标出的它和索引之间的区别。接下来,reset会用HEAD指向的当前快照的内容来更新索引。
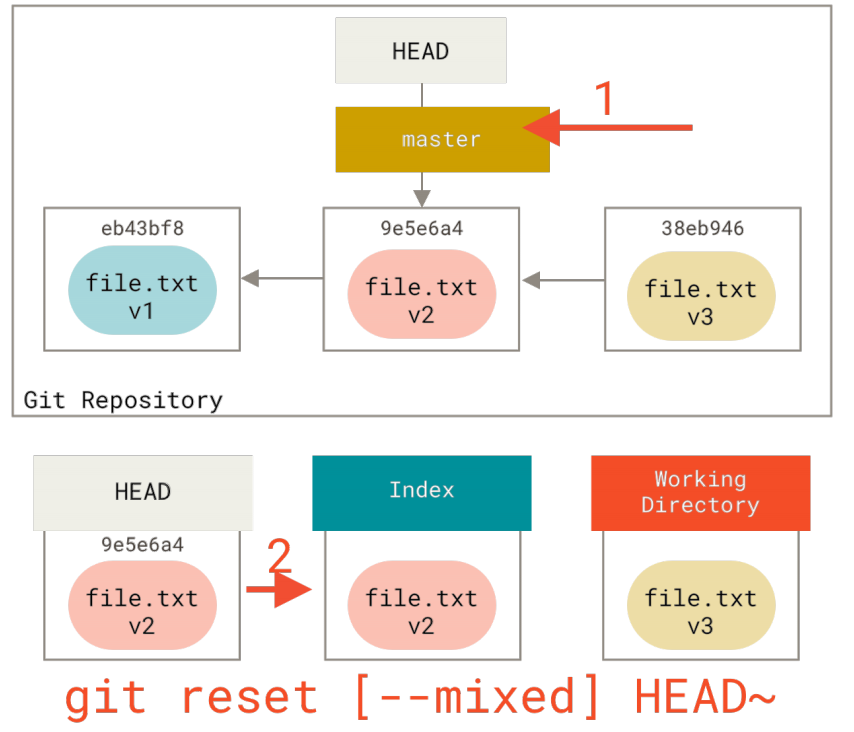
如果指定--mixed选项,reset将会在这时停止。 这也是默认行为,所以如果没有指定任何选项(在本例中只是git reset HEAD~),这就是命令将会停止的地方。
现在再看一眼上图,理解一下发生的事情:它依然会撤销一上次提交,但还会取消暂存所有的东西。 于是,我们回滚到了所有git add和git commit的命令执行之前。
- ==第3步:更新工作目录(–hard)==
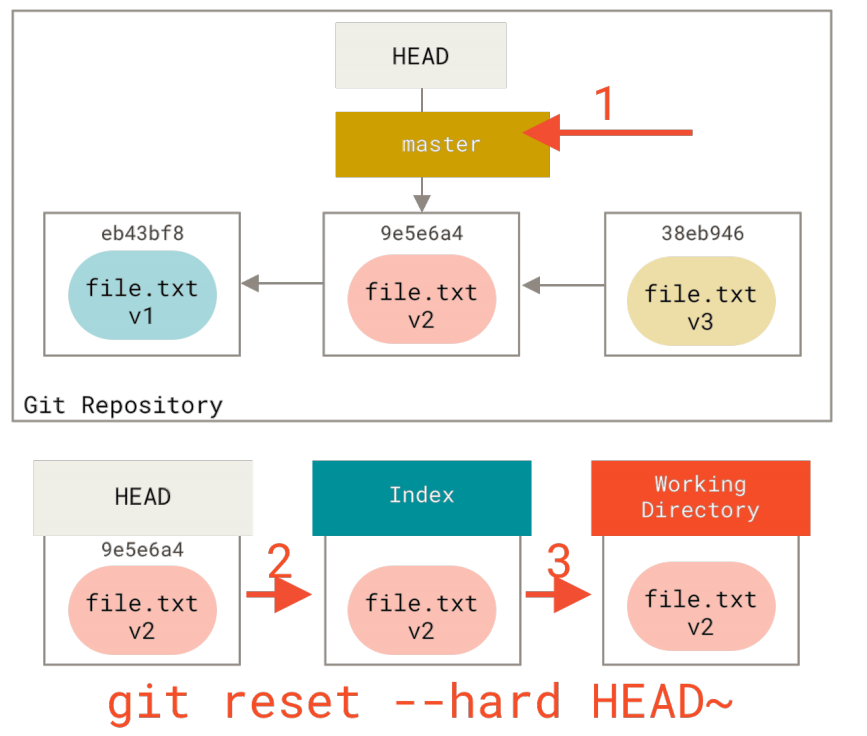
现在让我们回想一下刚才发生的事情。 你撤销了最后的提交、git add和git commit 命令以及工作目录中的所有工作。
必须注意,
--hard标记是reset命令唯一的危险用法,它也是Git会真正地销毁数据的仅有的几个操作之一。其他任何形式的reset调用都可以轻松撤消,但是--hard选项不能,因为它强制覆盖了工作目录中的文件。在这种特殊情况下,我们的Git数据库中的一个提交内还留有该文件的v3版本, 我们可以通过reflog来找回它。但是若该文件还未提交,Git仍会覆盖它从而导致无法恢复。
:hammer:回顾
reset命令会以特定的顺序重写这三棵树,在你指定以下选项时停止:
- 移动HEAD分支的指向 (若指定了
--soft,则到此停止) - 使索引看起来像HEAD (若未指定
--hard,则到此停止) - 使工作目录看起来像索引
:paintbrush:通过路径来重置
前面讲述了reset基本形式的行为,不过你还可以给它提供一个作用路径。若指定了一个路径,reset 将会跳过第1步,并且将它的作用范围限定为指定的文件或文件集合。 这样做自然有它的道理,因为HEAD只是一个指针,你无法让它同时指向两个提交中各自的一部分。 不过索引和工作目录可以部分更新,所以重置会继续进行第2、3步。
现在,假如我们运行git reset file.txt(这其实是git reset --mixed HEAD file.txt 的简写形式,因为你既没有指定一个提交的SHA-1或分支,也没有指定--soft或--hard),它会:
- 移动HEAD分支的指向 (已跳过)
- 让索引看起来像HEAD(到此处停止)
所以它本质上只是将file.txt从HEAD复制到索引中。
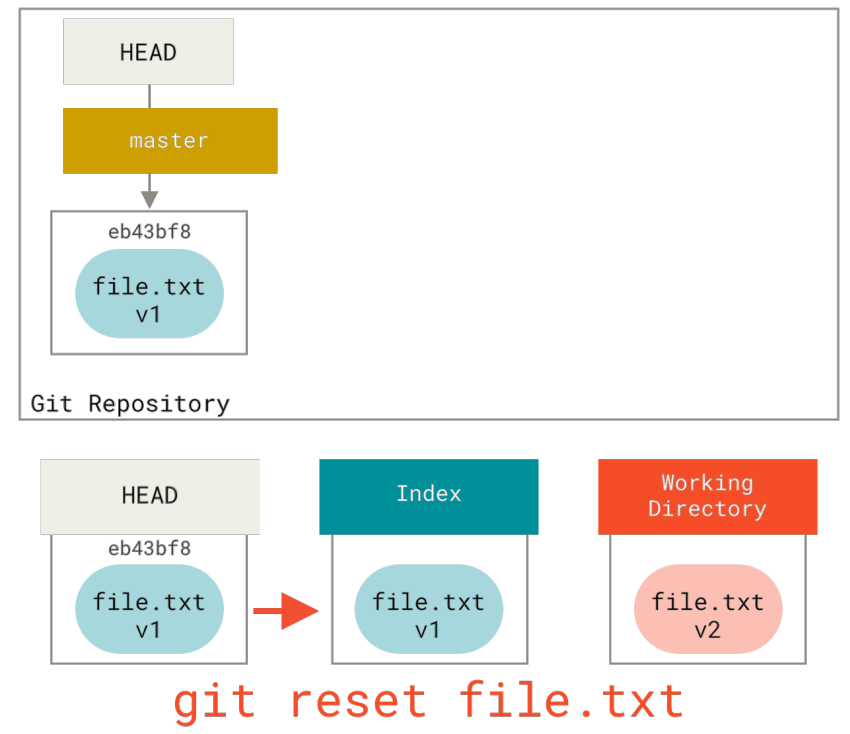
它还有==取消暂存文件==的实际效果。 如果我们查看该命令的示意图,然后再想想git add所做的事,就会发现它们正好相反。
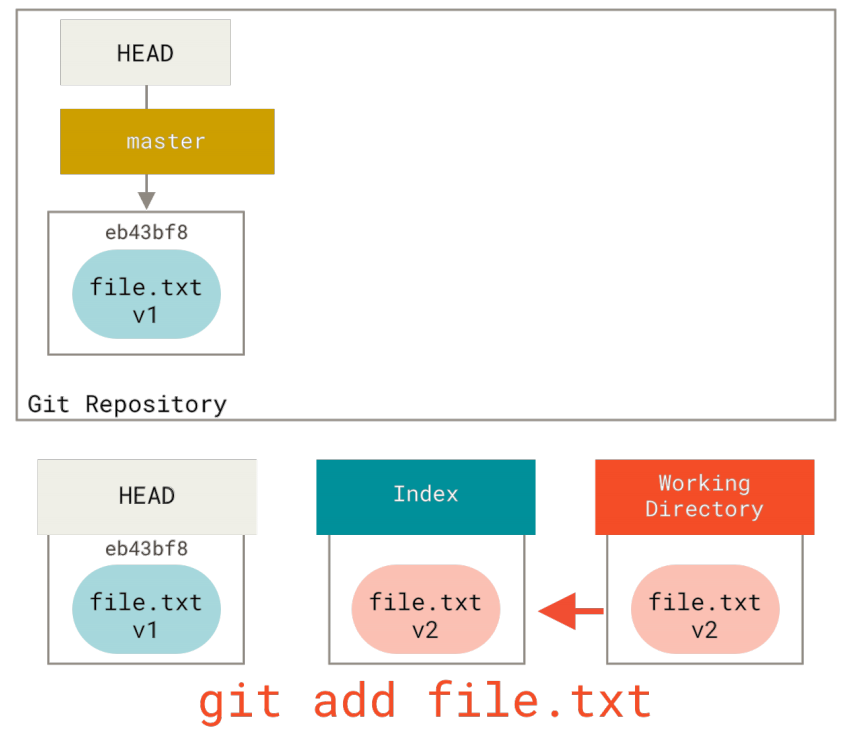
这就是为什么git status命令的输出会建议运行此命令来取消暂存一个文件。
我们可以不让Git从HEAD拉取数据,而是通过具体指定一个提交来拉取该文件的对应版本。 我们只需运行类似于git reset eb43bf file.txt的命令即可。
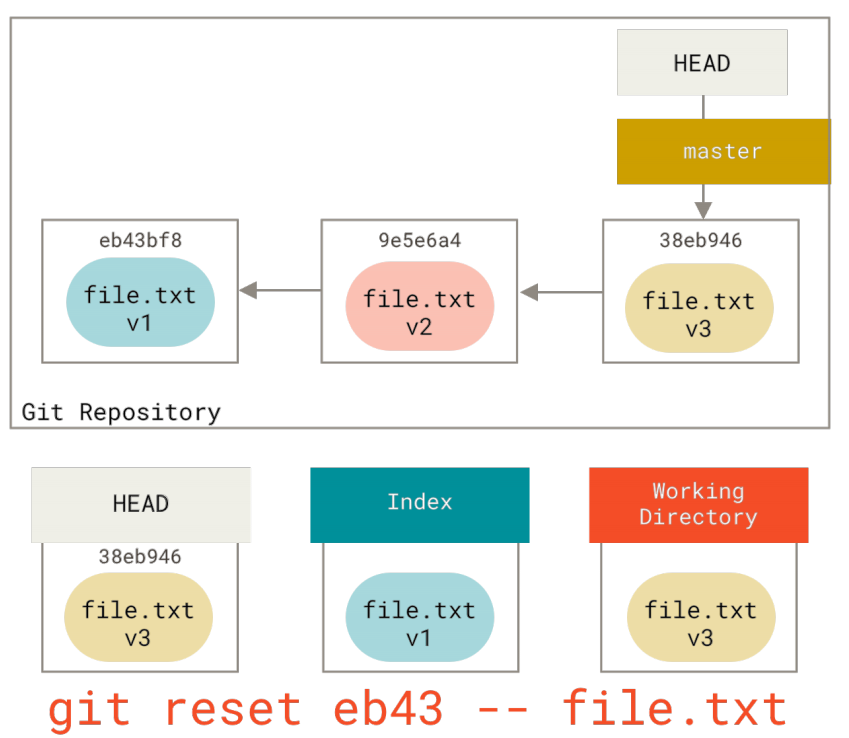
:sagittarius:检出的作用
最后,你大概还想知道checkout和reset之间的区别。 和reset一样,checkout也操纵三棵树,不过它有一点不同,这取决于你是否传给该命令一个文件路径。
- ==不带路径==
运行git checkout [branch]与运行git reset --hard [branch]非常相似,它会更新所有三棵树使其看起来像[branch],不过有两点重要的区别。
首先不同于reset --hard,checkout对工作目录是安全的,它会通过检查来确保不会将已更改的文件弄丢。 其实它还更聪明一些。它会在工作目录中先试着简单合并一下,这样所有还未修改过的文件都会被更新。而reset --hard则会不做检查就全面地替换所有东西。
第二个重要的区别是checkout如何更新HEAD。 reset会移动HEAD分支的指向,而 checkout只会移动HEAD自身来指向另一个分支。
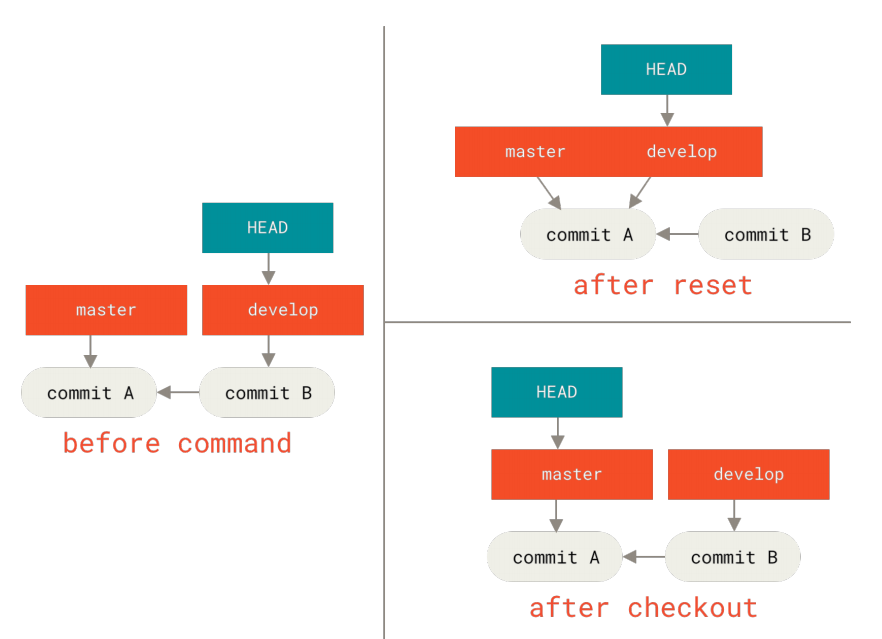
例如,假设我们有master和develop分支,它们分别指向不同的提交;我们现在在develop上(所以HEAD指向它)。 如果我们运行git reset master,那么develop自身现在会和master指向同一个提交。 而如果我们运行git checkout master的话,develop不会移动,HEAD自身会移动。 现在HEAD将会指向master。
所以,虽然在这两种情况下我们都移动HEAD使其指向了提交A,但做法是非常不同的。 reset会移动HEAD分支的指向,而checkout则移动HEAD自身。
- ==带路径==
运行checkout的另一种方式就是指定一个文件路径,这会像reset一样不会移动 HEAD。 它就像git reset [branch] file那样用该次提交中的那个文件来更新索引,但是它也会覆盖工作目录中对应的文件。它就像是git reset --hard [branch] file(如果 reset 允许你这样运行的话), 这样对工作目录并不安全,它也不会移动 HEAD。
它还有==取消工作目录下的修改==的实际效果。
这就是为什么git status命令的输出会建议运行此命令来丢弃一个修改。
下面我们接着说Git的分支管理,分支管理可谓是Git的杀手级特性,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢? Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。
当我们在dev分支修改文件并git commit后,dev分支超前master分支一次提交:
由于Git的分支实质上仅是包含所指对象校验和(长度为40的SHA-1值字符串)的文件,所以它的创建和销毁都异常高效。 创建一个新分支就相当于往一个文件中写入41个字节(40个字符和1个换行符),如此的简单能不快吗?
这与过去大多数版本控制系统形成了鲜明的对比,它们在创建分支时,将所有的项目文件都复制一遍,并保存到一个特定的目录。 完成这样繁琐的过程通常需要好几秒钟,有时甚至需要好几分钟。所需时间的长短,完全取决于项目的规模。 而在Git 中,任何规模的项目都能在瞬间创建新分支。 同时,由于每次提交都会记录父对象,所以寻找恰当的合并基础(译注:即共同祖先)也是同样的简单和高效。 这些高效的特性使得Git鼓励开发人员频繁地创建和使用分支。
我们紧接着看一下HEAD分离的概念与作用,当我们不小心删除了一个未合并的分支(使用-D),实际删除的仅仅是一个分支引用文件,其指向的commit对象等都丝毫未变,只是此时我们无法通过简单的分支引用到该commit,此时我们称这个commit是不可达的commit,但是通过reflog + HEAD分离我们能够再次找回该分支:
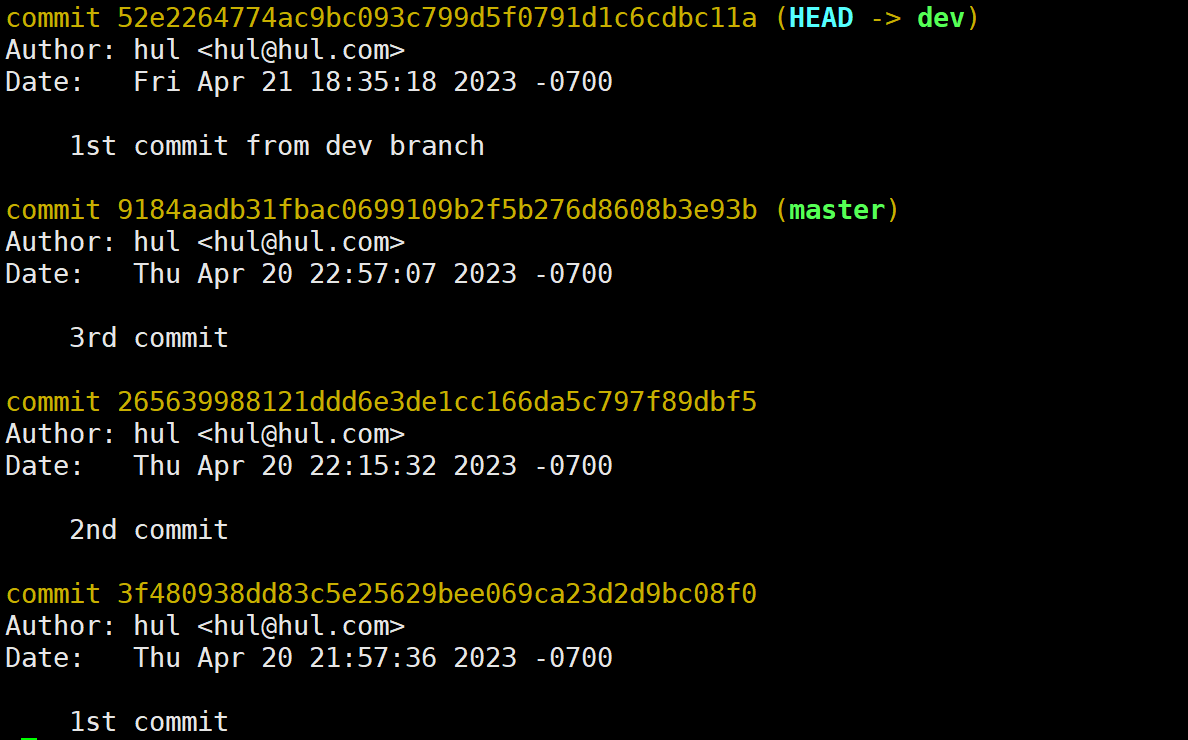
当我们不小心删除了dev分支随后又反悔了,其实还存在反悔药,下面演示:

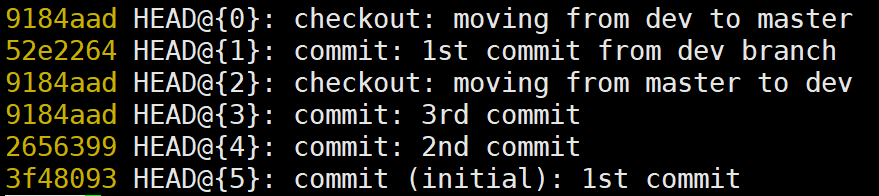
此时我们可以通过git checkout 52e2264回溯到dev分支的提交位置:
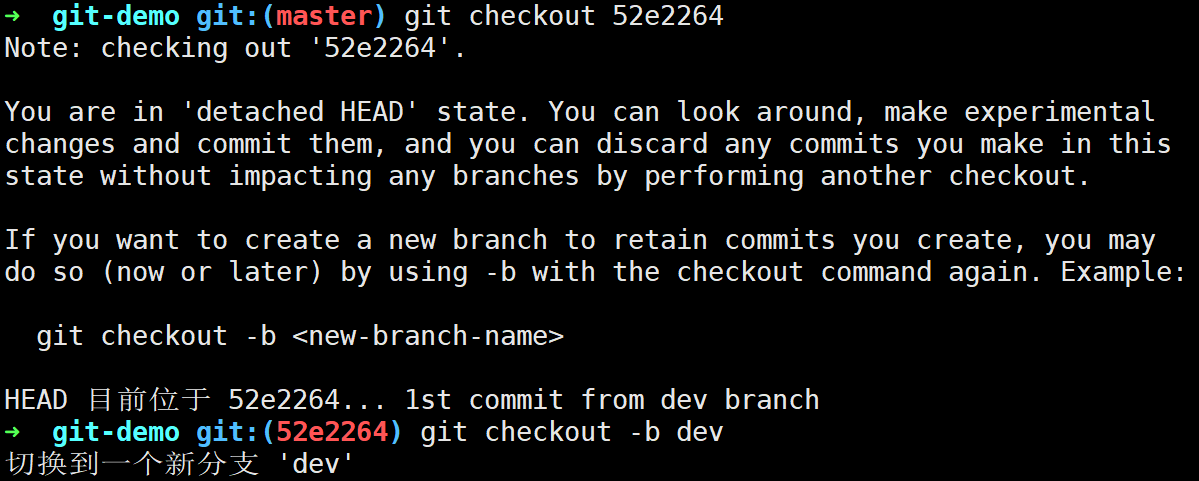
此时查看一下提交日志发现以及恢复到原来未删除dev分支的样子了:
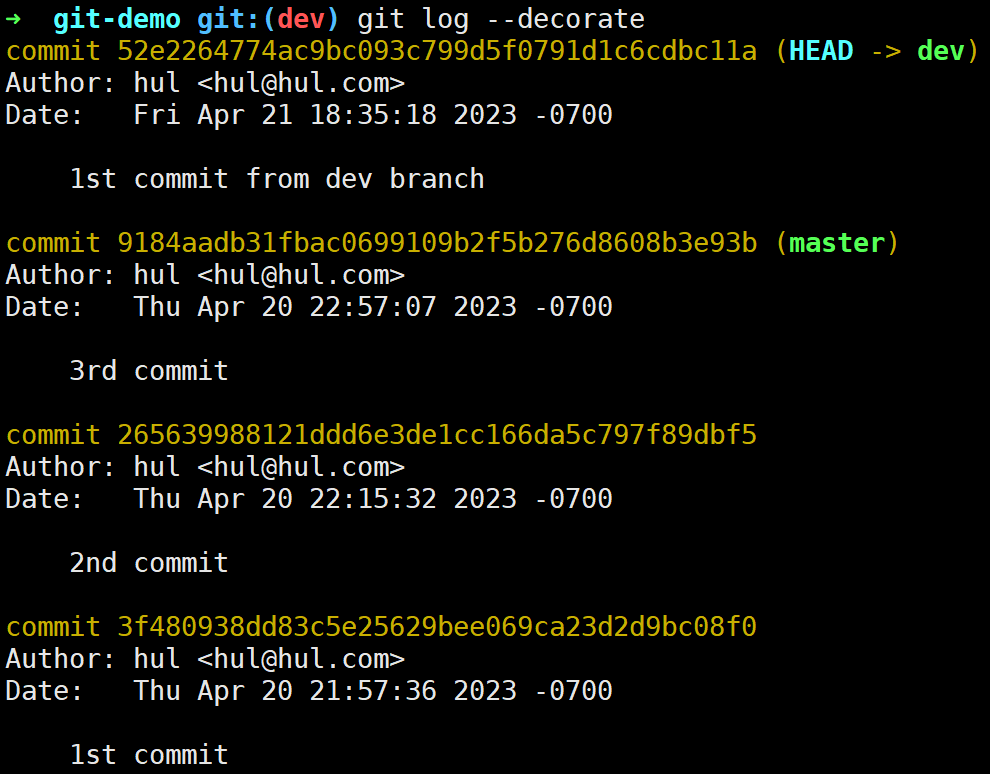
看完本地分支,我们再来看看远程分支,首先先创建一个远程仓库:
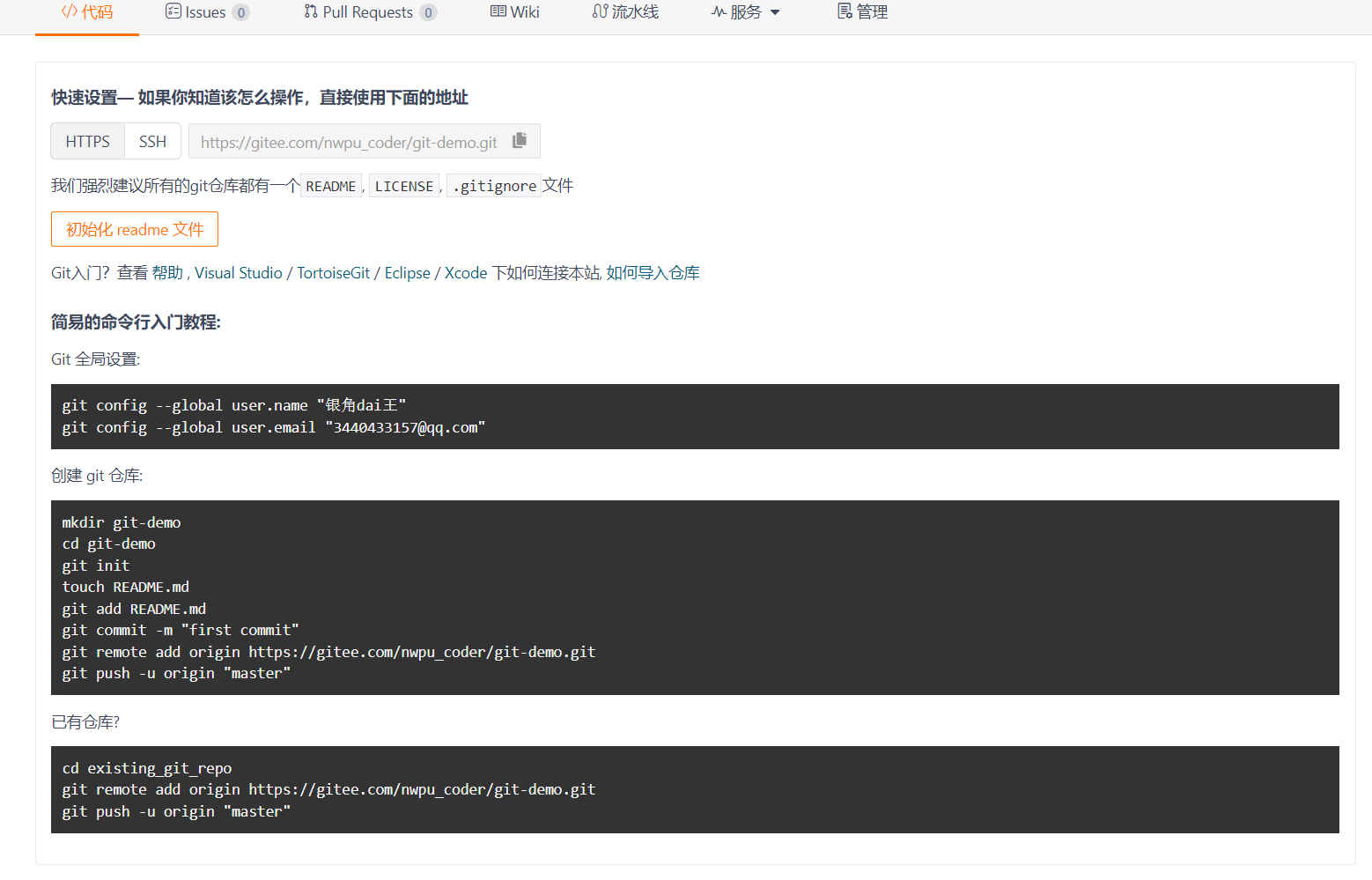
当我们添加一个远程分支后Git会帮我们记录远程仓库的信息:
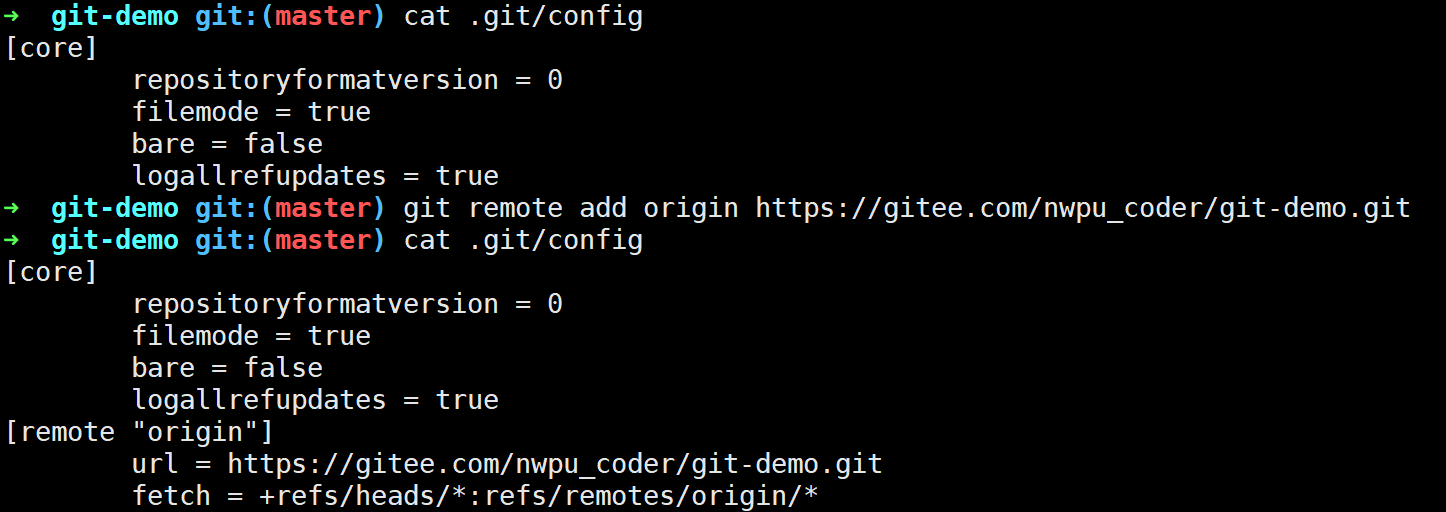
此时调用git push -u Git会帮我们创建远程分支引用:
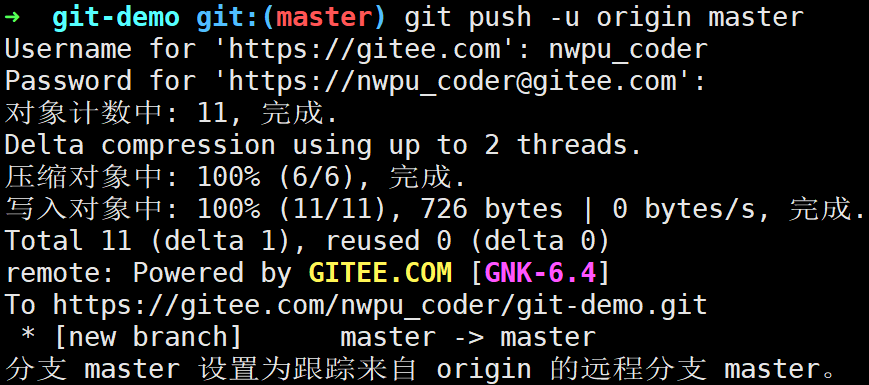
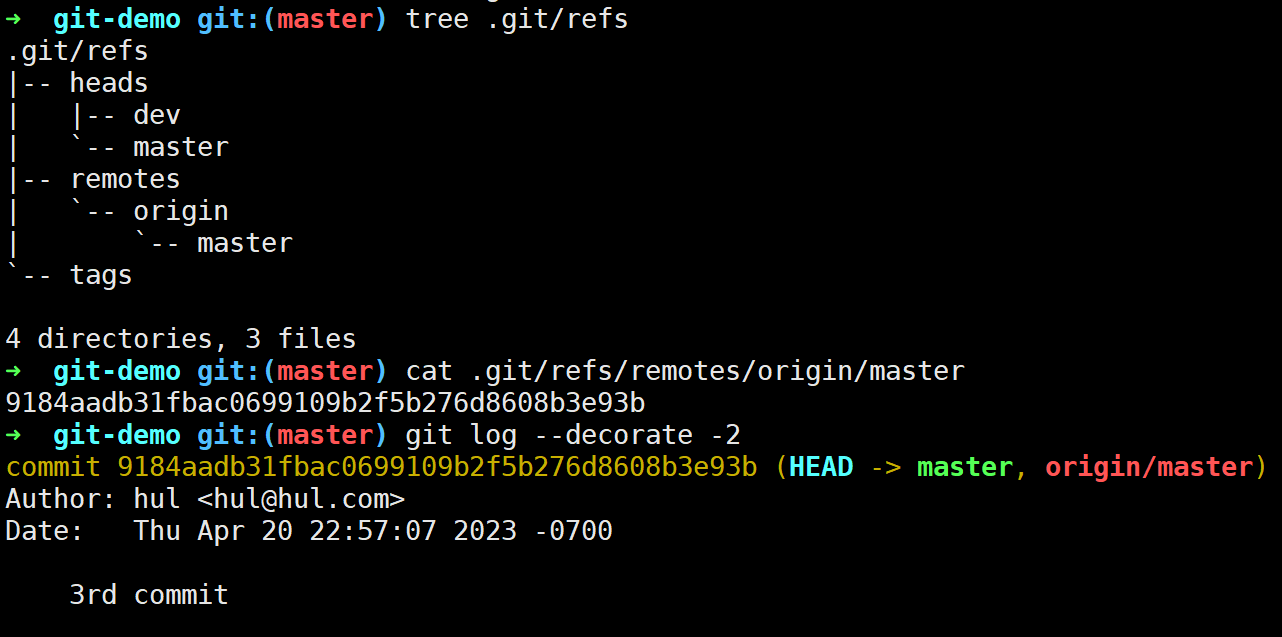
因为我们刚刚推送的本地仓库,因此此时远程仓库与本地仓库同步:
当我们每次git add把文件加入暂存区时其实对每个blob对象都进行了压缩,压缩效果视文件具体内容而言各有不同(高度重复的内容压缩效果很好,压缩只能针对文本文件,二进制文件不能压缩)。
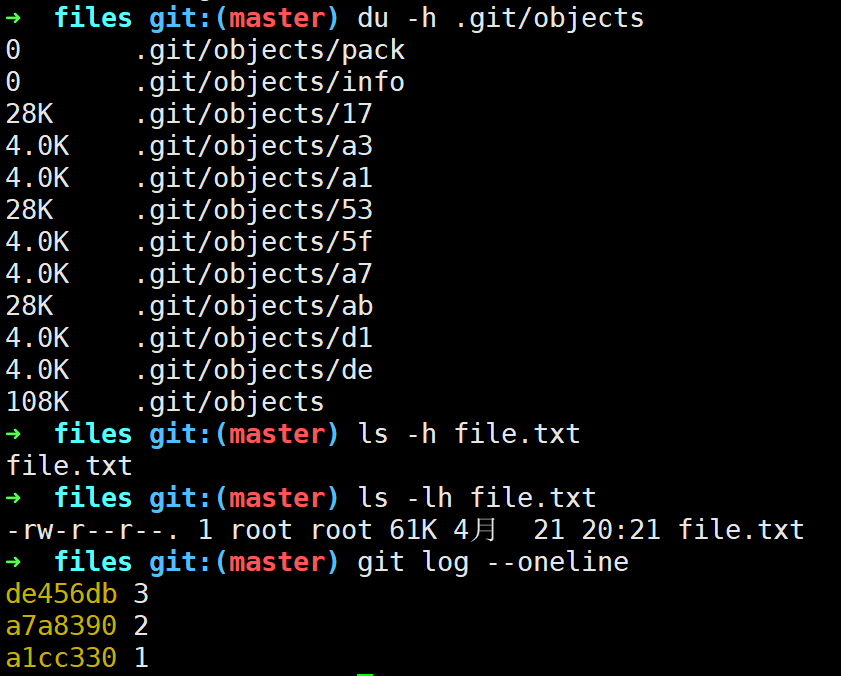
可以看出,虽然我们每次只是修改了file.txt的一点内容,但是每次都会生成一个最新的文件快照的压缩blob对象,当我们调用git gc后Git会帮我们优化内容存储:
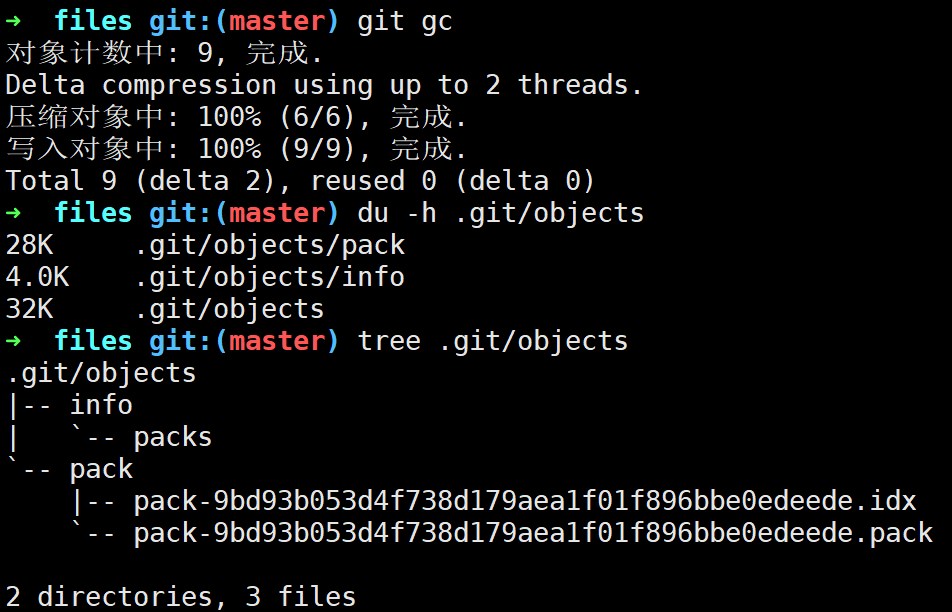
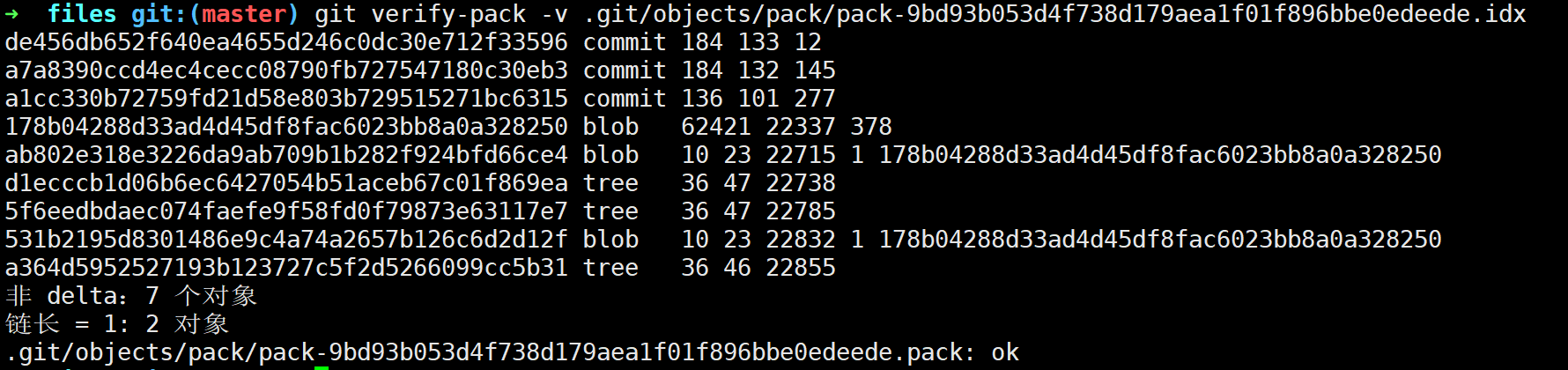
总共三次提交,每次提交都是创建一个blob、一个tree、一个commit,Git会把最新的
blob对象作为基对象,计算前两个blob对象的差异内容(补丁)
下面我们来看一下Git分支的合并场景,最简单的一种便是fast forward
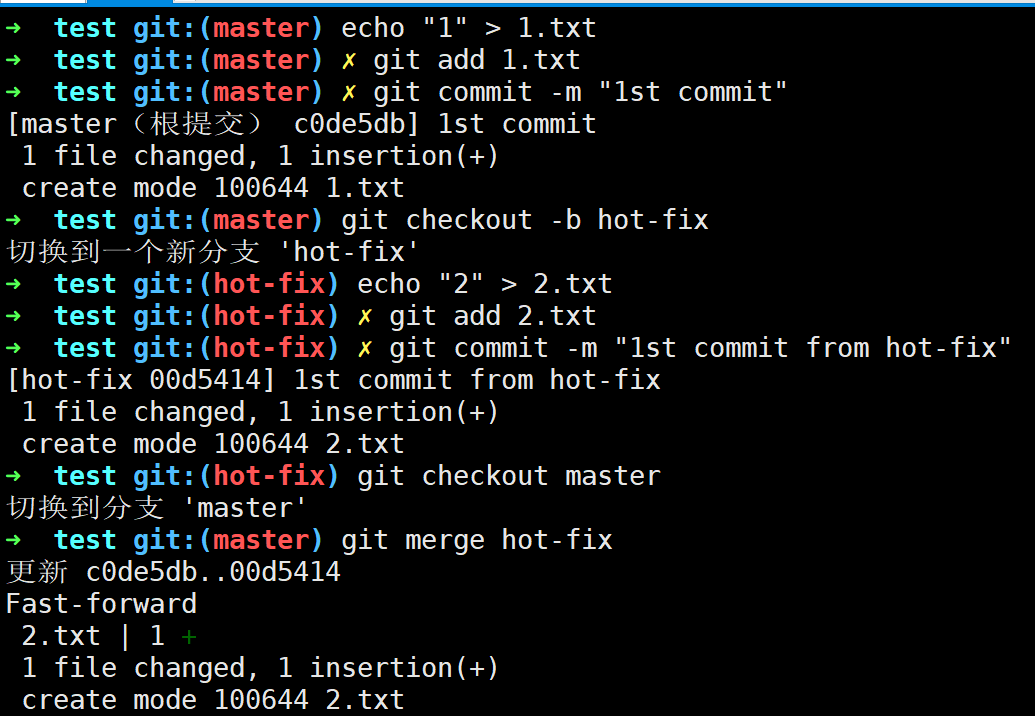
可以看出,master指针向前移动到前一个hot-fix分支,此时两者指向同一个commit
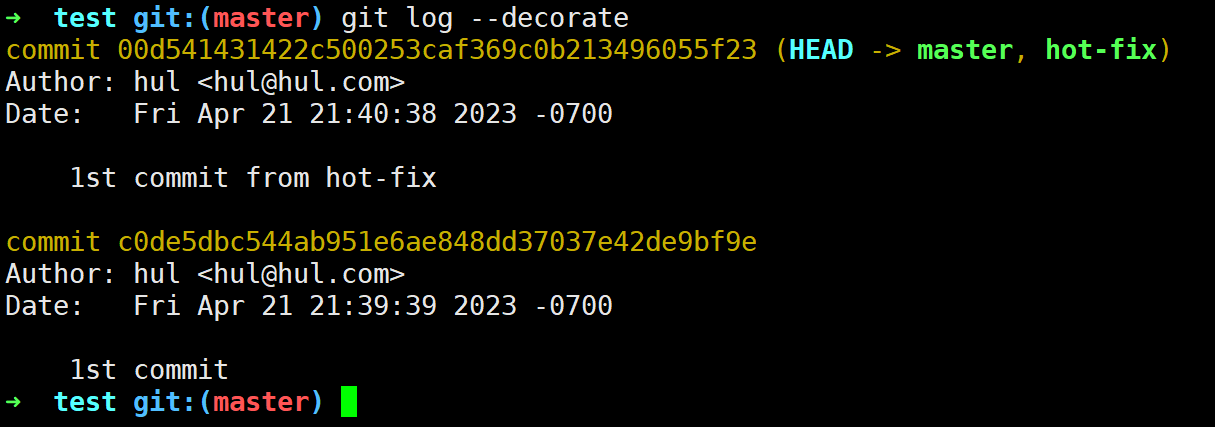
看完了简单的fast forward的分支合并,下面我们看一个复杂一些的3 way merge的合并场景:
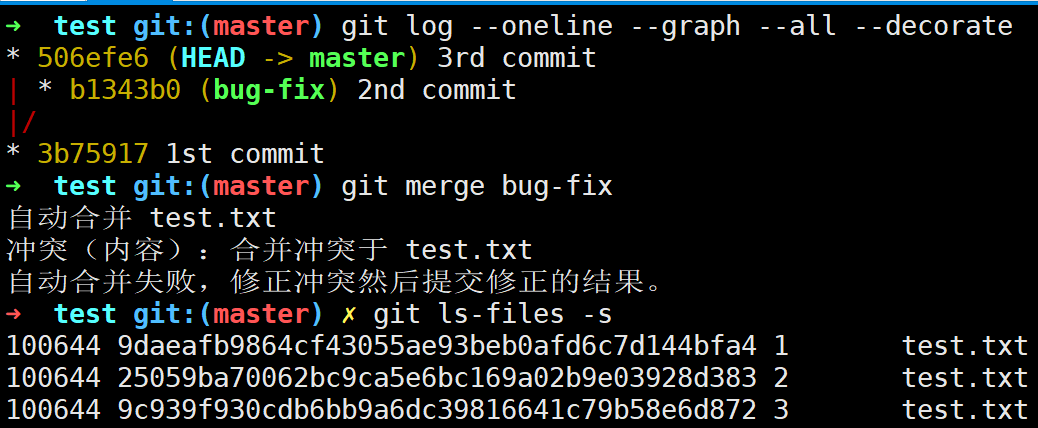
master分支与bug-fix分支发生了合并冲突,此时暂存区里面存放了test.txt的三个版本(这三个版本正是冲突文件test.txt在master提交点和bug-fix提交点以及它俩的公共祖先提交点的三个不同版本)
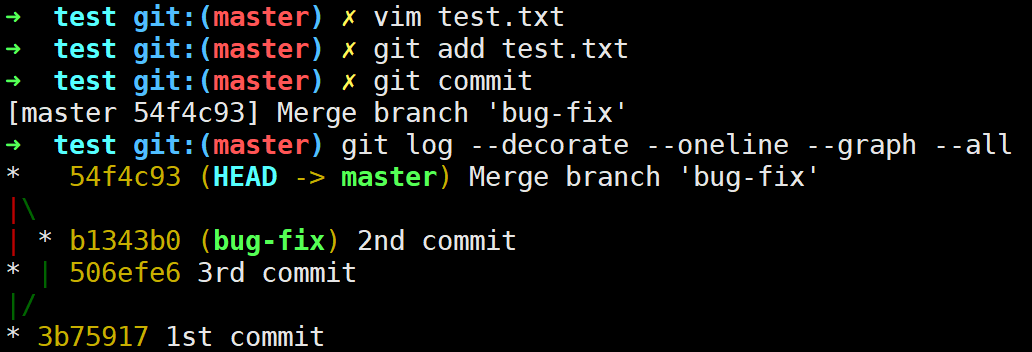
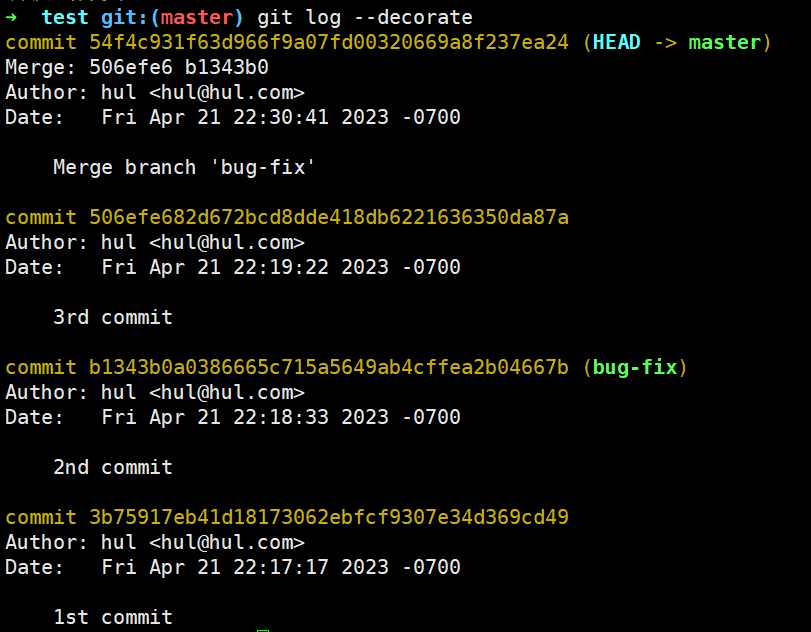
查看历史记录和master最新的commit的内容,其父commit有两个:
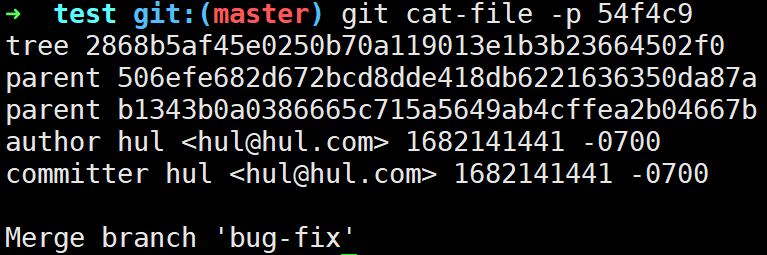
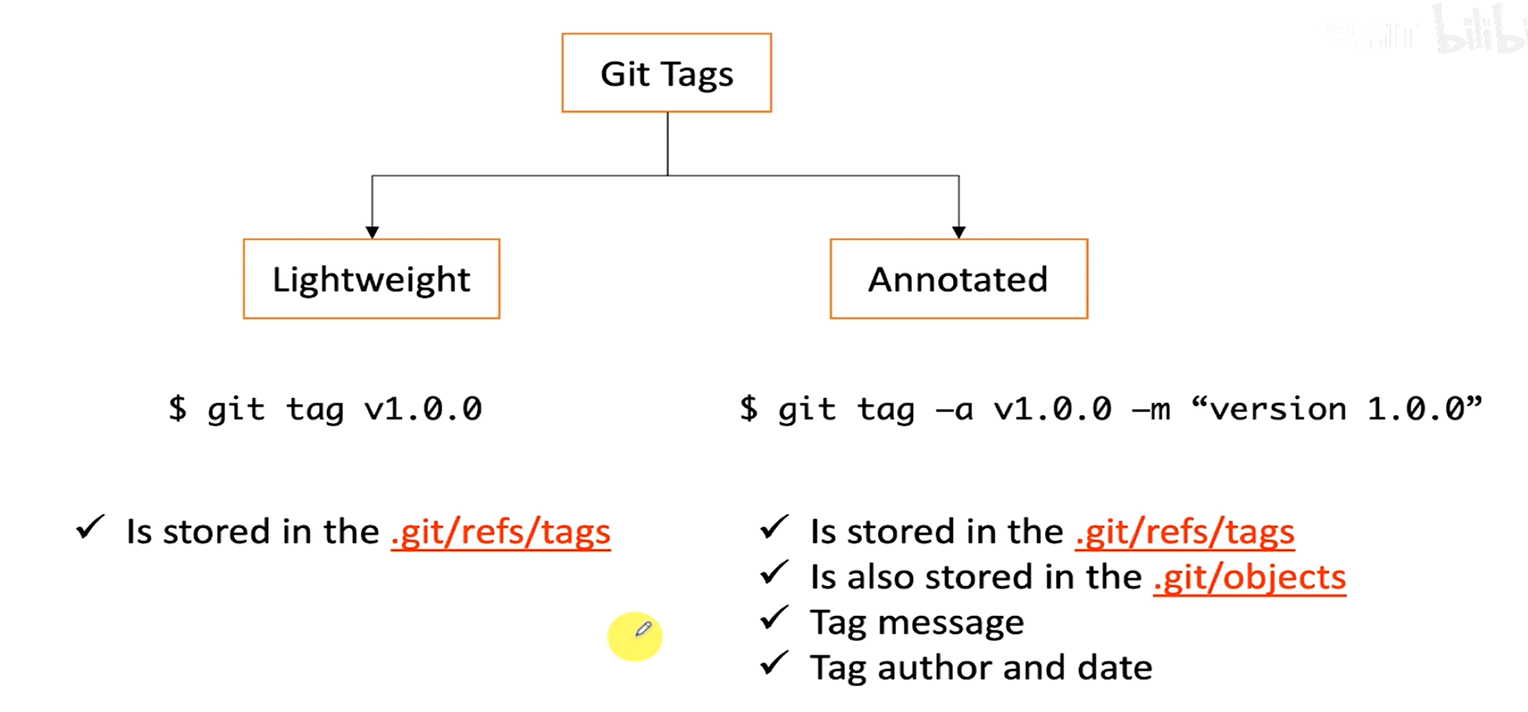
接下来我们来看看标签到底是什么,Git里面的标签主要分为两类,即轻量标签、附注标签,我们一一比较查看:
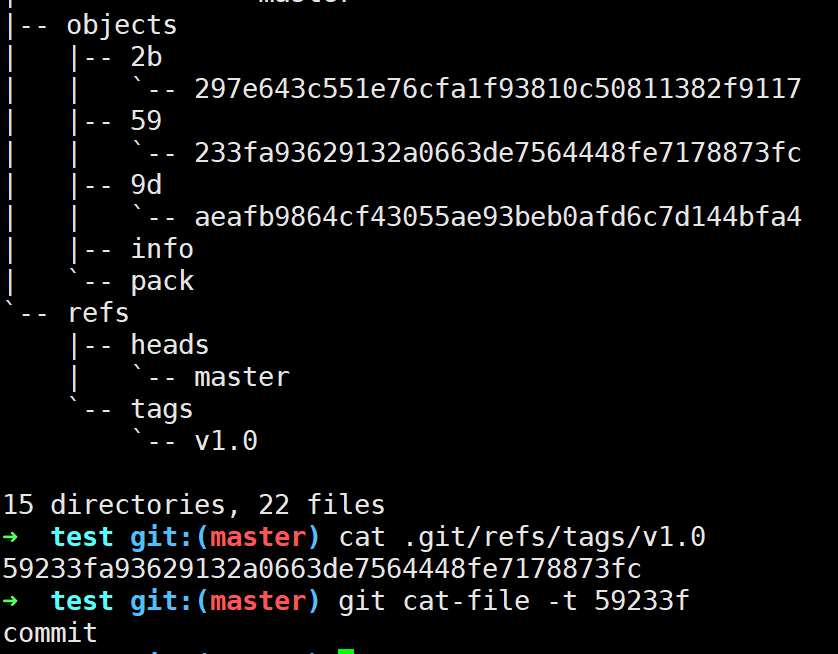
初始时刻我们只有一次提交,现在我们给当前commit打标签即git tag v1.0

此时可以发现,Git帮我们创建了一个tag文件,其指向当前的最新提交:
我们删除该轻量标签后创建一个附注标签对比一下有什么不同:

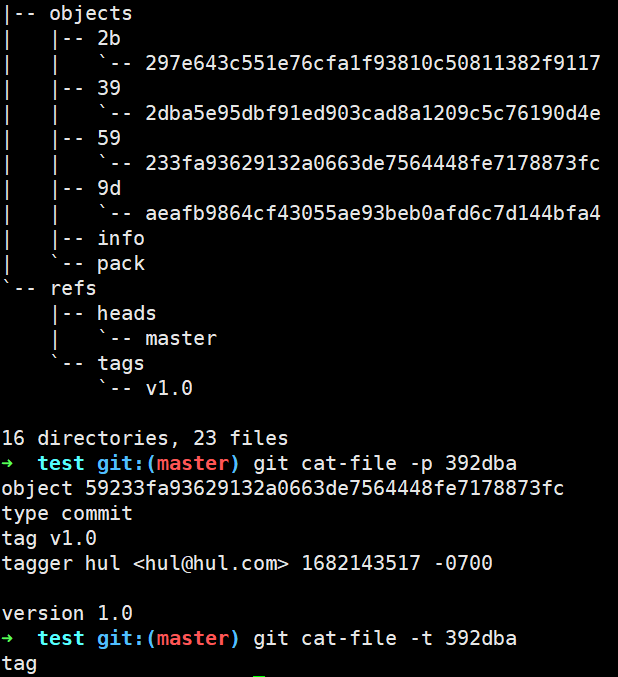
可以看出,附注标签在objects目录下创建了一个tag对象(指向最新的commit)
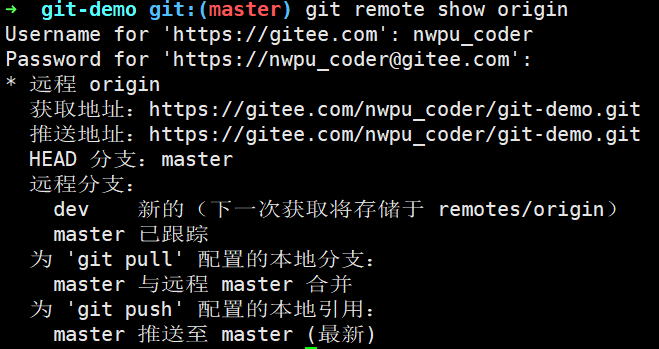
下面我们来看一下Git中的git fetch和git pull命令的区别吧!
首先我们clone 一下远程仓库git-demo,查看当前分支的情况:

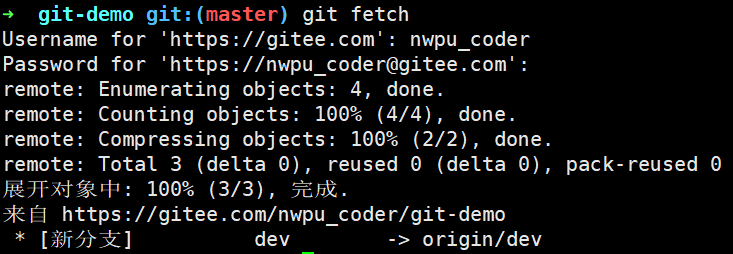
我们在远程仓库服务器中增加一个dev分支,然后添加一个file3.txt:
当我们调用git fetch后,Git会自动下载dev分支新增的三个对象(blob、tree、commit对象),并在本地新增三个文件FETCH_HEAD、refs/remotes/origin/dev、logs/refs/remotes/origin/dev。
其中FETCH_HEAD第一行存储着合并时的分支信息,refs/remotes/origin/dev存储着dev分支的最新提交信息。
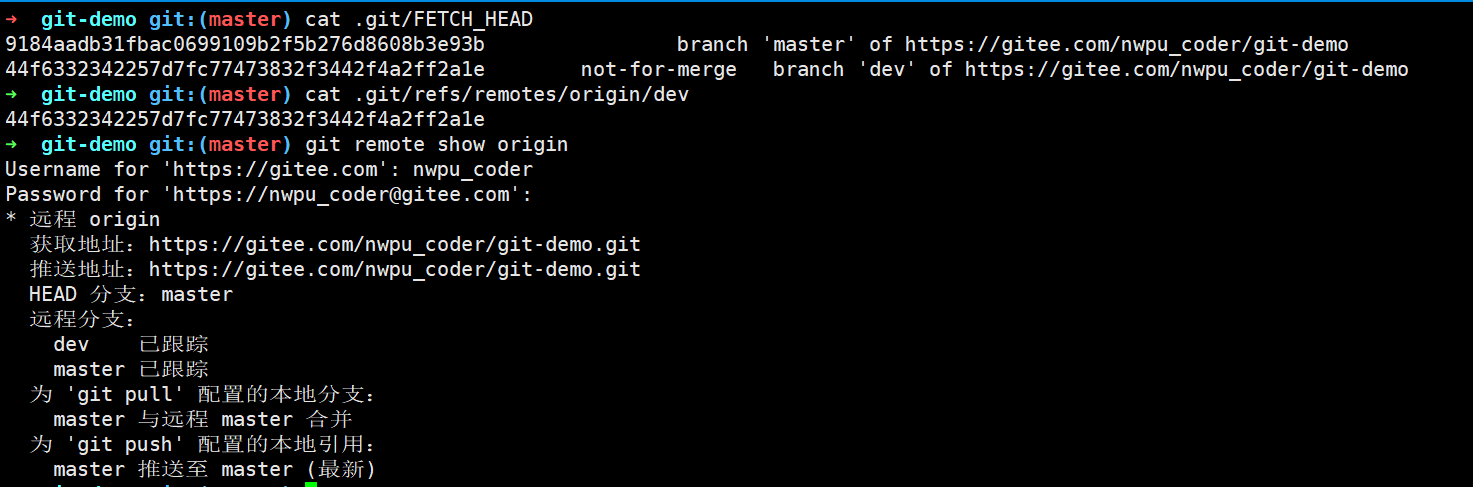
此时当使用git checkout dev后默认创建本地dev分支并自动跟追远程origin/dev分支:
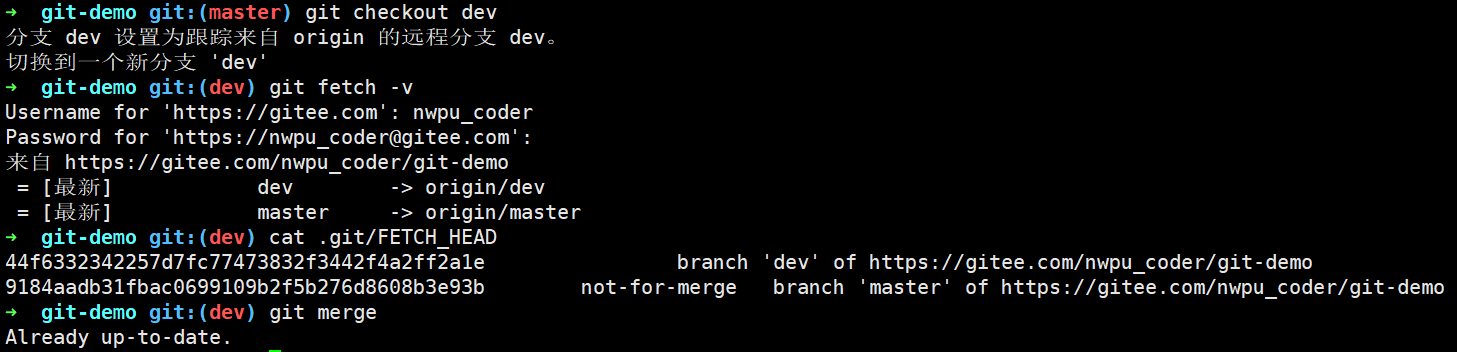
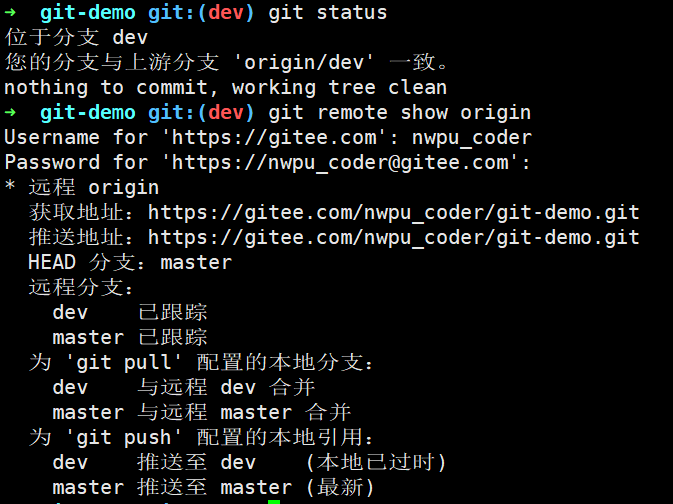
git pull相当于git fetch与git merge的合体,为了演示我们在dev分支再次创建一次新提交,此时使用git remote show origin查看远程信息发现本地dev分支已过时即落后于远程dev分支:
当我们在dev分支上调用git pull拉取远程代码并合并后,远程origin/dev分支指针后移(从原来的44f6332到更新后的524c9cd),并且本地dev分支合并其跟追的上游分支origin/dev(由于是线性更新,合并策略采用fast forward)
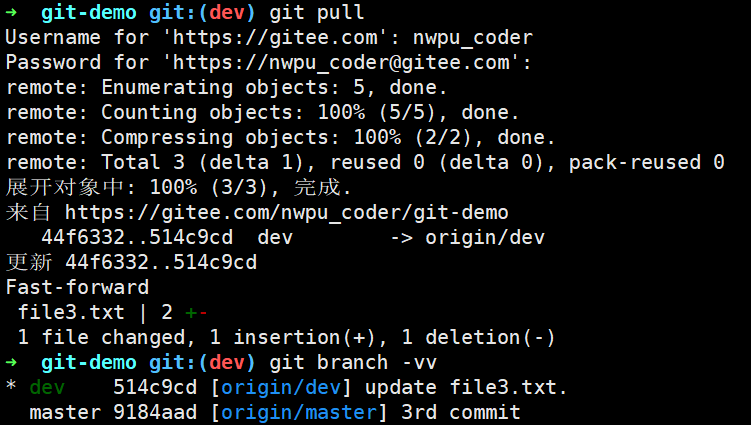
并且此时后多出一个ORIG_HEAD文件,存储着当前分支dev的未合并前的版本信息方便回滚。
